 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Batch Correction for Cell Painting via Batch-Dependent Kernels and Adaptive Sampling
Jan 29, 2026Cell Painting is a microscopy-based, high-content imaging assay that produces rich morphological profiles of cells and can support drug discovery by quantifying cellular responses to chemical perturbations. At scale, however, Cell Painting data is strongly affected by batch effects arising from differences in laboratories, instruments, and protocols, which can obscure biological signal. We present BALANS (Batch Alignment via Local Affinities and Subsampling), a scalable batch-correction method that aligns samples across batches by constructing a smoothed affinity matrix from pairwise distances. Given $n$ data points, BALANS builds a sparse affinity matrix $A \in \mathbb{R}^{n \times n}$ using two ideas. (i) For points $i$ and $j$, it sets a local scale using the distance from $i$ to its $k$-th nearest neighbor within the batch of $j$, then computes $A_{ij}$ via a Gaussian kernel calibrated by these batch-aware local scales. (ii) Rather than forming all $n^2$ entries, BALANS uses an adaptive sampling procedure that prioritizes rows with low cumulative neighbor coverage and retains only the strongest affinities per row, yielding a sparse but informative approximation of $A$. We prove that this sampling strategy is order-optimal in sample complexity and provides an approximation guarantee, and we show that BALANS runs in nearly linear time in $n$. Experiments on diverse real-world Cell Painting datasets and controlled large-scale synthetic benchmarks demonstrate that BALANS scales to large collections while improving runtime over native implementations of widely used batch-correction methods, without sacrificing correction quality.
Dynamic DBSCAN with Euler Tour Sequences
Mar 11, 2025
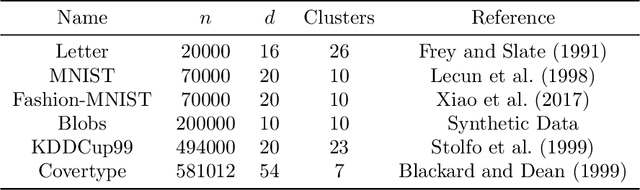
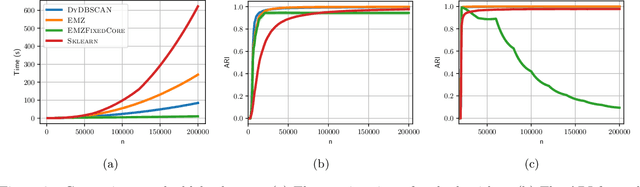
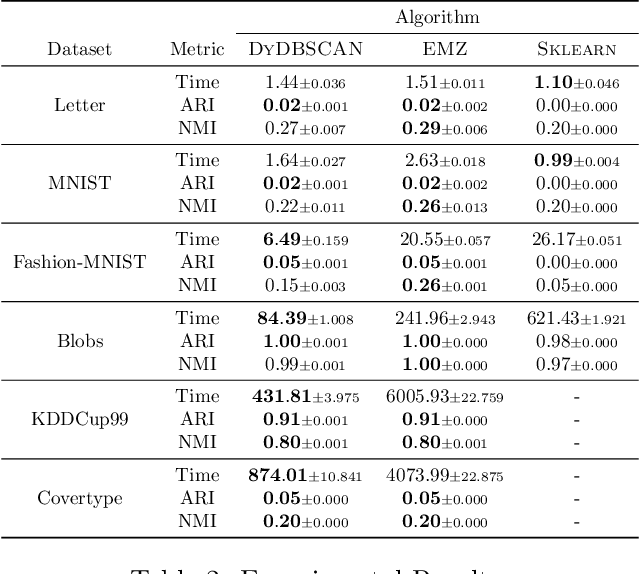
We propose a fast and dynamic algorithm for Density-Based Spatial Clustering of Applications with Noise (DBSCAN) that efficiently supports online updates. Traditional DBSCAN algorithms, designed for batch processing, become computationally expensive when applied to dynamic datasets, particularly in large-scale applications where data continuously evolves. To address this challenge, our algorithm leverages the Euler Tour Trees data structure, enabling dynamic clustering updates without the need to reprocess the entire dataset. This approach preserves a near-optimal accuracy in density estimation, as achieved by the state-of-the-art static DBSCAN method (Esfandiari et al., 2021) Our method achieves an improved time complexity of $O(d \log^3(n) + \log^4(n))$ for every data point insertion and deletion, where $n$ and $d$ denote the total number of updates and the data dimension, respectively. Empirical studies also demonstrate significant speedups over conventional DBSCANs in real-time clustering of dynamic datasets, while maintaining comparable or superior clustering quality.
Capacity-Aware Planning and Scheduling in Budget-Constrained Monotonic MDPs: A Meta-RL Approach
Oct 28, 2024Many real-world sequential repair problems can be effectively modeled using monotonic Markov Decision Processes (MDPs), where the system state stochastically decreases and can only be increased by performing a restorative action. This work addresses the problem of solving multi-component monotonic MDPs with both budget and capacity constraints. The budget constraint limits the total number of restorative actions and the capacity constraint limits the number of restorative actions that can be performed simultaneously. While prior methods dealt with budget constraints, including capacity constraints in prior methods leads to an exponential increase in computational complexity as the number of components in the MDP grows. We propose a two-step planning approach to address this challenge. First, we partition the components of the multi-component MDP into groups, where the number of groups is determined by the capacity constraint. We achieve this partitioning by solving a Linear Sum Assignment Problem (LSAP). Each group is then allocated a fraction of the total budget proportional to its size. This partitioning effectively decouples the large multi-component MDP into smaller subproblems, which are computationally feasible because the capacity constraint is simplified and the budget constraint can be addressed using existing methods. Subsequently, we use a meta-trained PPO agent to obtain an approximately optimal policy for each group. To validate our approach, we apply it to the problem of scheduling repairs for a large group of industrial robots, constrained by a limited number of repair technicians and a total repair budget. Our results demonstrate that the proposed method outperforms baseline approaches in terms of maximizing the average uptime of the robot swarm, particularly for large swarm sizes.
BanditPAM++: Faster $k$-medoids Clustering
Oct 28, 2023


Clustering is a fundamental task in data science with wide-ranging applications. In $k$-medoids clustering, cluster centers must be actual datapoints and arbitrary distance metrics may be used; these features allow for greater interpretability of the cluster centers and the clustering of exotic objects in $k$-medoids clustering, respectively. $k$-medoids clustering has recently grown in popularity due to the discovery of more efficient $k$-medoids algorithms. In particular, recent research has proposed BanditPAM, a randomized $k$-medoids algorithm with state-of-the-art complexity and clustering accuracy. In this paper, we present BanditPAM++, which accelerates BanditPAM via two algorithmic improvements, and is $O(k)$ faster than BanditPAM in complexity and substantially faster than BanditPAM in wall-clock runtime. First, we demonstrate that BanditPAM has a special structure that allows the reuse of clustering information $\textit{within}$ each iteration. Second, we demonstrate that BanditPAM has additional structure that permits the reuse of information $\textit{across}$ different iterations. These observations inspire our proposed algorithm, BanditPAM++, which returns the same clustering solutions as BanditPAM but often several times faster. For example, on the CIFAR10 dataset, BanditPAM++ returns the same results as BanditPAM but runs over 10$\times$ faster. Finally, we provide a high-performance C++ implementation of BanditPAM++, callable from Python and R, that may be of interest to practitioners at https://github.com/motiwari/BanditPAM. Auxiliary code to reproduce all of our experiments via a one-line script is available at https://github.com/ThrunGroup/BanditPAM_plusplus_experiments.
Utilizing Free Clients in Federated Learning for Focused Model Enhancement
Oct 06, 2023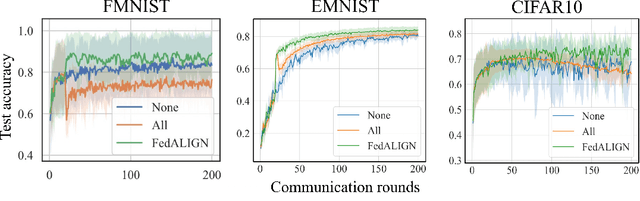
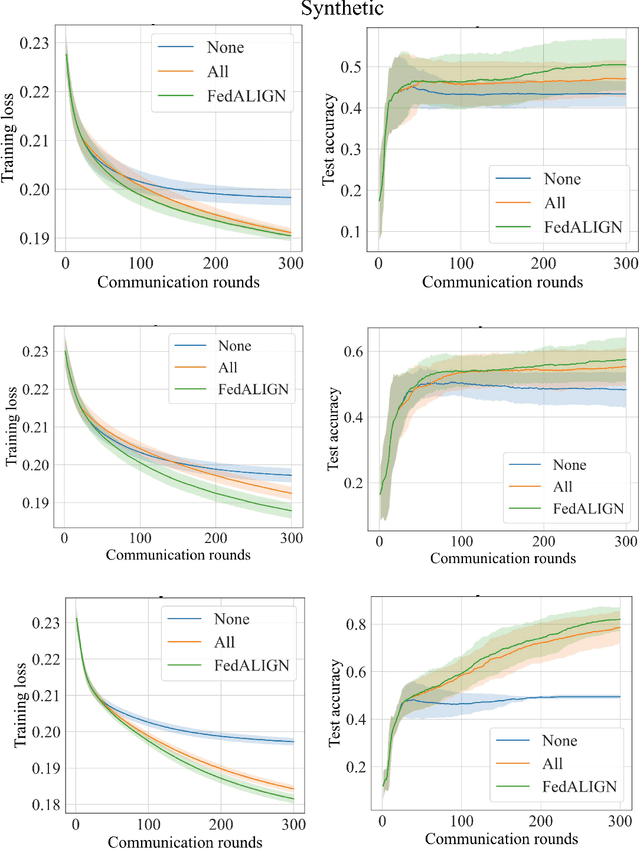
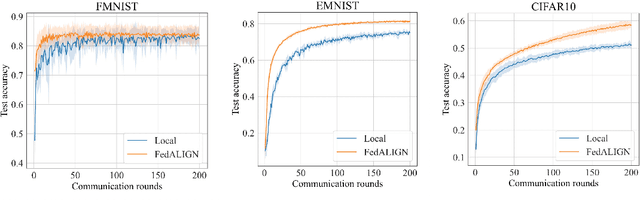
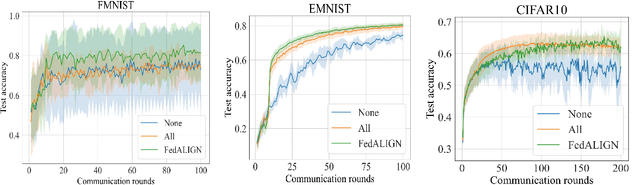
Federated Learning (FL) is a distributed machine learning approach to learn models on decentralized heterogeneous data, without the need for clients to share their data. Many existing FL approaches assume that all clients have equal importance and construct a global objective based on all clients. We consider a version of FL we call Prioritized FL, where the goal is to learn a weighted mean objective of a subset of clients, designated as priority clients. An important question arises: How do we choose and incentivize well aligned non priority clients to participate in the federation, while discarding misaligned clients? We present FedALIGN (Federated Adaptive Learning with Inclusion of Global Needs) to address this challenge. The algorithm employs a matching strategy that chooses non priority clients based on how similar the models loss is on their data compared to the global data, thereby ensuring the use of non priority client gradients only when it is beneficial for priority clients. This approach ensures mutual benefits as non priority clients are motivated to join when the model performs satisfactorily on their data, and priority clients can utilize their updates and computational resources when their goals align. We present a convergence analysis that quantifies the trade off between client selection and speed of convergence. Our algorithm shows faster convergence and higher test accuracy than baselines for various synthetic and benchmark datasets.
Faster Maximum Inner Product Search in High Dimensions
Dec 14, 2022Maximum Inner Product Search (MIPS) is a popular problem in the machine learning literature due to its applicability in a wide array of applications, such as recommender systems. In high-dimensional settings, however, MIPS queries can become computationally expensive as most existing solutions do not scale well with data dimensionality. In this work, we present a state-of-the-art algorithm for the MIPS problem in high dimensions, dubbed BanditMIPS. BanditMIPS is a randomized algorithm that borrows techniques from multi-armed bandits to reduce the MIPS problem to a best-arm identification problem. BanditMIPS reduces the complexity of state-of-the-art algorithms from $O(\sqrt{d})$ to $O(\text{log}d)$, where $d$ is the dimension of the problem data vectors. On high-dimensional real-world datasets, BanditMIPS runs approximately 12 times faster than existing approaches and returns the same solution. BanditMIPS requires no preprocessing of the data and includes a hyperparameter that practitioners may use to trade off accuracy and runtime. We also propose a variant of our algorithm, named BanditMIPS-$\alpha$, which employs non-uniform sampling across the data dimensions to provide further speedups.
MABSplit: Faster Forest Training Using Multi-Armed Bandits
Dec 14, 2022



Random forests are some of the most widely used machine learning models today, especially in domains that necessitate interpretability. We present an algorithm that accelerates the training of random forests and other popular tree-based learning methods. At the core of our algorithm is a novel node-splitting subroutine, dubbed MABSplit, used to efficiently find split points when constructing decision trees. Our algorithm borrows techniques from the multi-armed bandit literature to judiciously determine how to allocate samples and computational power across candidate split points. We provide theoretical guarantees that MABSplit improves the sample complexity of each node split from linear to logarithmic in the number of data points. In some settings, MABSplit leads to 100x faster training (an 99% reduction in training time) without any decrease in generalization performance. We demonstrate similar speedups when MABSplit is used across a variety of forest-based variants, such as Extremely Random Forests and Random Patches. We also show our algorithm can be used in both classification and regression tasks. Finally, we show that MABSplit outperforms existing methods in generalization performance and feature importance calculations under a fixed computational budget. All of our experimental results are reproducible via a one-line script at https://github.com/ThrunGroup/FastForest.
Adaptive Learning of Rank-One Models for Efficient Pairwise Sequence Alignment
Nov 09, 2020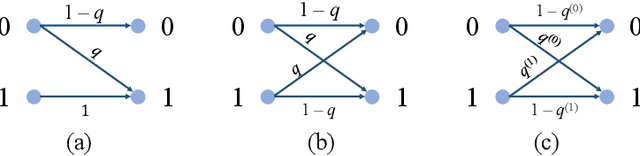
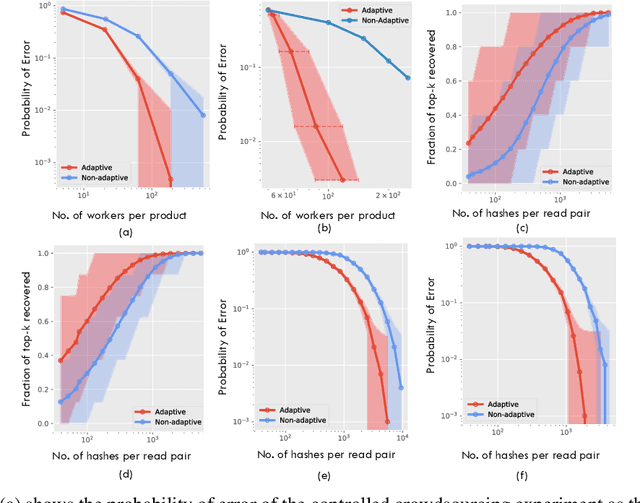
Pairwise alignment of DNA sequencing data is a ubiquitous task in bioinformatics and typically represents a heavy computational burden. State-of-the-art approaches to speed up this task use hashing to identify short segments (k-mers) that are shared by pairs of reads, which can then be used to estimate alignment scores. However, when the number of reads is large, accurately estimating alignment scores for all pairs is still very costly. Moreover, in practice, one is only interested in identifying pairs of reads with large alignment scores. In this work, we propose a new approach to pairwise alignment estimation based on two key new ingredients. The first ingredient is to cast the problem of pairwise alignment estimation under a general framework of rank-one crowdsourcing models, where the workers' responses correspond to k-mer hash collisions. These models can be accurately solved via a spectral decomposition of the response matrix. The second ingredient is to utilise a multi-armed bandit algorithm to adaptively refine this spectral estimator only for read pairs that are likely to have large alignments. The resulting algorithm iteratively performs a spectral decomposition of the response matrix for adaptively chosen subsets of the read pairs.
Bandit-PAM: Almost Linear Time $k$-Medoids Clustering via Multi-Armed Bandits
Jun 11, 2020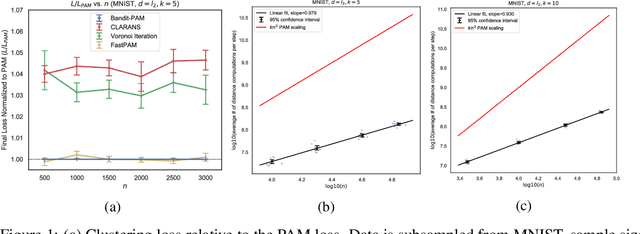
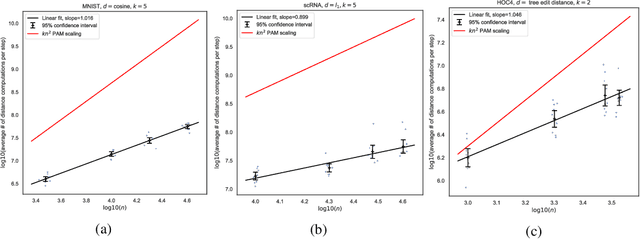
Clustering is a ubiquitous task in data science. Compared to the commonly used $k$-means clustering algorithm, $k$-medoids clustering algorithms require the cluster centers to be actual data points and support arbitrary distance metrics, allowing for greater interpretability and the clustering of structured objects. Current state-of-the-art $k$-medoids clustering algorithms, such as Partitioning Around Medoids (PAM), are iterative and are quadratic in the dataset size $n$ for each iteration, being prohibitively expensive for large datasets. We propose Bandit-PAM, a randomized algorithm inspired by techniques from multi-armed bandits, that significantly improves the computational efficiency of PAM. We theoretically prove that Bandit-PAM reduces the complexity of each PAM iteration from $O(n^2)$ to $O(n \log n)$ and returns the same results with high probability, under assumptions on the data that often hold in practice. We empirically validate our results on several large-scale real-world datasets, including a coding exercise submissions dataset from Code.org, the 10x Genomics 68k PBMC single-cell RNA sequencing dataset, and the MNIST handwritten digits dataset. We observe that Bandit-PAM returns the same results as PAM while performing up to 200x fewer distance computations. The improvements demonstrated by Bandit-PAM enable $k$-medoids clustering on a wide range of applications, including identifying cell types in large-scale single-cell data and providing scalable feedback for students learning computer science online. We also release Python and C++ implementations of our algorithm.