 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Abstract Models for Strategic Exploration and Fast Reward Transfer
Jul 12, 2020
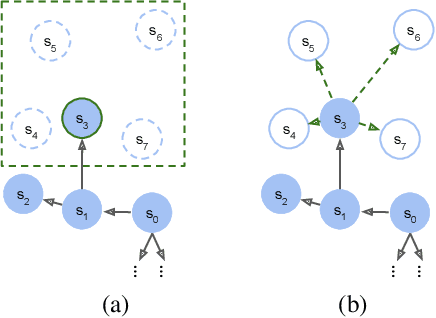

Model-based reinforcement learning (RL) is appealing because (i) it enables planning and thus more strategic exploration, and (ii) by decoupling dynamics from rewards, it enables fast transfer to new reward functions. However, learning an accurate Markov Decision Process (MDP) over high-dimensional states (e.g., raw pixels) is extremely challenging because it requires function approximation, which leads to compounding errors. Instead, to avoid compounding errors, we propose learning an abstract MDP over abstract states: low-dimensional coarse representations of the state (e.g., capturing agent position, ignoring other objects). We assume access to an abstraction function that maps the concrete states to abstract states. In our approach, we construct an abstract MDP, which grows through strategic exploration via planning. Similar to hierarchical RL approaches, the abstract actions of the abstract MDP are backed by learned subpolicies that navigate between abstract states. Our approach achieves strong results on three of the hardest Arcade Learning Environment games (Montezuma's Revenge, Pitfall!, and Private Eye), including superhuman performance on Pitfall! without demonstrations. After training on one task, we can reuse the learned abstract MDP for new reward functions, achieving higher reward in 1000x fewer samples than model-free methods trained from scratch.