 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanditCAT and AutoIRT: Machine Learning Approaches to Computerized Adaptive Testing and Item Calibration
Oct 28, 2024

In this paper, we present a complete framework for quickly calibrating and administering a robust large-scale computerized adaptive test (CAT) with a small number of responses. Calibration - learning item parameters in a test - is done using AutoIRT, a new method that uses automated machine learning (AutoML) in combination with item response theory (IRT), originally proposed in [Sharpnack et al., 2024]. AutoIRT trains a non-parametric AutoML grading model using item features, followed by an item-specific parametric model, which results in an explanatory IRT model. In our work, we use tabular AutoML tools (AutoGluon.tabular, [Erickson et al., 2020]) along with BERT embeddings and linguistically motivated NLP features. In this framework, we use Bayesian updating to obtain test taker ability posterior distributions for administration and scoring. For administration of our adaptive test, we propose the BanditCAT framework, a methodology motivated by casting the problem in the contextual bandit framework and utilizing item response theory (IRT). The key insight lies in defining the bandit reward as the Fisher information for the selected item, given the latent test taker ability from IRT assumptions. We use Thompson sampling to balance between exploring items with different psychometric characteristics and selecting highly discriminative items that give more precise information about ability. To control item exposure, we inject noise through an additional randomization step before computing the Fisher information. This framework was used to initially launch two new item types on the DET practice test using limited training data. We outline some reliability and exposure metrics for the 5 practice test experiments that utilized this framework.
AutoIRT: Calibrating Item Response Theory Models with Automated Machine Learning
Sep 13, 2024



Item response theory (IRT) is a class of interpretable factor models that are widely used in computerized adaptive tests (CATs), such as language proficiency tests. Traditionally, these are fit using parametric mixed effects models on the probability of a test taker getting the correct answer to a test item (i.e., question). Neural net extensions of these models, such as BertIRT, require specialized architectures and parameter tuning. We propose a multistage fitting procedure that is compatible with out-of-the-box Automated Machine Learning (AutoML) tools. It is based on a Monte Carlo EM (MCEM) outer loop with a two stage inner loop, which trains a non-parametric AutoML grade model using item features followed by an item specific parametric model. This greatly accelerates the modeling workflow for scoring tests. We demonstrate its effectiveness by applying it to the Duolingo English Test, a high stakes, online English proficiency test. We show that the resulting model is typically more well calibrated, gets better predictive performance, and more accurate scores than existing methods (non-explanatory IRT models and explanatory IRT models like BERT-IRT). Along the way, we provide a brief survey of machine learning methods for calibration of item parameters for CATs.
Grounded Compositional Outputs for Adaptive Language Modeling
Oct 05, 2020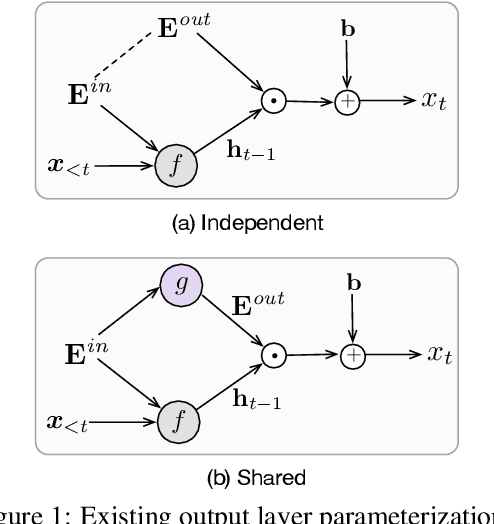

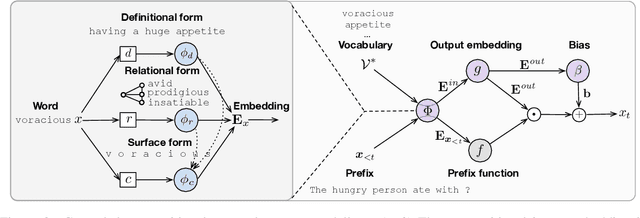
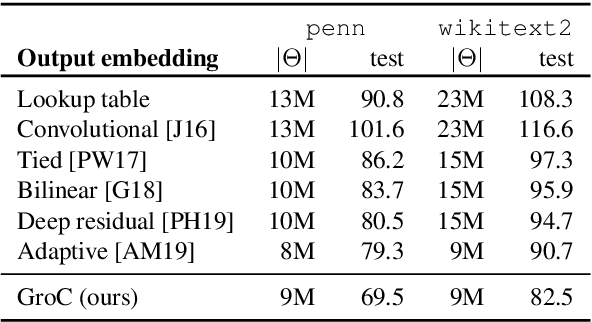
Language models have emerged as a central component across NLP, and a great deal of progress depends on the ability to cheaply adapt them (e.g., through finetuning) to new domains and tasks. A language model's vocabulary$-$typically selected before training and permanently fixed later$-$affects its size and is part of what makes it resistant to such adaptation. Prior work has used compositional input embeddings based on surface forms to ameliorate this issue. In this work, we go one step beyond and propose a fully compositional output embedding layer for language models, which is further grounded in information from a structured lexicon (WordNet), namely semantically related words and free-text definitions. To our knowledge, the result is the first word-level language model with a size that does not depend on the training vocabulary. We evaluate the model on conventional language modeling as well as challenging cross-domain settings with an open vocabulary, finding that it matches or outperforms previous state-of-the-art output embedding methods and adaptation approaches. Our analysis attributes the improvements to sample efficiency: our model is more accurate for low-frequency words.
Evaluating NLP Models via Contrast Sets
Apr 06, 2020
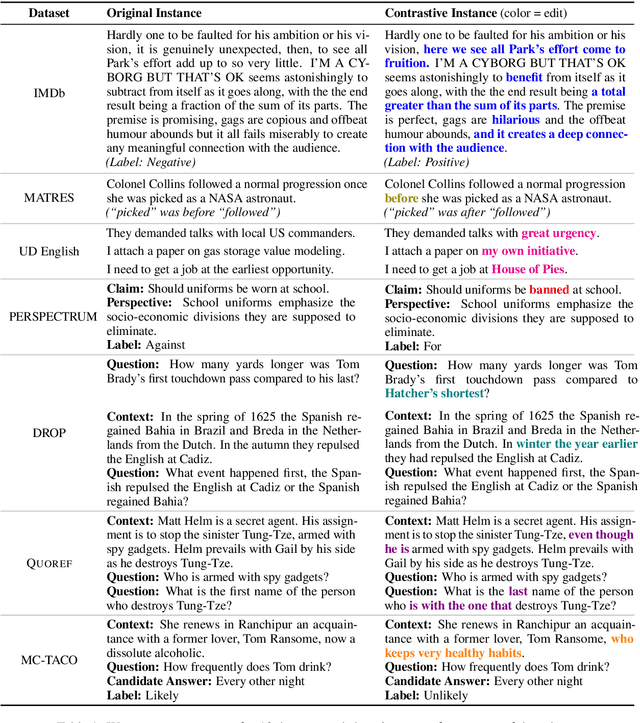
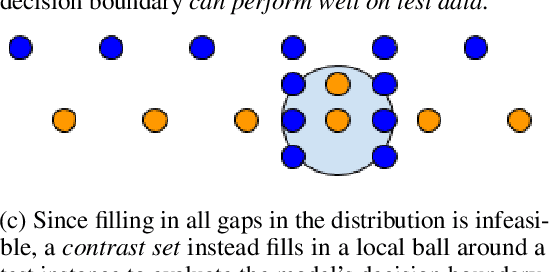
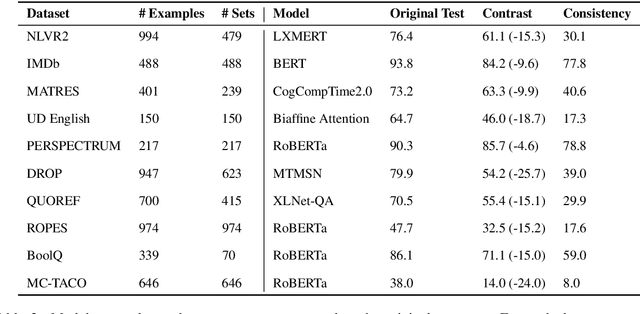
Standard test sets for supervised learning evaluate in-distribution generalization. Unfortunately, when a dataset has systematic gaps (e.g., annotation artifacts), these evaluations are misleading: a model can learn simple decision rules that perform well on the test set but do not capture a dataset's intended capabilities. We propose a new annotation paradigm for NLP that helps to close systematic gaps in the test data. In particular, after a dataset is constructed, we recommend that the dataset authors manually perturb the test instances in small but meaningful ways that (typically) change the gold label, creating contrast sets. Contrast sets provide a local view of a model's decision boundary, which can be used to more accurately evaluate a model's true linguistic capabilities. We demonstrate the efficacy of contrast sets by creating them for 10 diverse NLP datasets (e.g., DROP reading comprehension, UD parsing, IMDb sentiment analysis). Although our contrast sets are not explicitly adversarial, model performance is significantly lower on them than on the original test sets---up to 25\% in some cases. We release our contrast sets as new evaluation benchmarks and encourage future dataset construction efforts to follow similar annotation processes.
Low-Resource Parsing with Crosslingual Contextualized Representations
Sep 19, 2019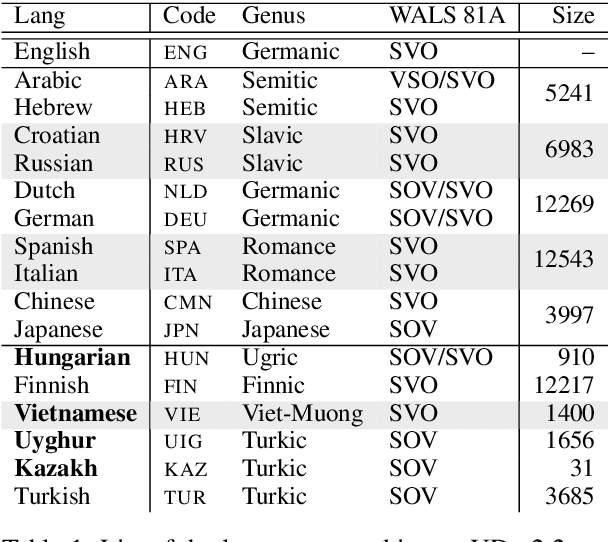
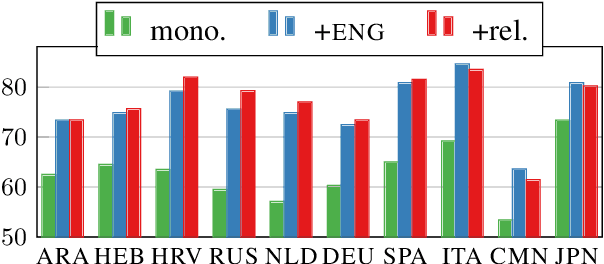

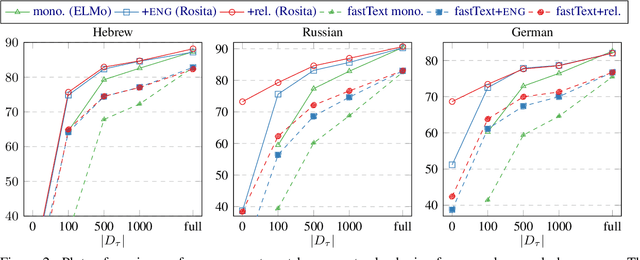
Despite advances in dependency parsing, languages with small treebanks still present challenges. We assess recent approaches to multilingual contextual word representations (CWRs), and compare them for crosslingual transfer from a language with a large treebank to a language with a small or nonexistent treebank, by sharing parameters between languages in the parser itself. We experiment with a diverse selection of languages in both simulated and truly low-resource scenarios, and show that multilingual CWRs greatly facilitate low-resource dependency parsing even without crosslingual supervision such as dictionaries or parallel text. Furthermore, we examine the non-contextual part of the learned language models (which we call a "decontextual probe") to demonstrate that polyglot language models better encode crosslingual lexical correspondence compared to aligned monolingual language models. This analysis provides further evidence that polyglot training is an effective approach to crosslingual transfer.
Polyglot Contextual Representations Improve Crosslingual Transfer
Mar 18, 2019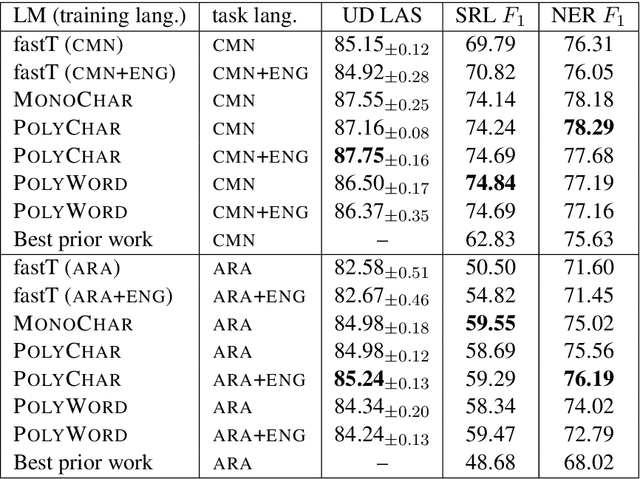
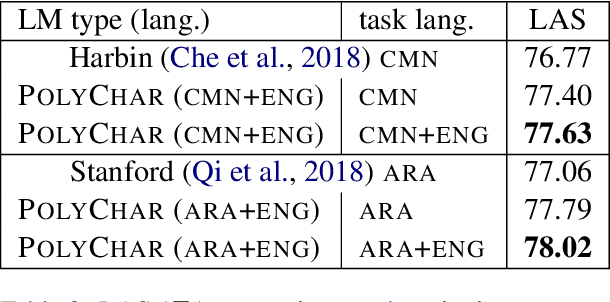
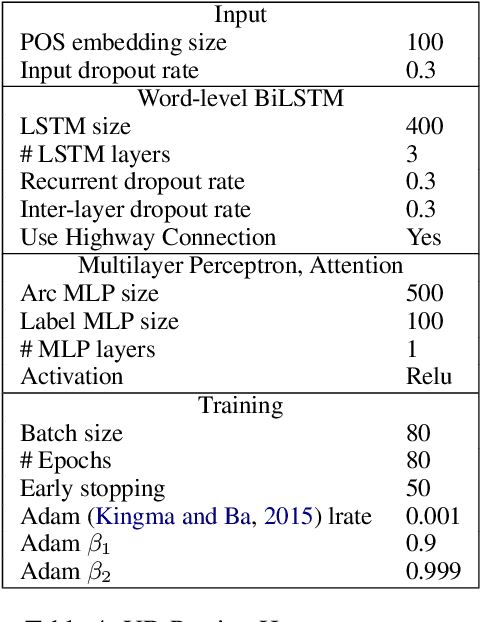
We introduce Rosita, a method to produce multilingual contextual word representations by training a single language model on text from multiple languages. Our method combines the advantages of contextual word representations with those of multilingual representation learning. We produce language models from dissimilar language pairs (English/Arabic and English/Chinese) and use them in dependency parsing, semantic role labeling, and named entity recognition, with comparisons to monolingual and non-contextual variants. Our results provide further evidence for the benefits of polyglot learning, in which representations are shared across multiple languages.
Polyglot Semantic Role Labeling
May 29, 2018
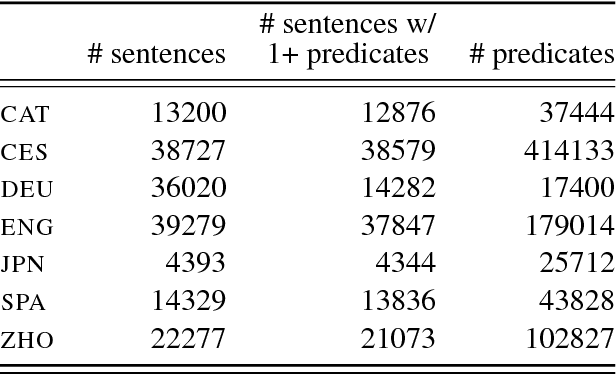
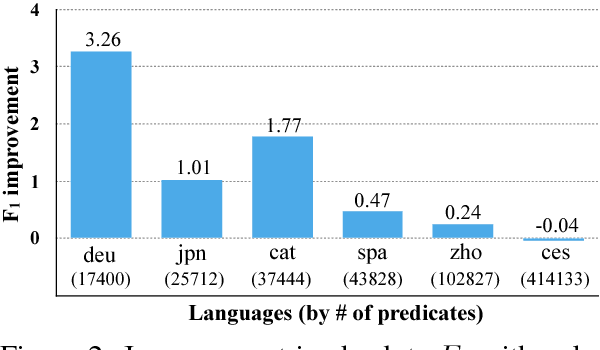
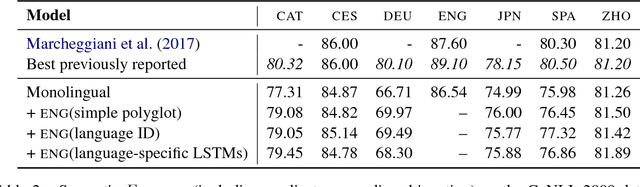
Previous approaches to multilingual semantic dependency parsing treat languages independently, without exploiting the similarities between semantic structures across languages. We experiment with a new approach where we combine resources from a pair of languages in the CoNLL 2009 shared task to build a polyglot semantic role labeler. Notwithstanding the absence of parallel data, and the dissimilarity in annotations between languages, our approach results in an improvement in SRL performance on multiple languages over a monolingual baseline. Analysis of the polyglot model shows it to be advantageous in lower-resource settings.