 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing multiple metrics of group fairness in data-driven decision making
Mar 10, 2020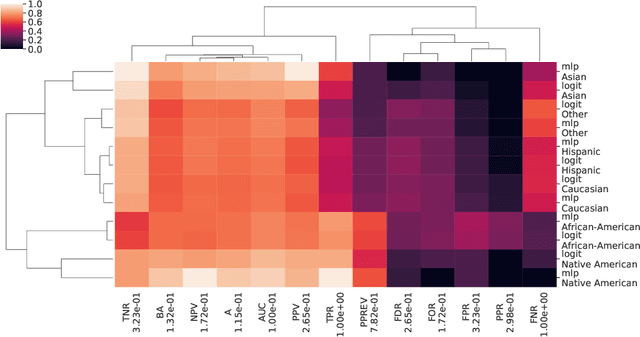

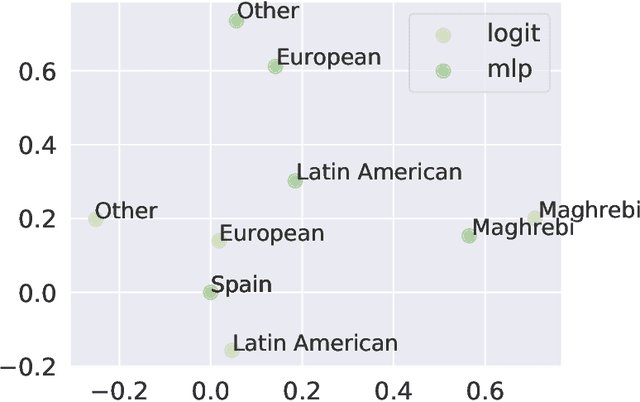
The Fairness, Accountability, and Transparency in Machine Learning (FAT-ML) literature proposes a varied set of group fairness metrics to measure discrimination against socio-demographic groups that are characterized by a protected feature, such as gender or race.Such a system can be deemed as either fair or unfair depending on the choice of the metric. Several metrics have been proposed, some of them incompatible with each other.We do so empirically, by observing that several of these metrics cluster together in two or three main clusters for the same groups and machine learning methods. In addition, we propose a robust way to visualize multidimensional fairness in two dimensions through a Principal Component Analysis (PCA) of the group fairness metrics. Experimental results on multiple datasets show that the PCA decomposition explains the variance between the metrics with one to three components.
Fair and Unbiased Algorithmic Decision Making: Current State and Future Challenges
Jan 15, 2019
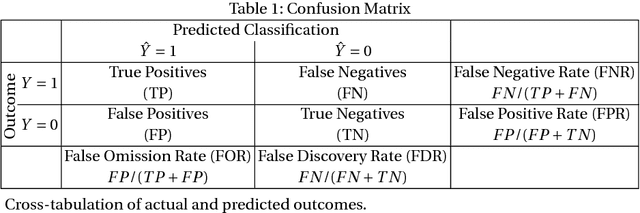
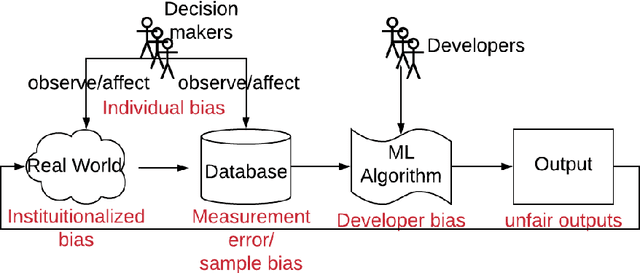
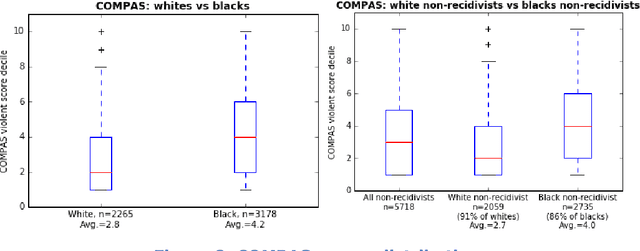
Machine learning algorithms are now frequently used in sensitive contexts that substantially affect the course of human lives, such as credit lending or criminal justice. This is driven by the idea that `objective' machines base their decisions solely on facts and remain unaffected by human cognitive biases, discriminatory tendencies or emotions. Yet, there is overwhelming evidence showing that algorithms can inherit or even perpetuate human biases in their decision making when they are based on data that contains biased human decisions. This has led to a call for fairness-aware machine learning. However, fairness is a complex concept which is also reflected in the attempts to formalize fairness for algorithmic decision making. Statistical formalizations of fairness lead to a long list of criteria that are each flawed (or harmful even) in different contexts. Moreover, inherent tradeoffs in these criteria make it impossible to unify them in one general framework. Thus, fairness constraints in algorithms have to be specific to the domains to which the algorithms are applied. In the future, research in algorithmic decision making systems should be aware of data and developer biases and add a focus on transparency to facilitate regular fairness audits.
A multidisciplinary task-based perspective for evaluating the impact of AI autonomy and generality on the future of work
Jul 06, 2018
This paper presents a multidisciplinary task approach for assessing the impact of artificial intelligence on the future of work. We provide definitions of a task from two main perspectives: socio-economic and computational. We propose to explore ways in which we can integrate or map these perspectives, and link them with the skills or capabilities required by them, for humans and AI systems. Finally, we argue that in order to understand the dynamics of tasks, we have to explore the relevance of autonomy and generality of AI systems for the automation or alteration of the workplace.
Assessing the impact of machine intelligence on human behaviour: an interdisciplinary endeavour
Jun 07, 2018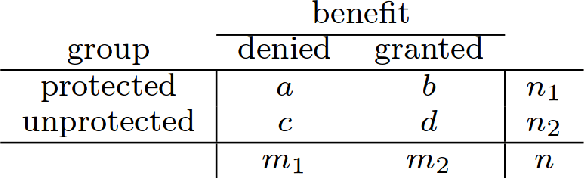
This document contains the outcome of the first Human behaviour and machine intelligence (HUMAINT) workshop that took place 5-6 March 2018 in Barcelona, Spain. The workshop was organized in the context of a new research programme at the Centre for Advanced Studies, Joint Research Centre of the European Commission, which focuses on studying the potential impact of artificial intelligence on human behaviour. The workshop gathered an interdisciplinary group of experts to establish the state of the art research in the field and a list of future research challenges to be addressed on the topic of human and machine intelligence, algorithm's potential impact on human cognitive capabilities and decision making, and evaluation and regulation needs. The document is made of short position statements and identification of challenges provided by each expert, and incorporates the result of the discussions carried out during the workshop. In the conclusion section, we provide a list of emerging research topics and strategies to be addressed in the near future.