 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Feature Selection Approach for Learning Skinny Trees
Paper and Code
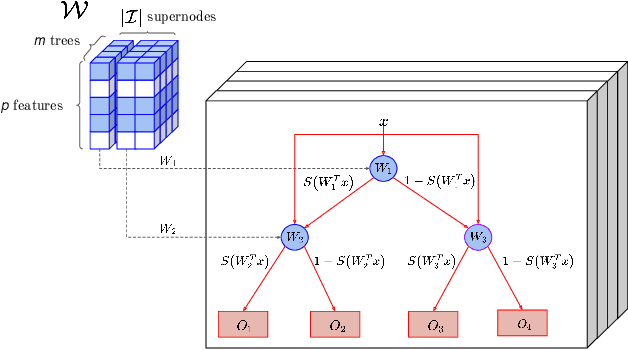
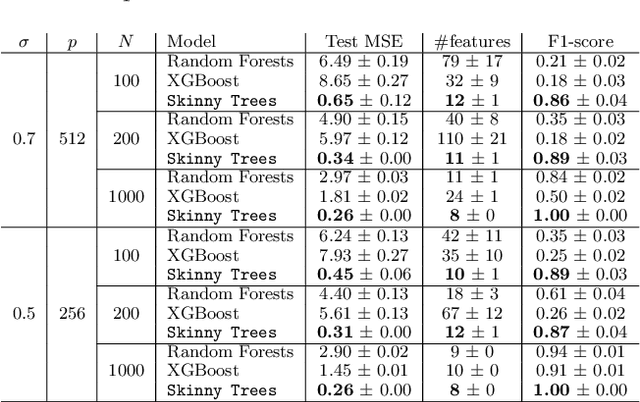
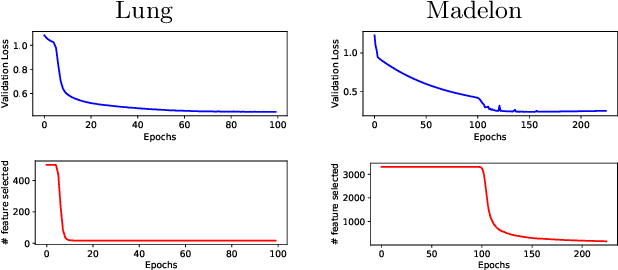
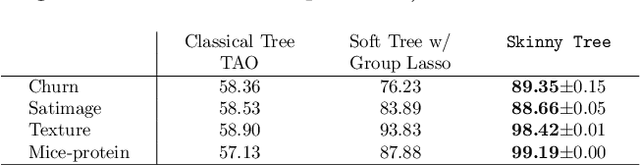
Joint feature selection and tree ensemble learning is a challenging task. Popular tree ensemble toolkits e.g., Gradient Boosted Trees and Random Forests support feature selection post-training based on feature importances, which are known to be misleading, and can significantly hurt performance. We propose Skinny Trees: a toolkit for feature selection in tree ensembles, such that feature selection and tree ensemble learning occurs simultaneously. It is based on an end-to-end optimization approach that considers feature selection in differentiable trees with Group $\ell_0 - \ell_2$ regularization. We optimize with a first-order proximal method and present convergence guarantees for a non-convex and non-smooth objective. Interestingly, dense-to-sparse regularization scheduling can lead to more expressive and sparser tree ensembles than vanilla proximal method. On 15 synthetic and real-world datasets, Skinny Trees can achieve $1.5\times$ - $620\times$ feature compression rates, leading up to $10\times$ faster inference over dense trees, without any loss in performance. Skinny Trees lead to superior feature selection than many existing toolkits e.g., in terms of AUC performance for $25\%$ feature budget, Skinny Trees outperforms LightGBM by $10.2\%$ (up to $37.7\%$), and Random Forests by $3\%$ (up to $12.5\%$).