 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and Scalable Version Identification Using Musically-Motivated Embeddings
Paper and Code
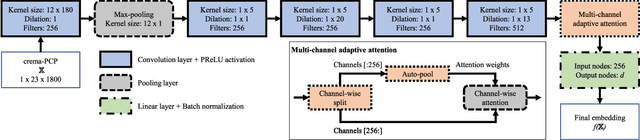
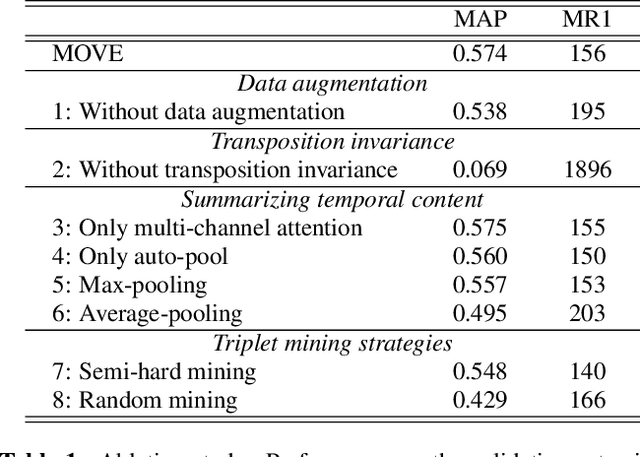
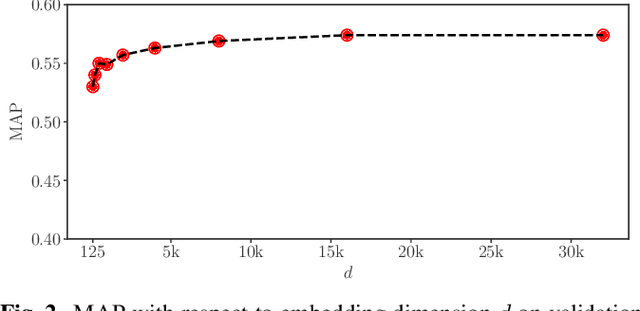
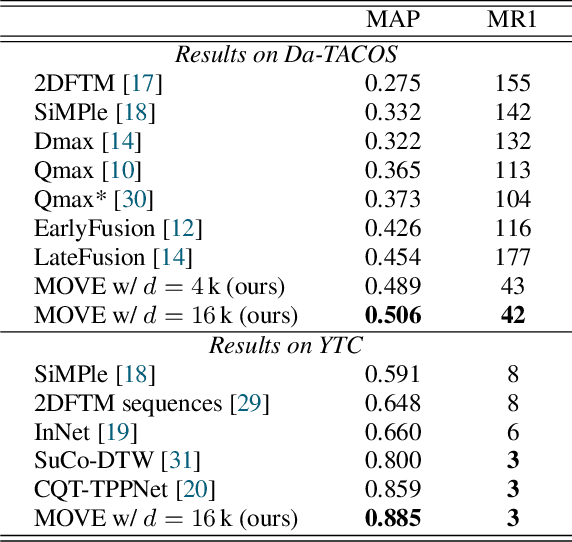
The version identification (VI) task deals with the automatic detection of recordings that correspond to the same underlying musical piece. Despite many efforts, VI is still an open problem, with much room for improvement, specially with regard to combining accuracy and scalability. In this paper, we present MOVE, a musically-motivated method for accurate and scalable version identification. MOVE achieves state-of-the-art performance on two publicly-available benchmark sets by learning scalable embeddings in an Euclidean distance space, using a triplet loss and a hard triplet mining strategy. It improves over previous work by employing an alternative input representation, and introducing a novel technique for temporal content summarization, a standardized latent space, and a data augmentation strategy specifically designed for VI. In addition to the main results, we perform an ablation study to highlight the importance of our design choices, and study the relation between embedding dimensionality and model performance.