 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Generated Music Detection in Broadcast Monitoring
Feb 06, 2026AI music generators have advanced to the point where their outputs are often indistinguishable from human compositions. While detection methods have emerged, they are typically designed and validated in music streaming contexts with clean, full-length tracks. Broadcast audio, however, poses a different challenge: music appears as short excerpts, often masked by dominant speech, conditions under which existing detectors fail. In this work, we introduce AI-OpenBMAT, the first dataset tailored to broadcast-style AI-music detection. It contains 3,294 one-minute audio excerpts (54.9 hours) that follow the duration patterns and loudness relations of real television audio, combining human-made production music with stylistically matched continuations generated with Suno v3.5. We benchmark a CNN baseline and state-of-the-art SpectTTTra models to assess SNR and duration robustness, and evaluate on a full broadcast scenario. Across all settings, models that excel in streaming scenarios suffer substantial degradation, with F1-scores dropping below 60% when music is in the background or has a short duration. These results highlight speech masking and short music length as critical open challenges for AI music detection, and position AI-OpenBMAT as a benchmark for developing detectors capable of meeting industrial broadcast requirements.
Leveraging Pre-Trained Autoencoders for Interpretable Prototype Learning of Music Audio
Feb 14, 2024


We present PECMAE, an interpretable model for music audio classification based on prototype learning. Our model is based on a previous method, APNet, which jointly learns an autoencoder and a prototypical network. Instead, we propose to decouple both training processes. This enables us to leverage existing self-supervised autoencoders pre-trained on much larger data (EnCodecMAE), providing representations with better generalization. APNet allows prototypes' reconstruction to waveforms for interpretability relying on the nearest training data samples. In contrast, we explore using a diffusion decoder that allows reconstruction without such dependency. We evaluate our method on datasets for music instrument classification (Medley-Solos-DB) and genre recognition (GTZAN and a larger in-house dataset), the latter being a more challenging task not addressed with prototypical networks before. We find that the prototype-based models preserve most of the performance achieved with the autoencoder embeddings, while the sonification of prototypes benefits understanding the behavior of the classifier.
FlowGrad: Using Motion for Visual Sound Source Localization
Nov 15, 2022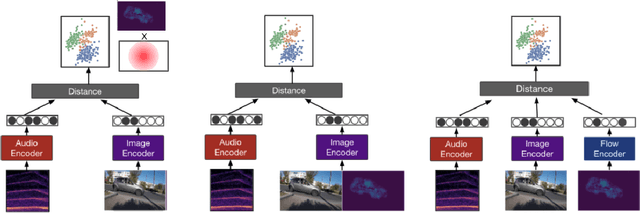
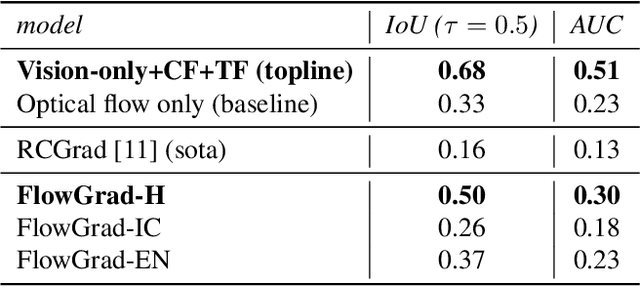
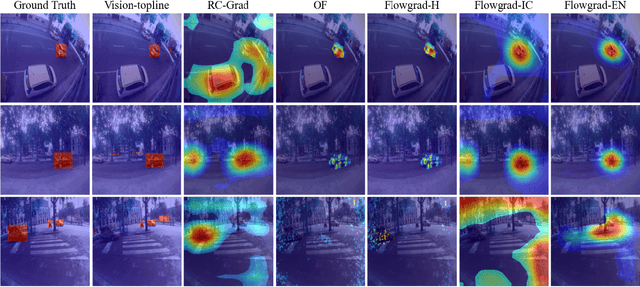
Most recent work in visual sound source localization relies on semantic audio-visual representations learned in a self-supervised manner, and by design excludes temporal information present in videos. While it proves to be effective for widely used benchmark datasets, the method falls short for challenging scenarios like urban traffic. This work introduces temporal context into the state-of-the-art methods for sound source localization in urban scenes using optical flow as a means to encode motion information. An analysis of the strengths and weaknesses of our methods helps us better understand the problem of visual sound source localization and sheds light on open challenges for audio-visual scene understanding.
Soundata: A Python library for reproducible use of audio datasets
Oct 04, 2021Soundata is a Python library for loading and working with audio datasets in a standardized way, removing the need for writing custom loaders in every project, and improving reproducibility by providing tools to validate data against a canonical version. It speeds up research pipelines by allowing users to quickly download a dataset, load it into memory in a standardized and reproducible way, validate that the dataset is complete and correct, and more. Soundata is based and inspired on mirdata and design to complement mirdata by working with environmental sound, bioacoustic and speech datasets, among others. Soundata was created to be easy to use, easy to contribute to, and to increase reproducibility and standardize usage of sound datasets in a flexible way.