 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTG-Critic: A Timbre-Guided Model for Reference-Independent Singing Evaluation
May 16, 2023Automatic singing evaluation independent of reference melody is a challenging task due to its subjective and multi-dimensional nature. As an essential attribute of singing voices, vocal timbre has a non-negligible effect and influence on human perception of singing quality. However, no research has been done to include timbre information explicitly in singing evaluation models. In this paper, a data-driven model TG-Critic is proposed to introduce timbre embeddings as one of the model inputs to guide the evaluation of singing quality. The trunk structure of TG-Critic is designed as a multi-scale network to summarize the contextual information from constant-Q transform features in a high-resolution way. Furthermore, an automatic annotation method is designed to construct a large three-class singing evaluation dataset with low human-effort. The experimental results show that the proposed model outperforms the existing state-of-the-art models in most cases.
DEEPCHORUS: A Hybrid Model of Multi-scale Convolution and Self-attention for Chorus Detection
Feb 13, 2022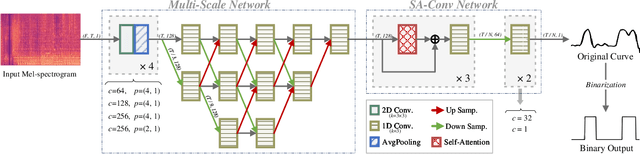
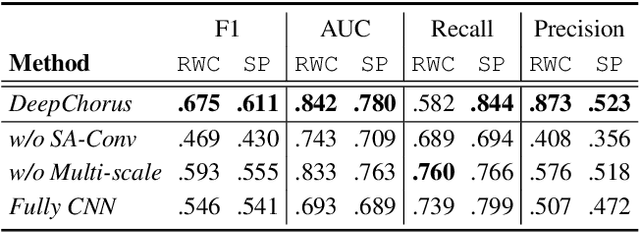
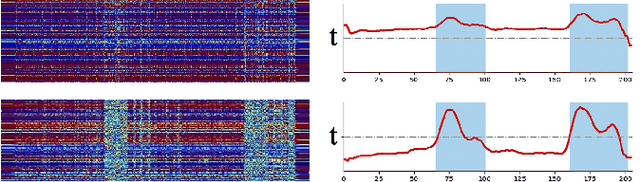

Chorus detection is a challenging problem in musical signal processing as the chorus often repeats more than once in popular songs, usually with rich instruments and complex rhythm forms. Most of the existing works focus on the receptiveness of chorus sections based on some explicit features such as loudness and occurrence frequency. These pre-assumptions for chorus limit the generalization capacity of these methods, causing misdetection on other repeated sections such as verse. To solve the problem, in this paper we propose an end-to-end chorus detection model DeepChorus, reducing the engineering effort and the need for prior knowledge. The proposed model includes two main structures: i) a Multi-Scale Network to derive preliminary representations of chorus segments, and ii) a Self-Attention Convolution Network to further process the features into probability curves representing chorus presence. To obtain the final results, we apply an adaptive threshold to binarize the original curve. The experimental results show that DeepChorus outperforms existing state-of-the-art methods in most cases.
Musical Tempo Estimation Using a Multi-scale Network
Sep 03, 2021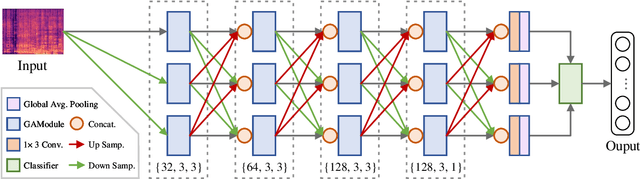

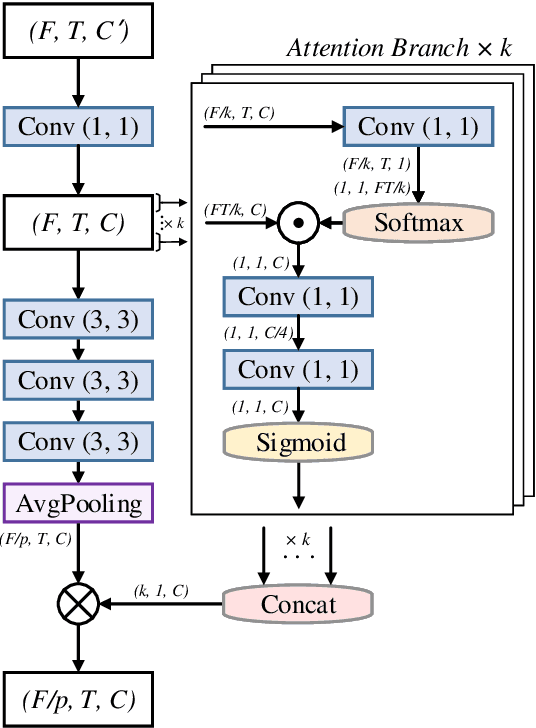
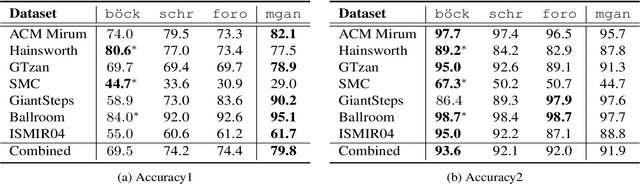
Recently, some single-step systems without onset detection have shown their effectiveness in automatic musical tempo estimation. Following the success of these systems, in this paper we propose a Multi-scale Grouped Attention Network to further explore the potential of such methods. A multi-scale structure is introduced as the overall network architecture where information from different scales is aggregated to strengthen contextual feature learning. Furthermore, we propose a Grouped Attention Module as the key component of the network. The proposed module separates the input feature into several groups along the frequency axis, which makes it capable of capturing long-range dependencies from different frequency positions on the spectrogram. In comparison experiments, the results on public datasets show that the proposed model outperforms existing state-of-the-art methods on Accuracy1.
Residual Attention Based Network for Automatic Classification of Phonation Modes
Jul 18, 2021
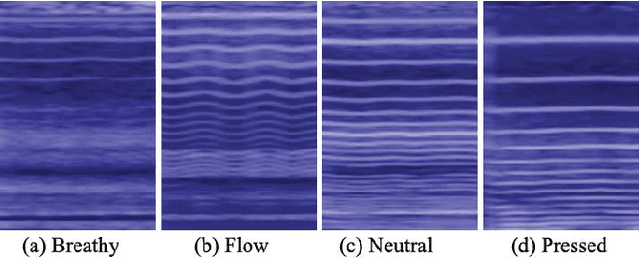
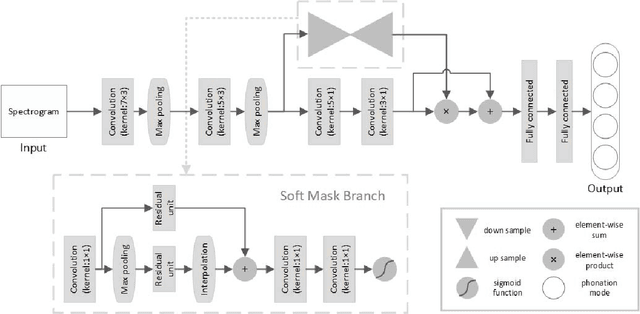

Phonation mode is an essential characteristic of singing style as well as an important expression of performance. It can be classified into four categories, called neutral, breathy, pressed and flow. Previous studies used voice quality features and feature engineering for classification. While deep learning has achieved significant progress in other fields of music information retrieval (MIR), there are few attempts in the classification of phonation modes. In this study, a Residual Attention based network is proposed for automatic classification of phonation modes. The network consists of a convolutional network performing feature processing and a soft mask branch enabling the network focus on a specific area. In comparison experiments, the models with proposed network achieve better results in three of the four datasets than previous works, among which the highest classification accuracy is 94.58%, 2.29% higher than the baseline.
Frequency-Temporal Attention Network for Singing Melody Extraction
Feb 19, 2021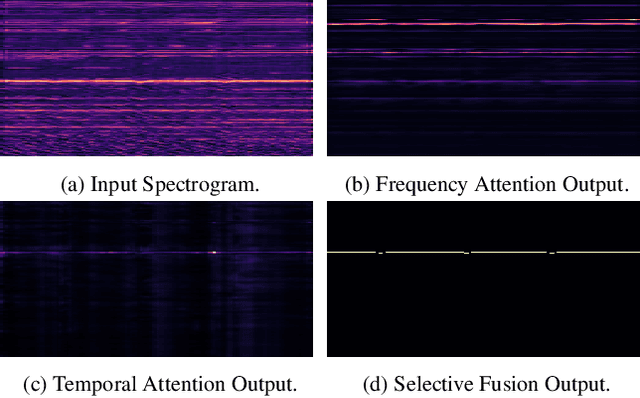
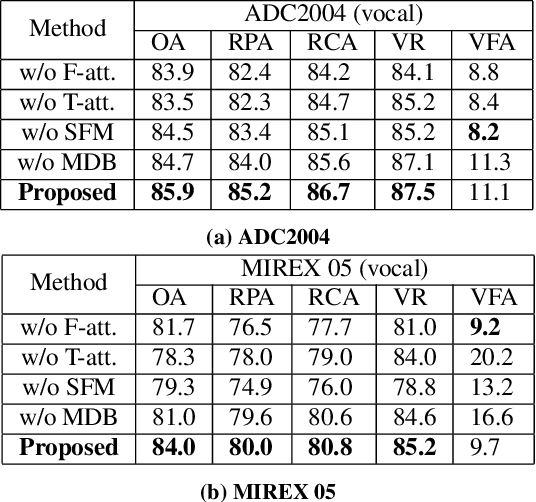
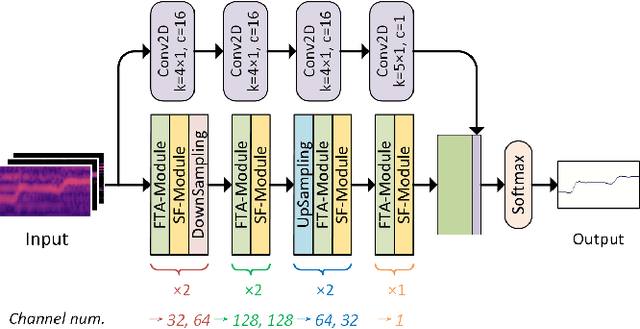
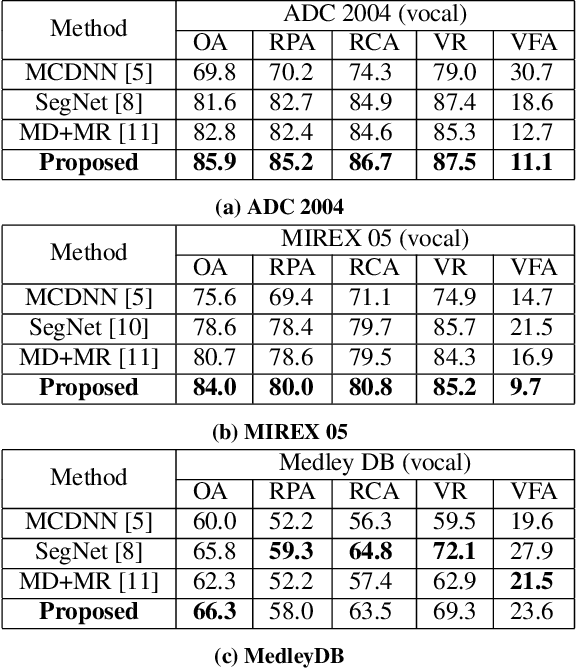
Musical audio is generally composed of three physical properties: frequency, time and magnitude. Interestingly, human auditory periphery also provides neural codes for each of these dimensions to perceive music. Inspired by these intrinsic characteristics, a frequency-temporal attention network is proposed to mimic human auditory for singing melody extraction. In particular, the proposed model contains frequency-temporal attention modules and a selective fusion module corresponding to these three physical properties. The frequency attention module is used to select the same activation frequency bands as did in cochlear and the temporal attention module is responsible for analyzing temporal patterns. Finally, the selective fusion module is suggested to recalibrate magnitudes and fuse the raw information for prediction. In addition, we propose to use another branch to simultaneously predict the presence of singing voice melody. The experimental results show that the proposed model outperforms existing state-of-the-art methods.