 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge without Wisdom: Measuring Misalignment between LLMs and Intended Impact
Mar 01, 2026LLMs increasingly excel on AI benchmarks, but doing so does not guarantee validity for downstream tasks. This study evaluates the performance of leading foundation models (FMs, i.e., generative pre-trained base LLMs) with out-of-distribution (OOD) tasks of the teaching and learning of schoolchildren. Across all FMs, inter-model behaviors on disparate tasks correlate higher than they do with expert human behaviors on target tasks. These biases shared across LLMs are poorly aligned with downstream measures of teaching quality and often \textit{negatively aligned with learning outcomes}. Further, we find multi-model ensembles, both unanimous model voting and expert-weighting by benchmark performance, further exacerbate misalignment with learning. We measure that 50\% of the variation in misalignment error is shared across foundation models, suggesting that common pretraining accounts for much of the misalignment in these tasks. We demonstrate methods for robustly measuring alignment of complex tasks and provide unique insights into both educational applications of foundation models and to understanding limitations of models.
Variational Temporal IRT: Fast, Accurate, and Explainable Inference of Dynamic Learner Proficiency
Nov 14, 2023Dynamic Item Response Models extend the standard Item Response Theory (IRT) to capture temporal dynamics in learner ability. While these models have the potential to allow instructional systems to actively monitor the evolution of learner proficiency in real time, existing dynamic item response models rely on expensive inference algorithms that scale poorly to massive datasets. In this work, we propose Variational Temporal IRT (VTIRT) for fast and accurate inference of dynamic learner proficiency. VTIRT offers orders of magnitude speedup in inference runtime while still providing accurate inference. Moreover, the proposed algorithm is intrinsically interpretable by virtue of its modular design. When applied to 9 real student datasets, VTIRT consistently yields improvements in predicting future learner performance over other learner proficiency models.
Linking Sequences of Events with Sparse or No Common Occurrence across Data Sets
Nov 12, 2017
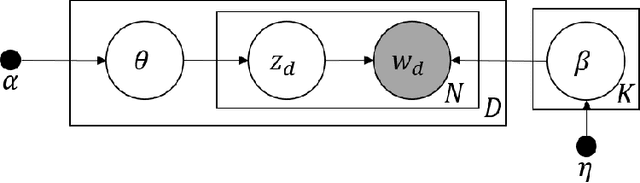
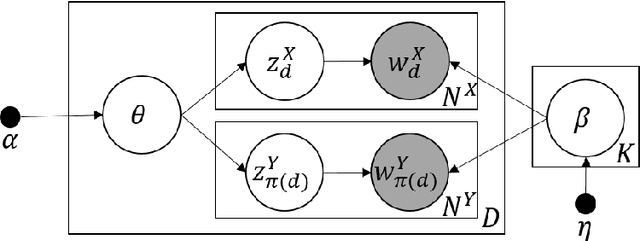
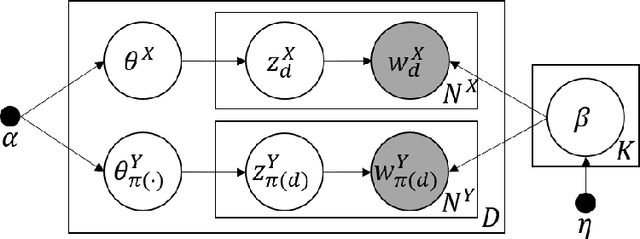
Data of practical interest - such as personal records, transaction logs, and medical histories - are sequential collections of events relevant to a particular source entity. Recent studies have attempted to link sequences that represent a common entity across data sets to allow more comprehensive statistical analyses and to identify potential privacy failures. Yet, current approaches remain tailored to their specific domains of application, and they fail when co-referent sequences in different data sets contain sparse or no common events, which occurs frequently in many cases. To address this, we formalize the general problem of "sequence linkage" and describe "LDA-Link," a generic solution that is applicable even when co-referent event sequences contain no common items at all. LDA-Link is built upon "Split-Document" model, a new mixed-membership probabilistic model for the generation of event sequence collections. It detects the latent similarity of sequences and thus achieves robustness particularly when co-referent sequences share sparse or no event overlap. We apply LDA-Link in the context of social media profile reconciliation where users make no common posts across platforms, comparing to the state-of-the-art generic solution to sequence linkage.