 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Train Twice: Improving Group Robustness without Training Group Information
Jul 19, 2021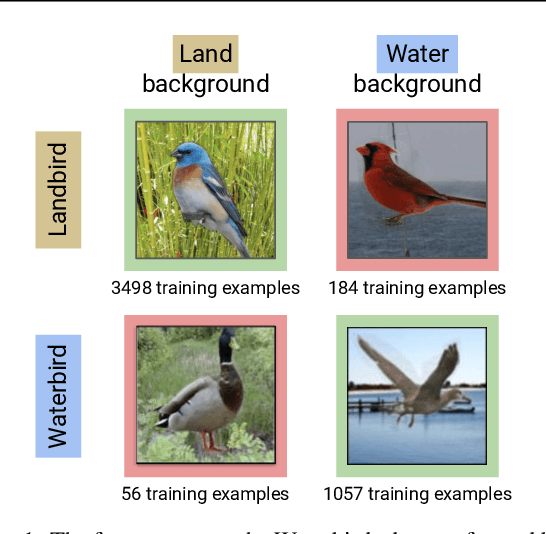
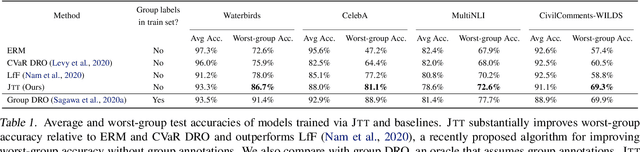

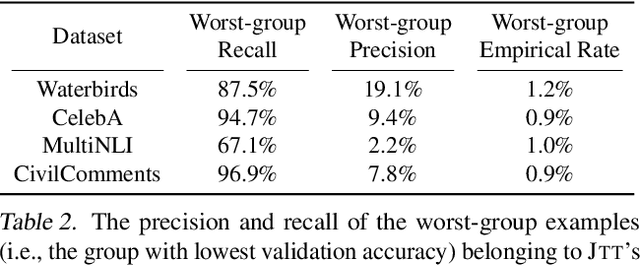
Standard training via empirical risk minimization (ERM) can produce models that achieve high accuracy on average but low accuracy on certain groups, especially in the presence of spurious correlations between the input and label. Prior approaches that achieve high worst-group accuracy, like group distributionally robust optimization (group DRO) require expensive group annotations for each training point, whereas approaches that do not use such group annotations typically achieve unsatisfactory worst-group accuracy. In this paper, we propose a simple two-stage approach, JTT, that first trains a standard ERM model for several epochs, and then trains a second model that upweights the training examples that the first model misclassified. Intuitively, this upweights examples from groups on which standard ERM models perform poorly, leading to improved worst-group performance. Averaged over four image classification and natural language processing tasks with spurious correlations, JTT closes 75% of the gap in worst-group accuracy between standard ERM and group DRO, while only requiring group annotations on a small validation set in order to tune hyperparameters.
Discriminator Augmented Model-Based Reinforcement Learning
Mar 30, 2021
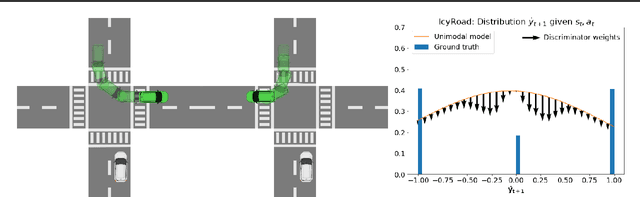
By planning through a learned dynamics model, model-based reinforcement learning (MBRL) offers the prospect of good performance with little environment interaction. However, it is common in practice for the learned model to be inaccurate, impairing planning and leading to poor performance. This paper aims to improve planning with an importance sampling framework that accounts and corrects for discrepancy between the true and learned dynamics. This framework also motivates an alternative objective for fitting the dynamics model: to minimize the variance of value estimation during planning. We derive and implement this objective, which encourages better prediction on trajectories with larger returns. We observe empirically that our approach improves the performance of current MBRL algorithms on two stochastic control problems, and provide a theoretical basis for our method.
CheXpert: A Large Chest Radiograph Dataset with Uncertainty Labels and Expert Comparison
Jan 21, 2019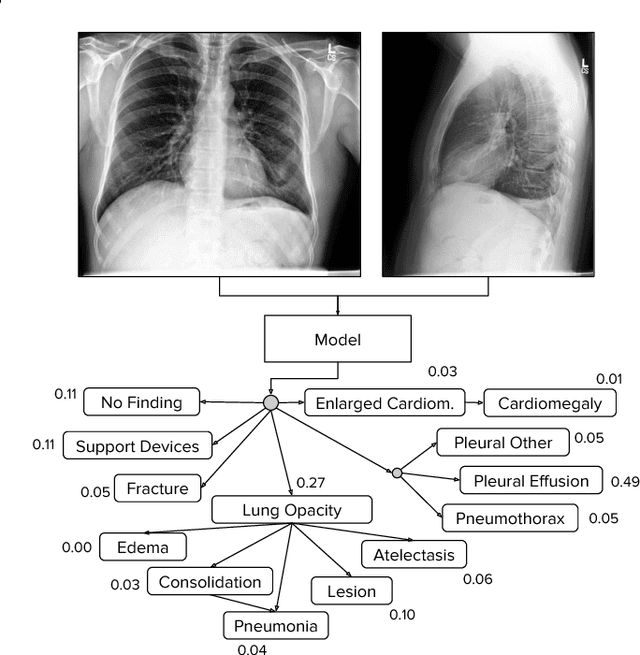
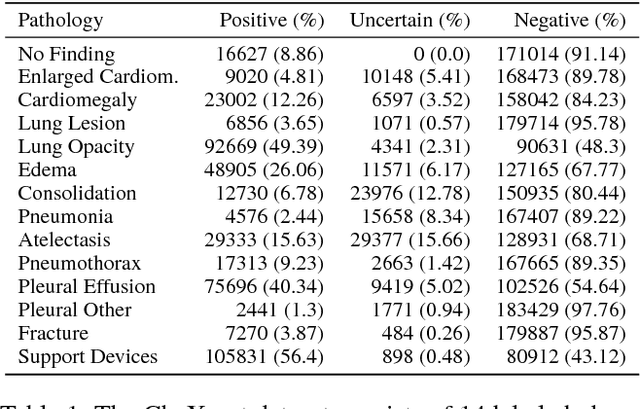

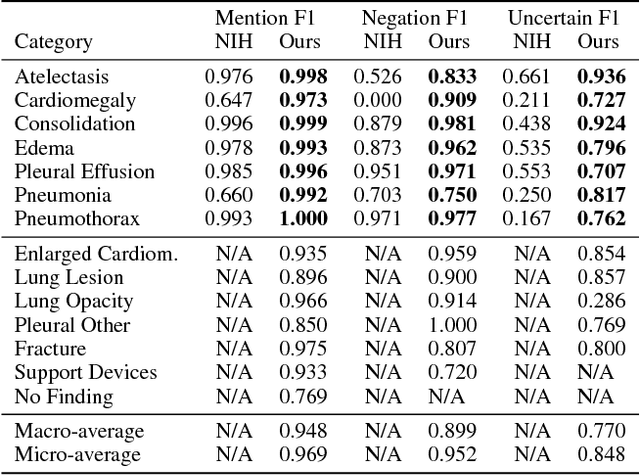
Large, labeled datasets have driven deep learning methods to achieve expert-level performance on a variety of medical imaging tasks. We present CheXpert, a large dataset that contains 224,316 chest radiographs of 65,240 patients. We design a labeler to automatically detect the presence of 14 observations in radiology reports, capturing uncertainties inherent in radiograph interpretation. We investigate different approaches to using the uncertainty labels for training convolutional neural networks that output the probability of these observations given the available frontal and lateral radiographs. On a validation set of 200 chest radiographic studies which were manually annotated by 3 board-certified radiologists, we find that different uncertainty approaches are useful for different pathologies. We then evaluate our best model on a test set composed of 500 chest radiographic studies annotated by a consensus of 5 board-certified radiologists, and compare the performance of our model to that of 3 additional radiologists in the detection of 5 selected pathologies. On Cardiomegaly, Edema, and Pleural Effusion, the model ROC and PR curves lie above all 3 radiologist operating points. We release the dataset to the public as a standard benchmark to evaluate performance of chest radiograph interpretation models. The dataset is freely available at https://stanfordmlgroup.github.io/competitions/chexpert .