 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Automatic Assessment of TTS Quality in Spanish
Jul 02, 2025



This work addresses the development of a database for the automatic assessment of text-to-speech (TTS) systems in Spanish, aiming to improve the accuracy of naturalness prediction models. The dataset consists of 4,326 audio samples from 52 different TTS systems and human voices and is, up to our knowledge, the first of its kind in Spanish. To label the audios, a subjective test was designed based on the ITU-T Rec. P.807 standard and completed by 92 participants. Furthermore, the utility of the collected dataset was validated by training automatic naturalness prediction systems. We explored two approaches: fine-tuning an existing model originally trained for English, and training small downstream networks on top of frozen self-supervised speech models. Our models achieve a mean absolute error of 0.8 on a five-point MOS scale. Further analysis demonstrates the quality and diversity of the developed dataset, and its potential to advance TTS research in Spanish.
Benchmarking Time-localized Explanations for Audio Classification Models
Jun 04, 2025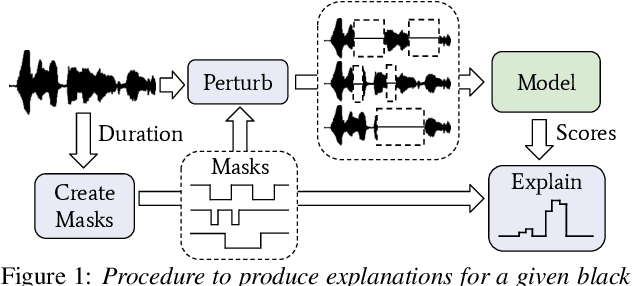
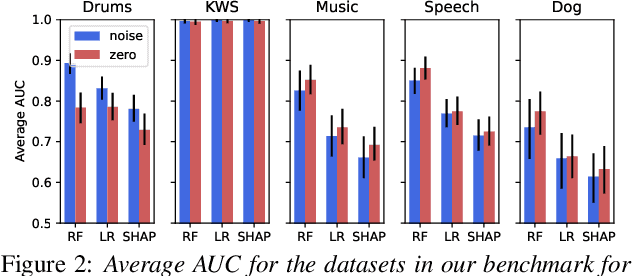
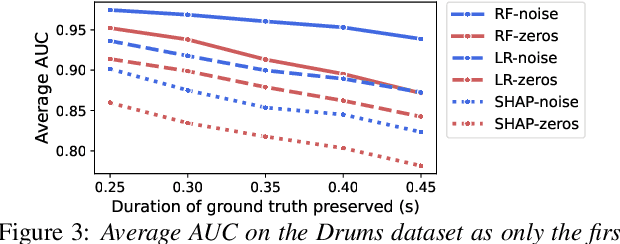
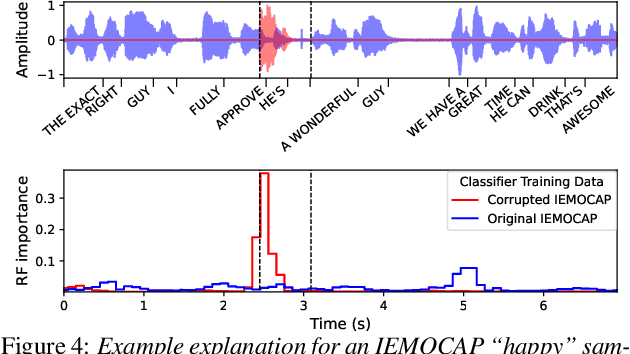
Most modern approaches for audio processing are opaque, in the sense that they do not provide an explanation for their decisions. For this reason, various methods have been proposed to explain the outputs generated by these models. Good explanations can result in interesting insights about the data or the model, as well as increase trust in the system. Unfortunately, evaluating the quality of explanations is far from trivial since, for most tasks, there is no clear ground truth explanation to use as reference. In this work, we propose a benchmark for time-localized explanations for audio classification models that uses time annotations of target events as a proxy for ground truth explanations. We use this benchmark to systematically optimize and compare various approaches for model-agnostic post-hoc explanation, obtaining, in some cases, close to perfect explanations. Finally, we illustrate the utility of the explanations for uncovering spurious correlations.
Fusion approaches for emotion recognition from speech using acoustic and text-based features
Mar 27, 2024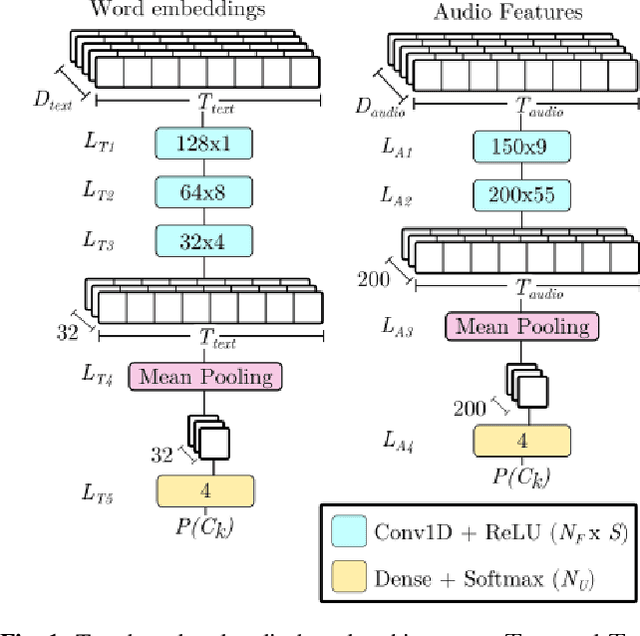
In this paper, we study different approaches for classifying emotions from speech using acoustic and text-based features. We propose to obtain contextualized word embeddings with BERT to represent the information contained in speech transcriptions and show that this results in better performance than using Glove embeddings. We also propose and compare different strategies to combine the audio and text modalities, evaluating them on IEMOCAP and MSP-PODCAST datasets. We find that fusing acoustic and text-based systems is beneficial on both datasets, though only subtle differences are observed across the evaluated fusion approaches. Finally, for IEMOCAP, we show the large effect that the criteria used to define the cross-validation folds have on results. In particular, the standard way of creating folds for this dataset results in a highly optimistic estimation of performance for the text-based system, suggesting that some previous works may overestimate the advantage of incorporating transcriptions.
Leveraging Pre-Trained Autoencoders for Interpretable Prototype Learning of Music Audio
Feb 14, 2024


We present PECMAE, an interpretable model for music audio classification based on prototype learning. Our model is based on a previous method, APNet, which jointly learns an autoencoder and a prototypical network. Instead, we propose to decouple both training processes. This enables us to leverage existing self-supervised autoencoders pre-trained on much larger data (EnCodecMAE), providing representations with better generalization. APNet allows prototypes' reconstruction to waveforms for interpretability relying on the nearest training data samples. In contrast, we explore using a diffusion decoder that allows reconstruction without such dependency. We evaluate our method on datasets for music instrument classification (Medley-Solos-DB) and genre recognition (GTZAN and a larger in-house dataset), the latter being a more challenging task not addressed with prototypical networks before. We find that the prototype-based models preserve most of the performance achieved with the autoencoder embeddings, while the sonification of prototypes benefits understanding the behavior of the classifier.
BUT CHiME-7 system description
Oct 18, 2023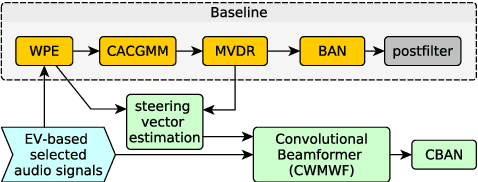
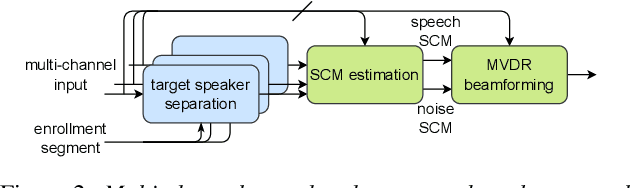
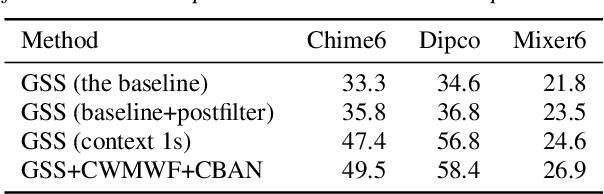
This paper describes the joint effort of Brno University of Technology (BUT), AGH University of Krakow and University of Buenos Aires on the development of Automatic Speech Recognition systems for the CHiME-7 Challenge. We train and evaluate various end-to-end models with several toolkits. We heavily relied on Guided Source Separation (GSS) to convert multi-channel audio to single channel. The ASR is leveraging speech representations from models pre-trained by self-supervised learning, and we do a fusion of several ASR systems. In addition, we modified external data from the LibriSpeech corpus to become a close domain and added it to the training. Our efforts were focused on the far-field acoustic robustness sub-track of Task 1 - Distant Automatic Speech Recognition (DASR), our systems use oracle segmentation.
EnCodecMAE: Leveraging neural codecs for universal audio representation learning
Sep 14, 2023

The goal of universal audio representation learning is to obtain foundational models that can be used for a variety of downstream tasks involving speech, music or environmental sounds. To approach this problem, methods inspired by self-supervised models from NLP, like BERT, are often used and adapted to audio. These models rely on the discrete nature of text, hence adopting this type of approach for audio processing requires either a change in the learning objective or mapping the audio signal to a set of discrete classes. In this work, we explore the use of EnCodec, a neural audio codec, to generate discrete targets for learning an universal audio model based on a masked autoencoder (MAE). We evaluate this approach, which we call EncodecMAE, on a wide range of audio tasks spanning speech, music and environmental sounds, achieving performances comparable or better than leading audio representation models.
Phone and speaker spatial organization in self-supervised speech representations
Feb 24, 2023
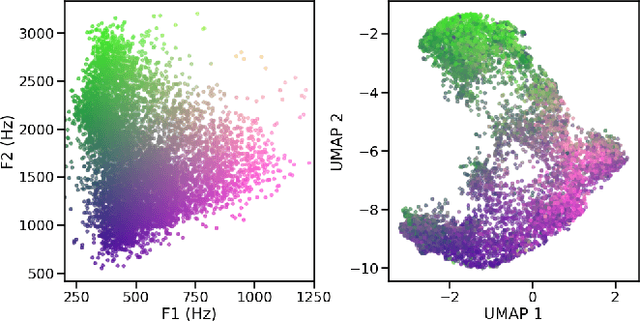
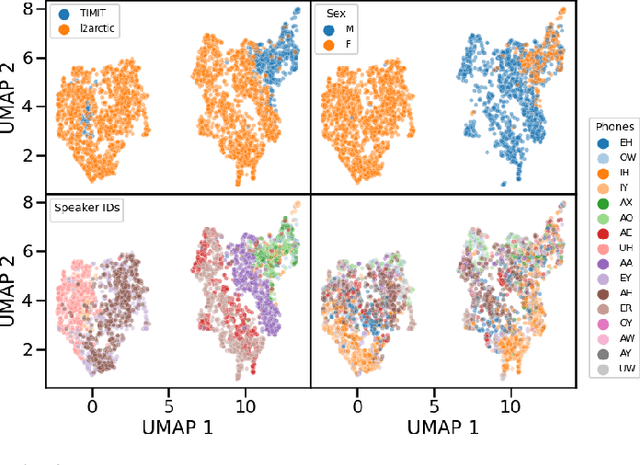
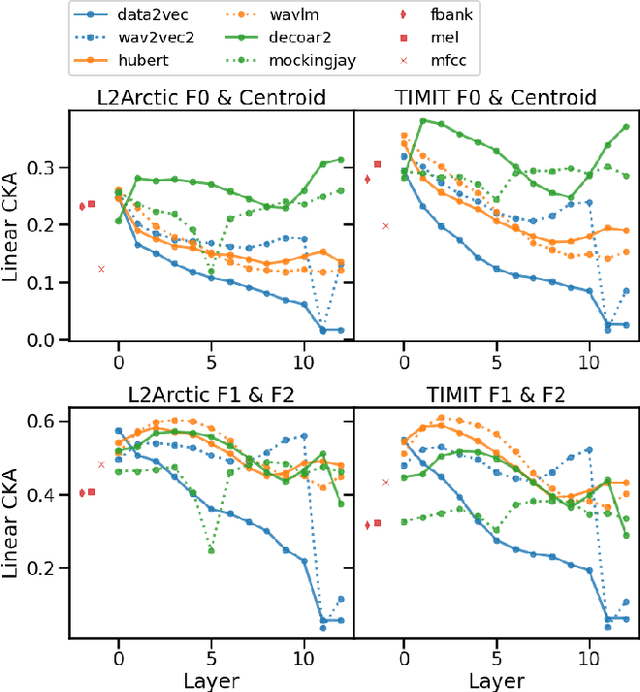
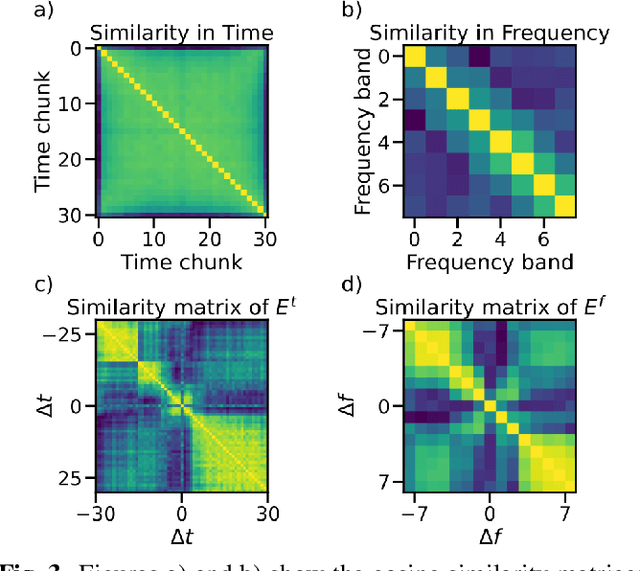
Self-supervised representations of speech are currently being widely used for a large number of applications. Recently, some efforts have been made in trying to analyze the type of information present in each of these representations. Most such work uses downstream models to test whether the representations can be successfully used for a specific task. The downstream models, though, typically perform nonlinear operations on the representation extracting information that may not have been readily available in the original representation. In this work, we analyze the spatial organization of phone and speaker information in several state-of-the-art speech representations using methods that do not require a downstream model. We measure how different layers encode basic acoustic parameters such as formants and pitch using representation similarity analysis. Further, we study the extent to which each representation clusters the speech samples by phone or speaker classes using non-parametric statistical testing. Our results indicate that models represent these speech attributes differently depending on the target task used during pretraining.
Study of positional encoding approaches for Audio Spectrogram Transformers
Oct 13, 2021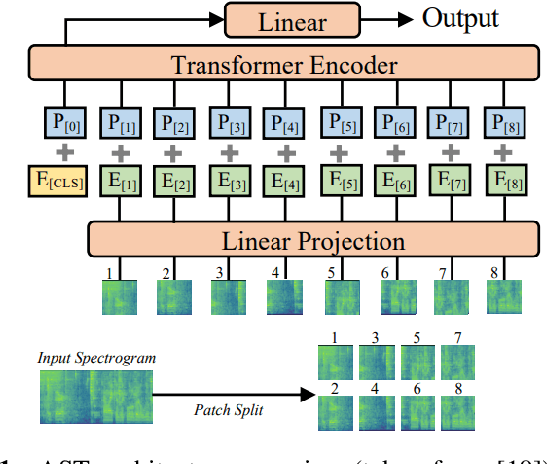
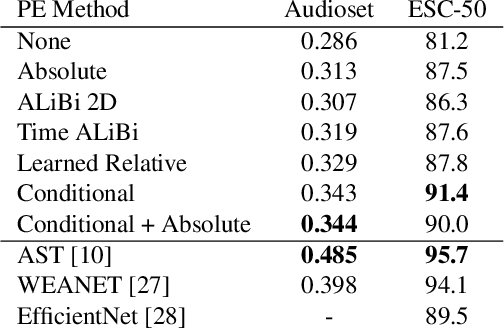
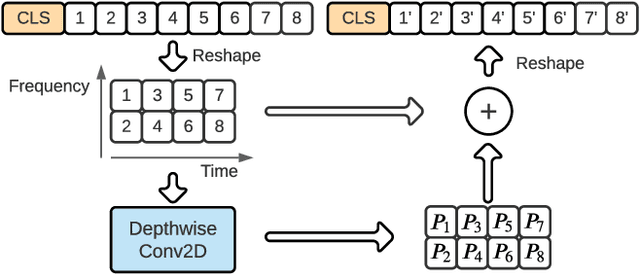
Transformers have revolutionized the world of deep learning, specially in the field of natural language processing. Recently, the Audio Spectrogram Transformer (AST) was proposed for audio classification, leading to state of the art results in several datasets. However, in order for ASTs to outperform CNNs, pretraining with ImageNet is needed. In this paper, we study one component of the AST, the positional encoding, and propose several variants to improve the performance of ASTs trained from scratch, without ImageNet pretraining. Our best model, which incorporates conditional positional encodings, significantly improves performance on Audioset and ESC-50 compared to the original AST.
Emotion Recognition from Speech Using Wav2vec 2.0 Embeddings
Apr 08, 2021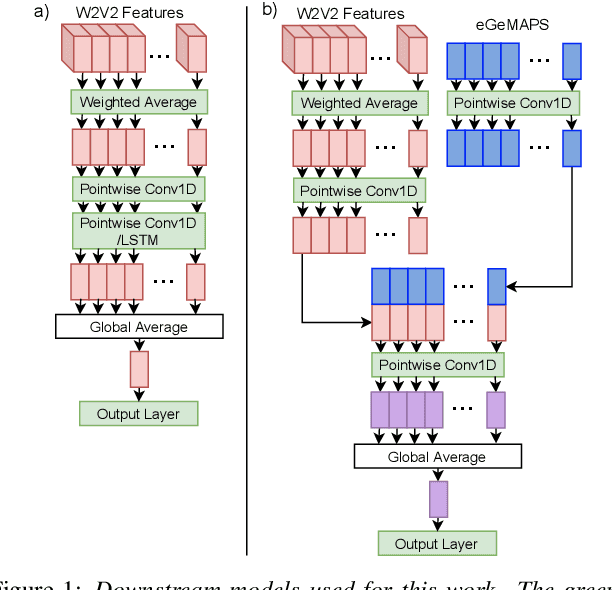
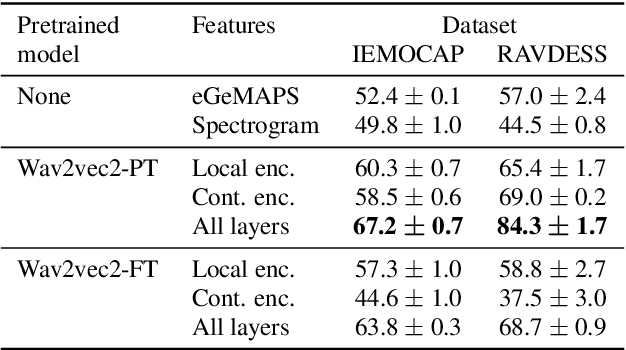
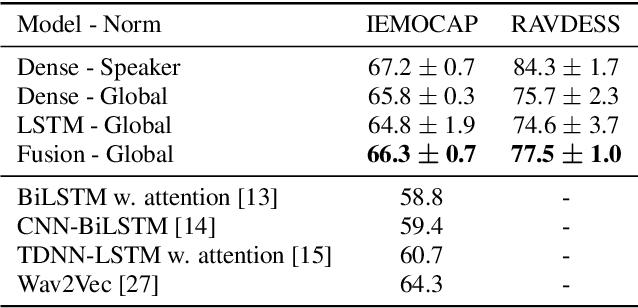
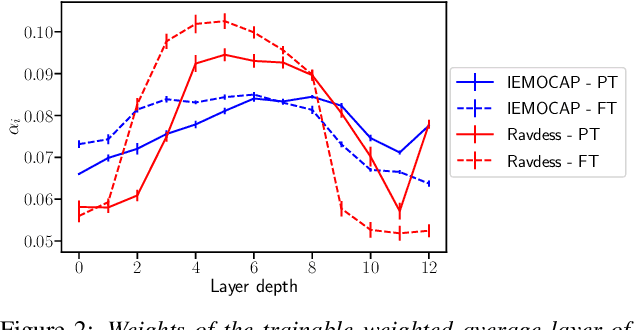
Emotion recognition datasets are relatively small, making the use of the more sophisticated deep learning approaches challenging. In this work, we propose a transfer learning method for speech emotion recognition where features extracted from pre-trained wav2vec 2.0 models are modeled using simple neural networks. We propose to combine the output of several layers from the pre-trained model using trainable weights which are learned jointly with the downstream model. Further, we compare performance using two different wav2vec 2.0 models, with and without finetuning for speech recognition. We evaluate our proposed approaches on two standard emotion databases IEMOCAP and RAVDESS, showing superior performance compared to results in the literature.
A Study on the Manifestation of Trust in Speech
Feb 09, 2021



Research has shown that trust is an essential aspect of human-computer interaction directly determining the degree to which the person is willing to use a system. An automatic prediction of the level of trust that a user has on a certain system could be used to attempt to correct potential distrust by having the system take relevant actions like, for example, apologizing or explaining its decisions. In this work, we explore the feasibility of automatically detecting the level of trust that a user has on a virtual assistant (VA) based on their speech. We developed a novel protocol for collecting speech data from subjects induced to have different degrees of trust in the skills of a VA. The protocol consists of an interactive session where the subject is asked to respond to a series of factual questions with the help of a virtual assistant. In order to induce subjects to either trust or distrust the VA's skills, they are first informed that the VA was previously rated by other users as being either good or bad; subsequently, the VA answers the subjects' questions consistently to its alleged abilities. All interactions are speech-based, with subjects and VAs communicating verbally, which allows the recording of speech produced under different trust conditions. Using this protocol, we collected a speech corpus in Argentine Spanish. We show clear evidence that the protocol effectively succeeded in influencing subjects into the desired mental state of either trusting or distrusting the agent's skills, and present results of a perceptual study of the degree of trust performed by expert listeners. Finally, we found that the subject's speech can be used to detect which type of VA they were using, which could be considered a proxy for the user's trust toward the VA's abilities, with an accuracy up to 76%, compared to a random baseline of 50%.