 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminator Augmented Model-Based Reinforcement Learning
Paper and Code
Mar 30, 2021
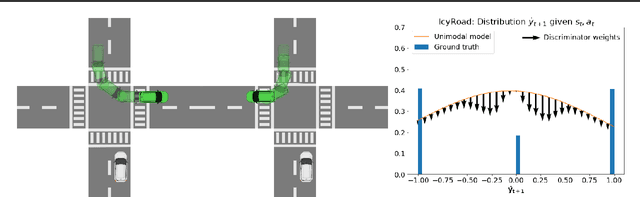
By planning through a learned dynamics model, model-based reinforcement learning (MBRL) offers the prospect of good performance with little environment interaction. However, it is common in practice for the learned model to be inaccurate, impairing planning and leading to poor performance. This paper aims to improve planning with an importance sampling framework that accounts and corrects for discrepancy between the true and learned dynamics. This framework also motivates an alternative objective for fitting the dynamics model: to minimize the variance of value estimation during planning. We derive and implement this objective, which encourages better prediction on trajectories with larger returns. We observe empirically that our approach improves the performance of current MBRL algorithms on two stochastic control problems, and provide a theoretical basis for our method.