 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudiovisual Singing Voice Separation
Paper and Code
Jul 01, 2021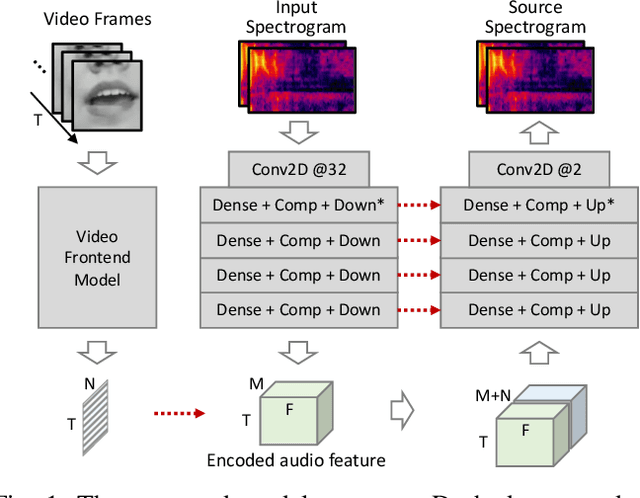
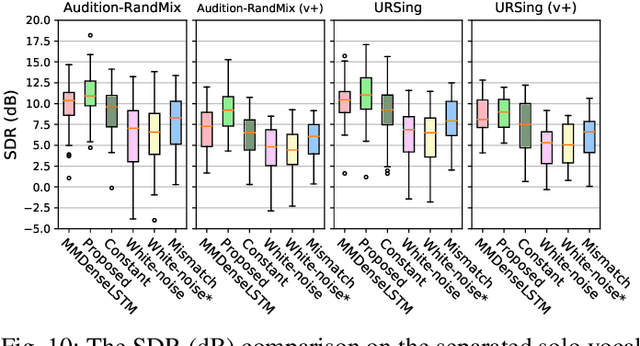
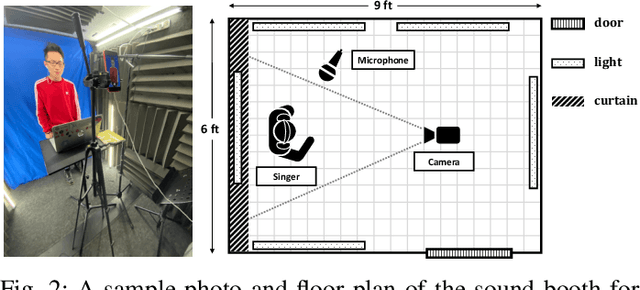

Separating a song into vocal and accompaniment components is an active research topic, and recent years witnessed an increased performance from supervised training using deep learning techniques. We propose to apply the visual information corresponding to the singers' vocal activities to further improve the quality of the separated vocal signals. The video frontend model takes the input of mouth movement and fuses it into the feature embeddings of an audio-based separation framework. To facilitate the network to learn audiovisual correlation of singing activities, we add extra vocal signals irrelevant to the mouth movement to the audio mixture during training. We create two audiovisual singing performance datasets for training and evaluation, respectively, one curated from audition recordings on the Internet, and the other recorded in house. The proposed method outperforms audio-based methods in terms of separation quality on most test recordings. This advantage is especially pronounced when there are backing vocals in the accompaniment, which poses a great challenge for audio-only methods.