 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Recognition from Speech Using Wav2vec 2.0 Embeddings
Paper and Code
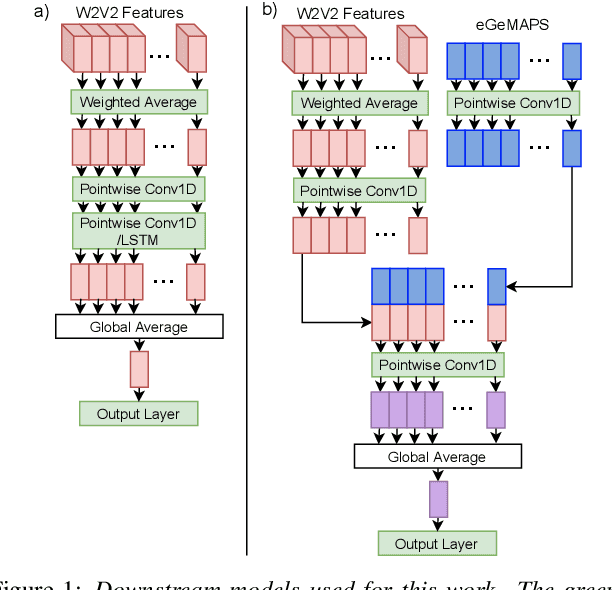
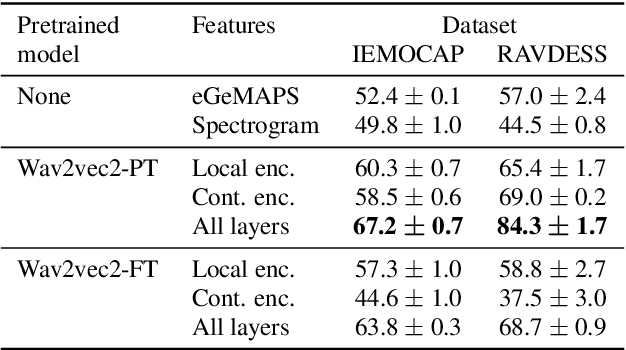
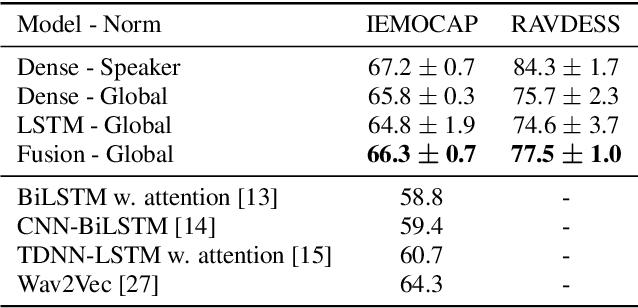
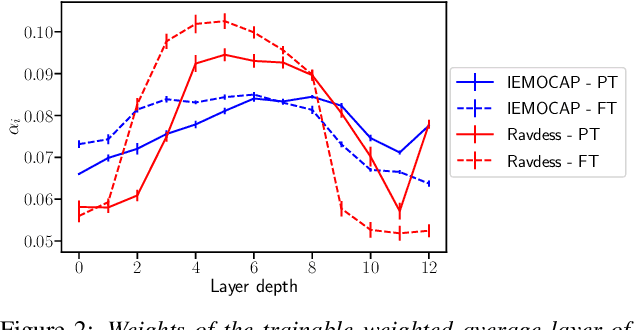
Emotion recognition datasets are relatively small, making the use of the more sophisticated deep learning approaches challenging. In this work, we propose a transfer learning method for speech emotion recognition where features extracted from pre-trained wav2vec 2.0 models are modeled using simple neural networks. We propose to combine the output of several layers from the pre-trained model using trainable weights which are learned jointly with the downstream model. Further, we compare performance using two different wav2vec 2.0 models, with and without finetuning for speech recognition. We evaluate our proposed approaches on two standard emotion databases IEMOCAP and RAVDESS, showing superior performance compared to results in the literature.