 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe BEA 2023 Shared Task on Generating AI Teacher Responses in Educational Dialogues
Jun 12, 2023This paper describes the results of the first shared task on the generation of teacher responses in educational dialogues. The goal of the task was to benchmark the ability of generative language models to act as AI teachers, replying to a student in a teacher-student dialogue. Eight teams participated in the competition hosted on CodaLab. They experimented with a wide variety of state-of-the-art models, including Alpaca, Bloom, DialoGPT, DistilGPT-2, Flan-T5, GPT-2, GPT-3, GPT- 4, LLaMA, OPT-2.7B, and T5-base. Their submissions were automatically scored using BERTScore and DialogRPT metrics, and the top three among them were further manually evaluated in terms of pedagogical ability based on Tack and Piech (2022). The NAISTeacher system, which ranked first in both automated and human evaluation, generated responses with GPT-3.5 using an ensemble of prompts and a DialogRPT-based ranking of responses for given dialogue contexts. Despite the promising achievements of the participating teams, the results also highlight the need for evaluation metrics better suited to educational contexts.
Not All Dialogues are Created Equal: Instance Weighting for Neural Conversational Models
Jul 15, 2017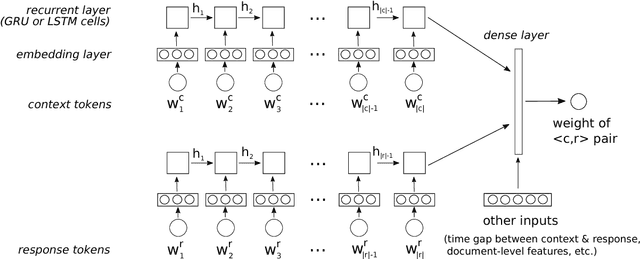

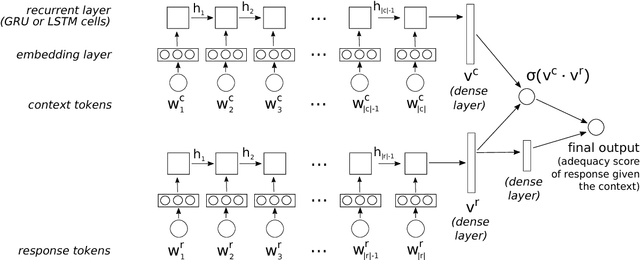
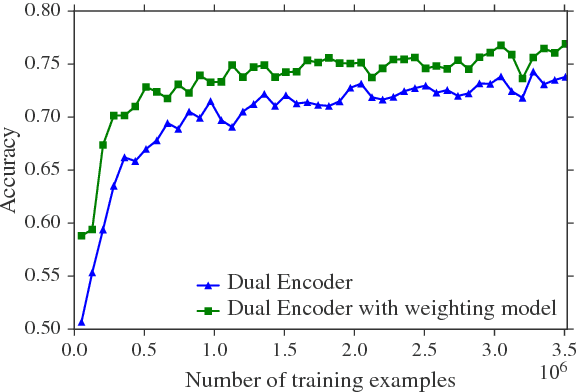
Neural conversational models require substantial amounts of dialogue data for their parameter estimation and are therefore usually learned on large corpora such as chat forums or movie subtitles. These corpora are, however, often challenging to work with, notably due to their frequent lack of turn segmentation and the presence of multiple references external to the dialogue itself. This paper shows that these challenges can be mitigated by adding a weighting model into the architecture. The weighting model, which is itself estimated from dialogue data, associates each training example to a numerical weight that reflects its intrinsic quality for dialogue modelling. At training time, these sample weights are included into the empirical loss to be minimised. Evaluation results on retrieval-based models trained on movie and TV subtitles demonstrate that the inclusion of such a weighting model improves the model performance on unsupervised metrics.