 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboCrowd: Scaling Robot Data Collection through Crowdsourcing
Nov 04, 2024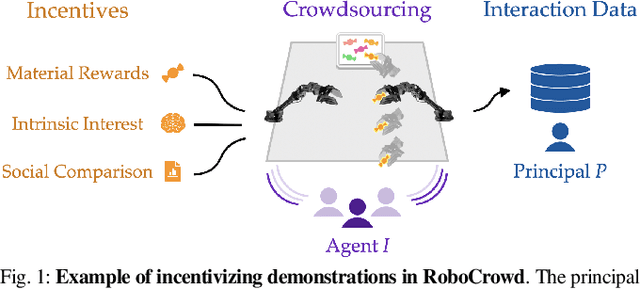
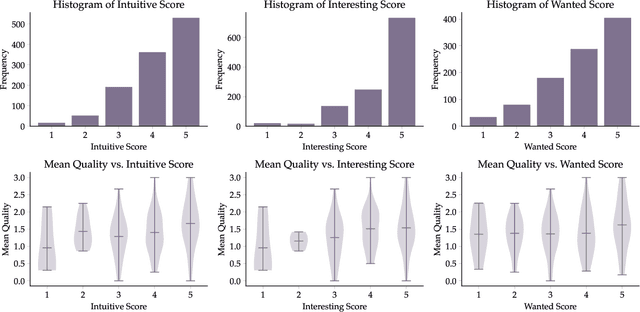
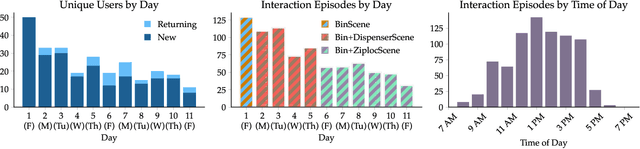
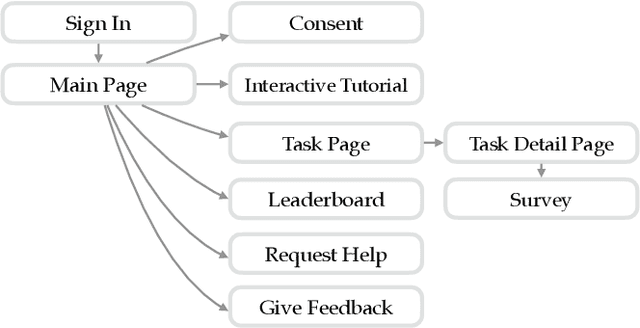
In recent years, imitation learning from large-scale human demonstrations has emerged as a promising paradigm for training robot policies. However, the burden of collecting large quantities of human demonstrations is significant in terms of collection time and the need for access to expert operators. We introduce a new data collection paradigm, RoboCrowd, which distributes the workload by utilizing crowdsourcing principles and incentive design. RoboCrowd helps enable scalable data collection and facilitates more efficient learning of robot policies. We build RoboCrowd on top of ALOHA (Zhao et al. 2023) -- a bimanual platform that supports data collection via puppeteering -- to explore the design space for crowdsourcing in-person demonstrations in a public environment. We propose three classes of incentive mechanisms to appeal to users' varying sources of motivation for interacting with the system: material rewards, intrinsic interest, and social comparison. We instantiate these incentives through tasks that include physical rewards, engaging or challenging manipulations, as well as gamification elements such as a leaderboard. We conduct a large-scale, two-week field experiment in which the platform is situated in a university cafe. We observe significant engagement with the system -- over 200 individuals independently volunteered to provide a total of over 800 interaction episodes. Our findings validate the proposed incentives as mechanisms for shaping users' data quantity and quality. Further, we demonstrate that the crowdsourced data can serve as useful pre-training data for policies fine-tuned on expert demonstrations -- boosting performance up to 20% compared to when this data is not available. These results suggest the potential for RoboCrowd to reduce the burden of robot data collection by carefully implementing crowdsourcing and incentive design principles.
So You Think You Can Scale Up Autonomous Robot Data Collection?
Nov 04, 2024A long-standing goal in robot learning is to develop methods for robots to acquire new skills autonomously. While reinforcement learning (RL) comes with the promise of enabling autonomous data collection, it remains challenging to scale in the real-world partly due to the significant effort required for environment design and instrumentation, including the need for designing reset functions or accurate success detectors. On the other hand, imitation learning (IL) methods require little to no environment design effort, but instead require significant human supervision in the form of collected demonstrations. To address these shortcomings, recent works in autonomous IL start with an initial seed dataset of human demonstrations that an autonomous policy can bootstrap from. While autonomous IL approaches come with the promise of addressing the challenges of autonomous RL as well as pure IL strategies, in this work, we posit that such techniques do not deliver on this promise and are still unable to scale up autonomous data collection in the real world. Through a series of real-world experiments, we demonstrate that these approaches, when scaled up to realistic settings, face much of the same scaling challenges as prior attempts in RL in terms of environment design. Further, we perform a rigorous study of autonomous IL methods across different data scales and 7 simulation and real-world tasks, and demonstrate that while autonomous data collection can modestly improve performance, simply collecting more human data often provides significantly more improvement. Our work suggests a negative result: that scaling up autonomous data collection for learning robot policies for real-world tasks is more challenging and impractical than what is suggested in prior work. We hope these insights about the core challenges of scaling up data collection help inform future efforts in autonomous learning.
Handwritten Code Recognition for Pen-and-Paper CS Education
Aug 07, 2024



Teaching Computer Science (CS) by having students write programs by hand on paper has key pedagogical advantages: It allows focused learning and requires careful thinking compared to the use of Integrated Development Environments (IDEs) with intelligent support tools or "just trying things out". The familiar environment of pens and paper also lessens the cognitive load of students with no prior experience with computers, for whom the mere basic usage of computers can be intimidating. Finally, this teaching approach opens learning opportunities to students with limited access to computers. However, a key obstacle is the current lack of teaching methods and support software for working with and running handwritten programs. Optical character recognition (OCR) of handwritten code is challenging: Minor OCR errors, perhaps due to varied handwriting styles, easily make code not run, and recognizing indentation is crucial for languages like Python but is difficult to do due to inconsistent horizontal spacing in handwriting. Our approach integrates two innovative methods. The first combines OCR with an indentation recognition module and a language model designed for post-OCR error correction without introducing hallucinations. This method, to our knowledge, surpasses all existing systems in handwritten code recognition. It reduces error from 30\% in the state of the art to 5\% with minimal hallucination of logical fixes to student programs. The second method leverages a multimodal language model to recognize handwritten programs in an end-to-end fashion. We hope this contribution can stimulate further pedagogical research and contribute to the goal of making CS education universally accessible. We release a dataset of handwritten programs and code to support future research at https://github.com/mdoumbouya/codeocr