 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Batch Correction for Cell Painting via Batch-Dependent Kernels and Adaptive Sampling
Jan 29, 2026Cell Painting is a microscopy-based, high-content imaging assay that produces rich morphological profiles of cells and can support drug discovery by quantifying cellular responses to chemical perturbations. At scale, however, Cell Painting data is strongly affected by batch effects arising from differences in laboratories, instruments, and protocols, which can obscure biological signal. We present BALANS (Batch Alignment via Local Affinities and Subsampling), a scalable batch-correction method that aligns samples across batches by constructing a smoothed affinity matrix from pairwise distances. Given $n$ data points, BALANS builds a sparse affinity matrix $A \in \mathbb{R}^{n \times n}$ using two ideas. (i) For points $i$ and $j$, it sets a local scale using the distance from $i$ to its $k$-th nearest neighbor within the batch of $j$, then computes $A_{ij}$ via a Gaussian kernel calibrated by these batch-aware local scales. (ii) Rather than forming all $n^2$ entries, BALANS uses an adaptive sampling procedure that prioritizes rows with low cumulative neighbor coverage and retains only the strongest affinities per row, yielding a sparse but informative approximation of $A$. We prove that this sampling strategy is order-optimal in sample complexity and provides an approximation guarantee, and we show that BALANS runs in nearly linear time in $n$. Experiments on diverse real-world Cell Painting datasets and controlled large-scale synthetic benchmarks demonstrate that BALANS scales to large collections while improving runtime over native implementations of widely used batch-correction methods, without sacrificing correction quality.
Utilizing Free Clients in Federated Learning for Focused Model Enhancement
Oct 06, 2023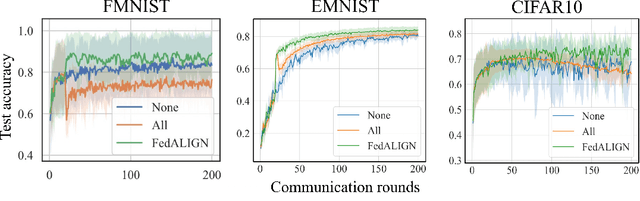
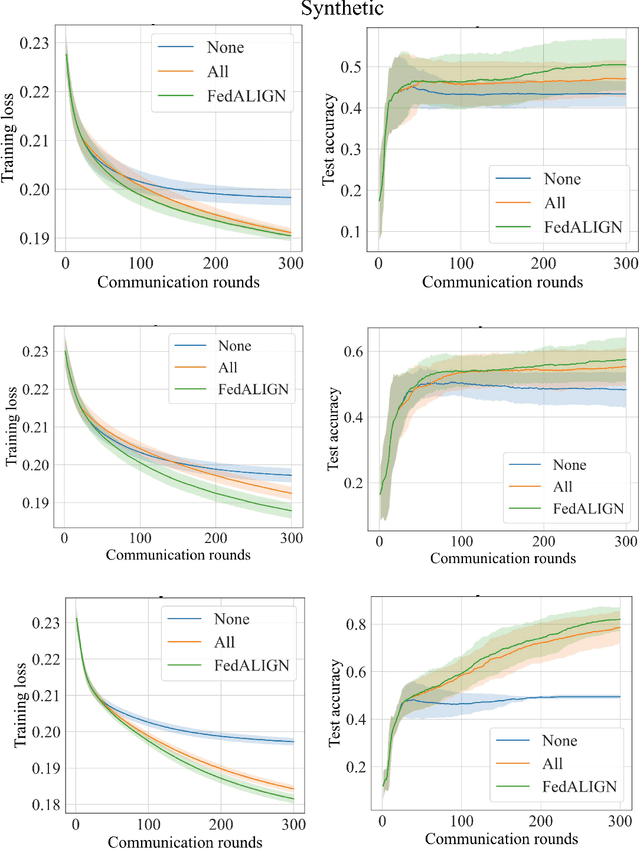
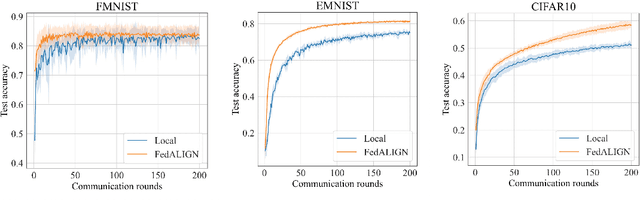
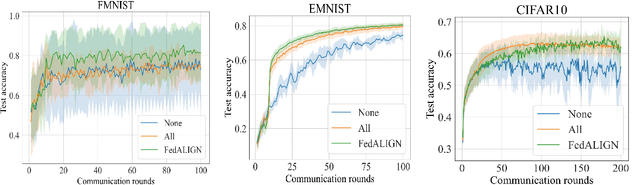
Federated Learning (FL) is a distributed machine learning approach to learn models on decentralized heterogeneous data, without the need for clients to share their data. Many existing FL approaches assume that all clients have equal importance and construct a global objective based on all clients. We consider a version of FL we call Prioritized FL, where the goal is to learn a weighted mean objective of a subset of clients, designated as priority clients. An important question arises: How do we choose and incentivize well aligned non priority clients to participate in the federation, while discarding misaligned clients? We present FedALIGN (Federated Adaptive Learning with Inclusion of Global Needs) to address this challenge. The algorithm employs a matching strategy that chooses non priority clients based on how similar the models loss is on their data compared to the global data, thereby ensuring the use of non priority client gradients only when it is beneficial for priority clients. This approach ensures mutual benefits as non priority clients are motivated to join when the model performs satisfactorily on their data, and priority clients can utilize their updates and computational resources when their goals align. We present a convergence analysis that quantifies the trade off between client selection and speed of convergence. Our algorithm shows faster convergence and higher test accuracy than baselines for various synthetic and benchmark datasets.
Unreliable Multi-Armed Bandits: A Novel Approach to Recommendation Systems
Nov 14, 2019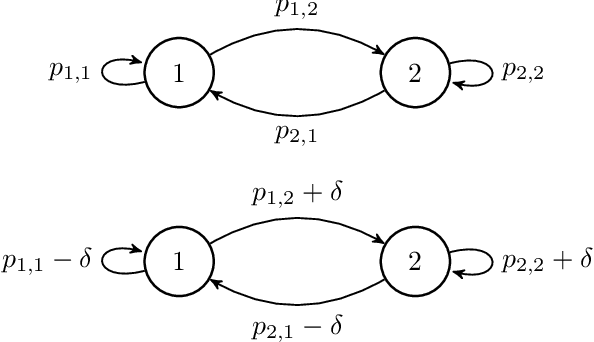
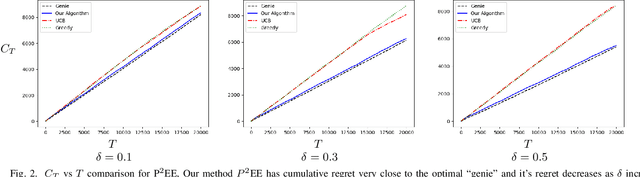
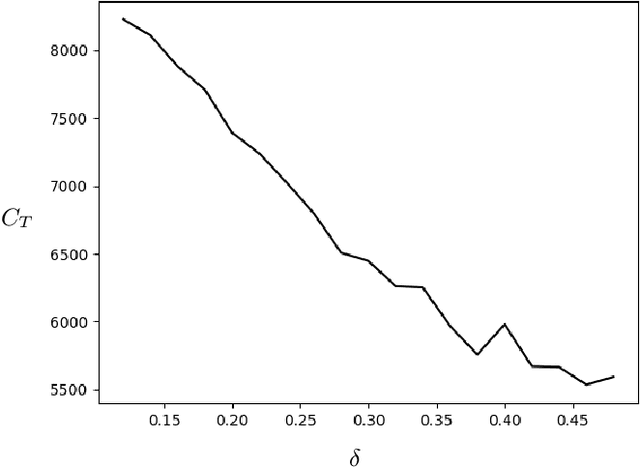
We use a novel modification of Multi-Armed Bandits to create a new model for recommendation systems. We model the recommendation system as a bandit seeking to maximize reward by pulling on arms with unknown rewards. The catch however is that this bandit can only access these arms through an unreliable intermediate that has some level of autonomy while choosing its arms. For example, in a streaming website the user has a lot of autonomy while choosing content they want to watch. The streaming sites can use targeted advertising as a means to bias opinions of these users. Here the streaming site is the bandit aiming to maximize reward and the user is the unreliable intermediate. We model the intermediate as accessing states via a Markov chain. The bandit is allowed to perturb this Markov chain. We prove fundamental theorems for this setting after which we show a close-to-optimal Explore-Commit algorithm.