Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStudy of positional encoding approaches for Audio Spectrogram Transformers
Paper and Code
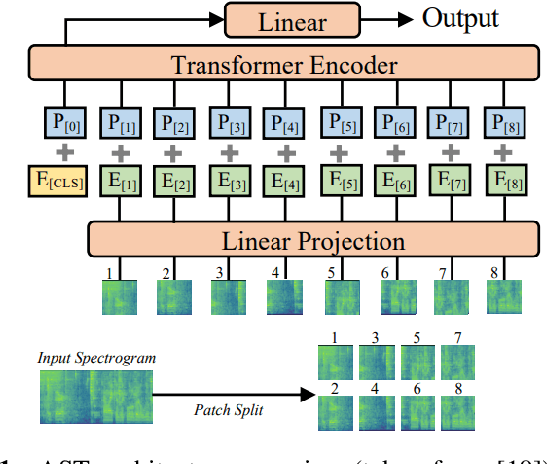
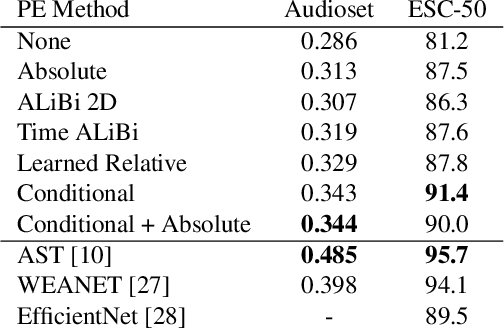
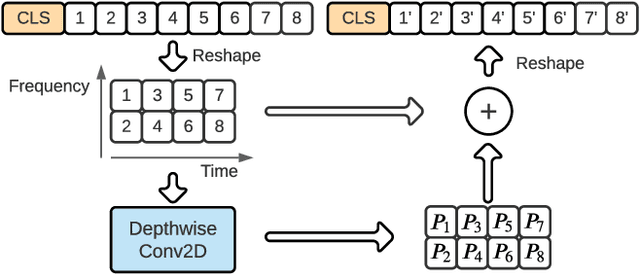
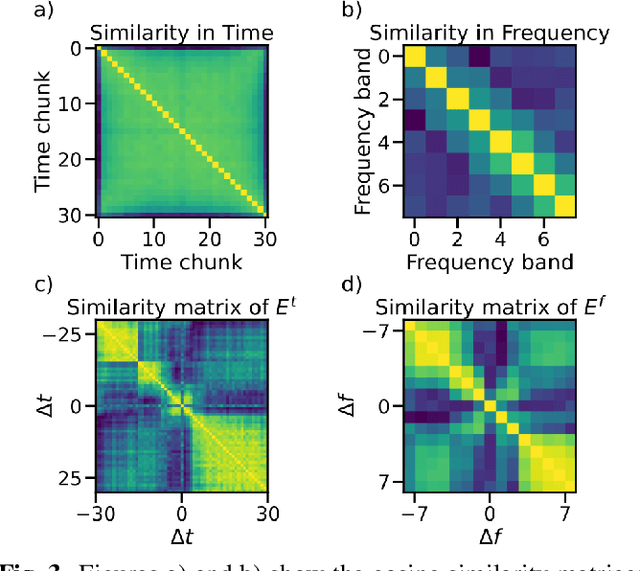
Transformers have revolutionized the world of deep learning, specially in the field of natural language processing. Recently, the Audio Spectrogram Transformer (AST) was proposed for audio classification, leading to state of the art results in several datasets. However, in order for ASTs to outperform CNNs, pretraining with ImageNet is needed. In this paper, we study one component of the AST, the positional encoding, and propose several variants to improve the performance of ASTs trained from scratch, without ImageNet pretraining. Our best model, which incorporates conditional positional encodings, significantly improves performance on Audioset and ESC-50 compared to the original AST.
* Submitted to ICASSP 2022. 5 pages, 3 figures
View paper on