 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubato: Transcribing Piano Music with Timestamps
May 22, 2026We consider the conversion of musical recordings into human-readable sheet music annotated with timestamps. Such output lets a listener clearly visualize rubato (temporally expressive playing), a learner diagnose ensemble precision and timing choices against the written music, and a musicology scholar compare performance styles across recordings of the same work. We introduce (1) a prompt-conditioned encoder-decoder model, named Rubato, trained to output (2) a new textual representation for polyphonic music, named InterMo, which we designed for compatibility with sequence-to-sequence training. Our experiments demonstrate that Rubato produces timestamped piano sheet music from audio with higher notational accuracy than the best existing approaches, which are based on cascades. We find that even if the cascade is given ground-truth MIDI instead of audio, Rubato performs better, suggesting that the ceiling of existing approaches is primarily representational, not acoustic. Further, because Rubato is trained on several related tasks (with prompts), it competes with or outperforms the best single-task systems on related but simpler tasks like MIDI note grounding and beat/downbeat detection. A demo is available at https://nctamer.github.io/rubato-transcription .
Automatic Estimation of Singing Voice Musical Dynamics
Oct 27, 2024



Musical dynamics form a core part of expressive singing voice performances. However, automatic analysis of musical dynamics for singing voice has received limited attention partly due to the scarcity of suitable datasets and a lack of clear evaluation frameworks. To address this challenge, we propose a methodology for dataset curation. Employing the proposed methodology, we compile a dataset comprising 509 musical dynamics annotated singing voice performances, aligned with 163 score files, leveraging state-of-the-art source separation and alignment techniques. The scores are sourced from the OpenScore Lieder corpus of romantic-era compositions, widely known for its wealth of expressive annotations. Utilizing the curated dataset, we train a multi-head attention based CNN model with varying window sizes to evaluate the effectiveness of estimating musical dynamics. We explored two distinct perceptually motivated input representations for the model training: log-Mel spectrum and bark-scale based features. For testing, we manually curate another dataset of 25 musical dynamics annotated performances in collaboration with a professional vocalist. We conclude through our experiments that bark-scale based features outperform log-Mel-features for the task of singing voice dynamics prediction. The dataset along with the code is shared publicly for further research on the topic.
Combining piano performance dimensions for score difficulty classification
Jun 14, 2023



Predicting the difficulty of playing a musical score is essential for structuring and exploring score collections. Despite its importance for music education, the automatic difficulty classification of piano scores is not yet solved, mainly due to the lack of annotated data and the subjectiveness of the annotations. This paper aims to advance the state-of-the-art in score difficulty classification with two major contributions. To address the lack of data, we present Can I Play It? (CIPI) dataset, a machine-readable piano score dataset with difficulty annotations obtained from the renowned classical music publisher Henle Verlag. The dataset is created by matching public domain scores with difficulty labels from Henle Verlag, then reviewed and corrected by an expert pianist. As a second contribution, we explore various input representations from score information to pre-trained ML models for piano fingering and expressiveness inspired by the musicology definition of performance. We show that combining the outputs of multiple classifiers performs better than the classifiers on their own, pointing to the fact that the representations capture different aspects of difficulty. In addition, we conduct numerous experiments that lay a foundation for score difficulty classification and create a basis for future research. Our best-performing model reports a 39.47% balanced accuracy and 1.13 median square error across the nine difficulty levels proposed in this study. Code, dataset, and models are made available for reproducibility.
Score difficulty analysis for piano performance education based on fingering
Mar 24, 2022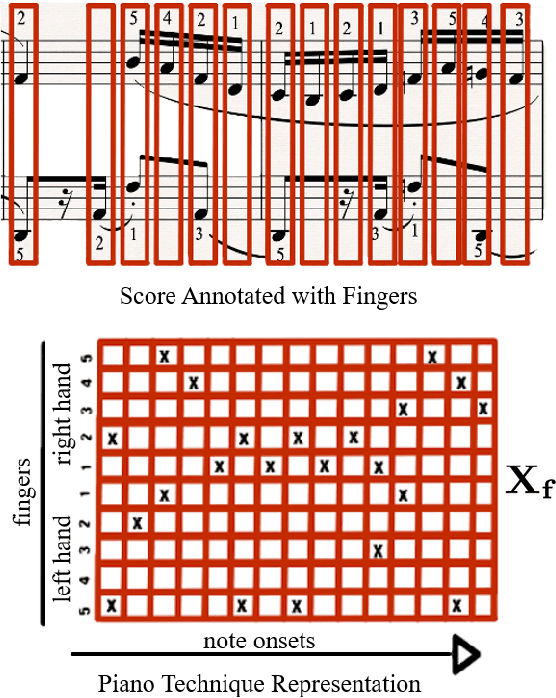

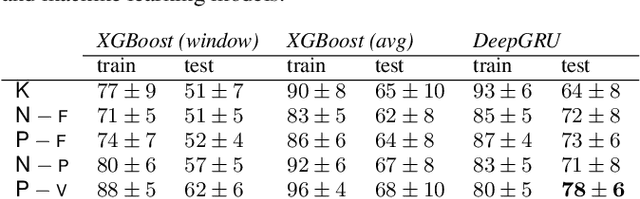
In this paper, we introduce score difficulty classification as a sub-task of music information retrieval (MIR), which may be used in music education technologies, for personalised curriculum generation, and score retrieval. We introduce a novel dataset for our task, Mikrokosmos-difficulty, containing 147 piano pieces in symbolic representation and the corresponding difficulty labels derived by its composer B\'ela Bart\'ok and the publishers. As part of our methodology, we propose piano technique feature representations based on different piano fingering algorithms. We use these features as input for two classifiers: a Gated Recurrent Unit neural network (GRU) with attention mechanism and gradient-boosted trees trained on score segments. We show that for our dataset fingering based features perform better than a simple baseline considering solely the notes in the score. Furthermore, the GRU with attention mechanism classifier surpasses the gradient-boosted trees. Our proposed models are interpretable and are capable of generating difficulty feedback both locally, on short term segments, and globally, for whole pieces. Code, datasets, models, and an online demo are made available for reproducibility