 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled 3D Scene Generation with Layout Learning
Feb 26, 2024We introduce a method to generate 3D scenes that are disentangled into their component objects. This disentanglement is unsupervised, relying only on the knowledge of a large pretrained text-to-image model. Our key insight is that objects can be discovered by finding parts of a 3D scene that, when rearranged spatially, still produce valid configurations of the same scene. Concretely, our method jointly optimizes multiple NeRFs from scratch - each representing its own object - along with a set of layouts that composite these objects into scenes. We then encourage these composited scenes to be in-distribution according to the image generator. We show that despite its simplicity, our approach successfully generates 3D scenes decomposed into individual objects, enabling new capabilities in text-to-3D content creation. For results and an interactive demo, see our project page at https://dave.ml/layoutlearning/
Diffusion Self-Guidance for Controllable Image Generation
Jun 11, 2023Large-scale generative models are capable of producing high-quality images from detailed text descriptions. However, many aspects of an image are difficult or impossible to convey through text. We introduce self-guidance, a method that provides greater control over generated images by guiding the internal representations of diffusion models. We demonstrate that properties such as the shape, location, and appearance of objects can be extracted from these representations and used to steer sampling. Self-guidance works similarly to classifier guidance, but uses signals present in the pretrained model itself, requiring no additional models or training. We show how a simple set of properties can be composed to perform challenging image manipulations, such as modifying the position or size of objects, merging the appearance of objects in one image with the layout of another, composing objects from many images into one, and more. We also show that self-guidance can be used to edit real images. For results and an interactive demo, see our project page at https://dave.ml/selfguidance/
BlobGAN: Spatially Disentangled Scene Representations
May 05, 2022

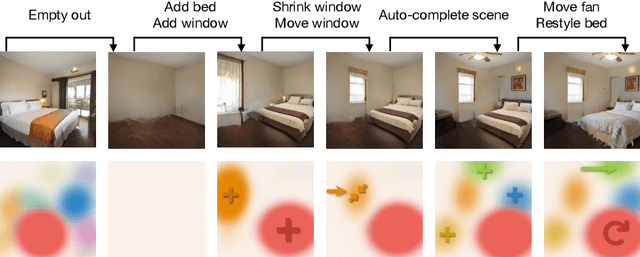
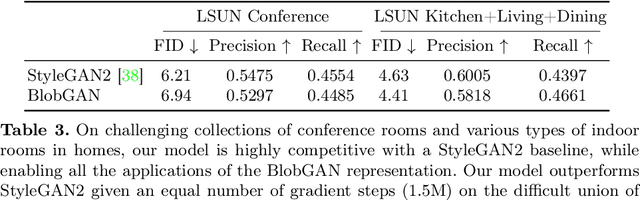
We propose an unsupervised, mid-level representation for a generative model of scenes. The representation is mid-level in that it is neither per-pixel nor per-image; rather, scenes are modeled as a collection of spatial, depth-ordered "blobs" of features. Blobs are differentiably placed onto a feature grid that is decoded into an image by a generative adversarial network. Due to the spatial uniformity of blobs and the locality inherent to convolution, our network learns to associate different blobs with different entities in a scene and to arrange these blobs to capture scene layout. We demonstrate this emergent behavior by showing that, despite training without any supervision, our method enables applications such as easy manipulation of objects within a scene (e.g., moving, removing, and restyling furniture), creation of feasible scenes given constraints (e.g., plausible rooms with drawers at a particular location), and parsing of real-world images into constituent parts. On a challenging multi-category dataset of indoor scenes, BlobGAN outperforms StyleGAN2 in image quality as measured by FID. See our project page for video results and interactive demo: http://www.dave.ml/blobgan
Learning Temporal Dynamics from Cycles in Narrated Video
Jan 07, 2021
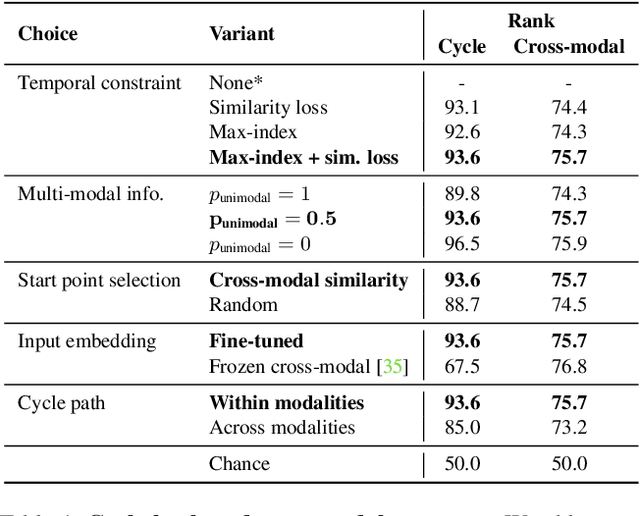
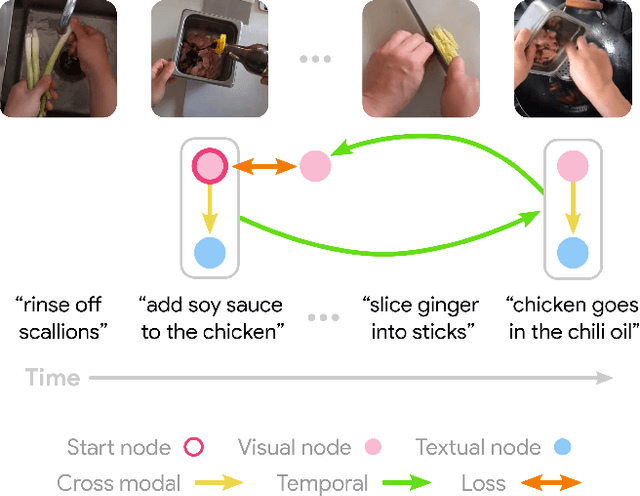

Learning to model how the world changes as time elapses has proven a challenging problem for the computer vision community. We propose a self-supervised solution to this problem using temporal cycle consistency jointly in vision and language, training on narrated video. Our model learns modality-agnostic functions to predict forward and backward in time, which must undo each other when composed. This constraint leads to the discovery of high-level transitions between moments in time, since such transitions are easily inverted and shared across modalities. We justify the design of our model with an ablation study on different configurations of the cycle consistency problem. We then show qualitatively and quantitatively that our approach yields a meaningful, high-level model of the future and past. We apply the learned dynamics model without further training to various tasks, such as predicting future action and temporally ordering sets of images.
Globetrotter: Unsupervised Multilingual Translation from Visual Alignment
Dec 08, 2020

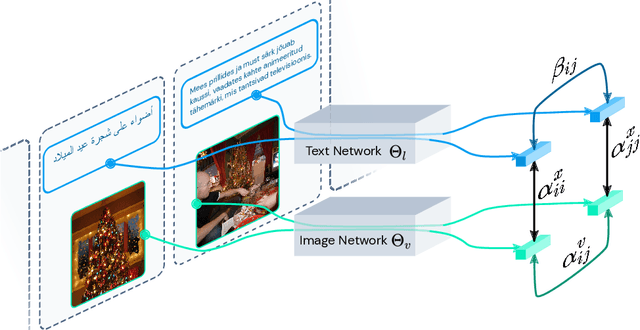

Multi-language machine translation without parallel corpora is challenging because there is no explicit supervision between languages. Existing unsupervised methods typically rely on topological properties of the language representations. We introduce a framework that instead uses the visual modality to align multiple languages, using images as the bridge between them. We estimate the cross-modal alignment between language and images, and use this estimate to guide the learning of cross-lingual representations. Our language representations are trained jointly in one model with a single stage. Experiments with fifty-two languages show that our method outperforms baselines on unsupervised word-level and sentence-level translation using retrieval.
Video Representations of Goals Emerge from Watching Failure
Jun 28, 2020
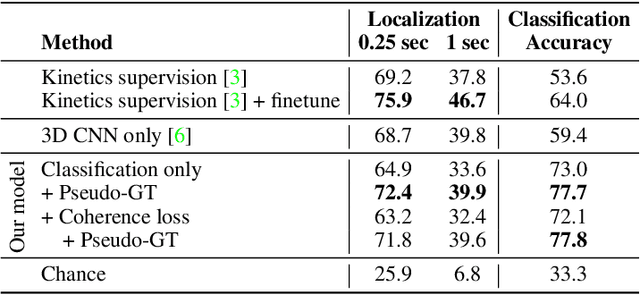
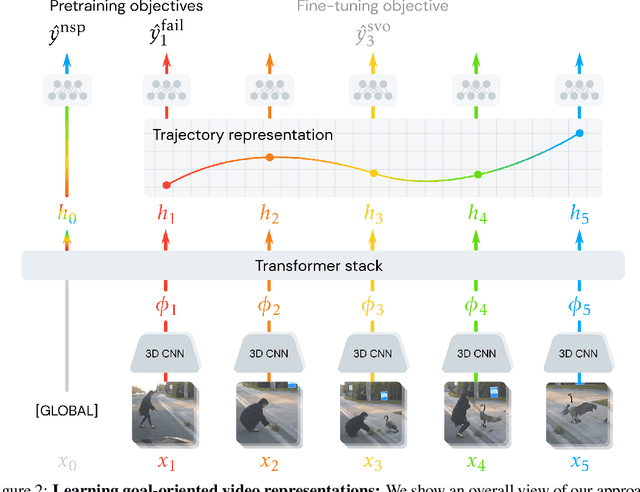
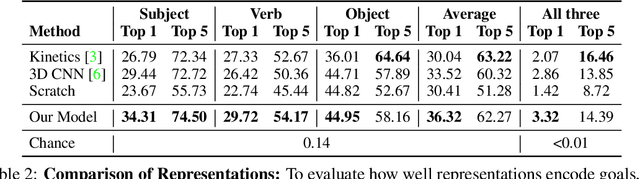
We introduce a video representation learning framework that models the latent goals behind observable human action. Motivated by how children learn to reason about goals and intentions by experiencing failure, we leverage unconstrained video of unintentional action to learn without direct supervision. Our approach models videos as contextual trajectories that represent both low-level motion and high-level action features. Experiments and visualizations show the model is able to predict underlying goals, detect when action switches from intentional to unintentional, and automatically correct unintentional action. Although the model is trained with minimal supervision, it is competitive with highly-supervised baselines, underscoring the role of failure examples for learning goal-oriented video representations. The project website is available at https://aha.cs.columbia.edu/
Learning to Learn Words from Narrated Video
Nov 25, 2019
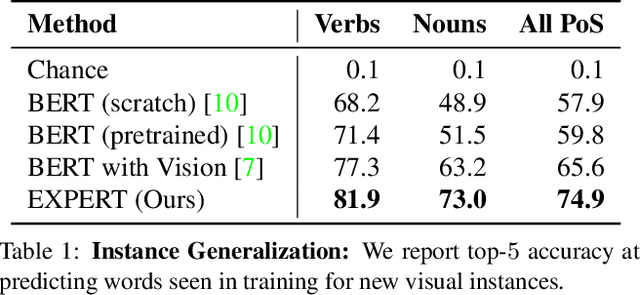

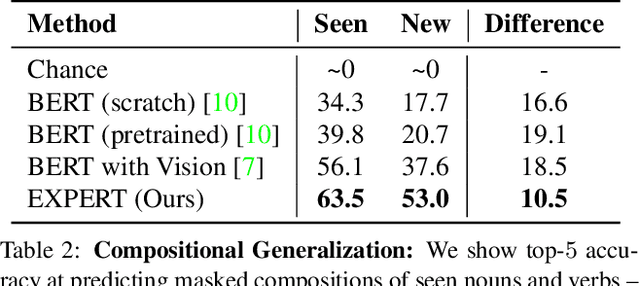
When we travel, we often encounter new scenarios we have never experienced before, with new sights and new words that describe them. We can use our language-learning ability to quickly learn these new words and correlate them with the visual world. In contrast, language models often do not robustly generalize to novel words and compositions. We propose a framework that learns how to learn text representations from visual context. Experiments show that our approach significantly outperforms the state-of-the-art in visual language modeling for acquiring new words and predicting new compositions. Model ablations and visualizations suggest that the visual modality helps our approach more robustly generalize at these tasks. Project webpage is available at https://expert.cs.columbia.edu/
Oops! Predicting Unintentional Action in Video
Nov 25, 2019



From just a short glance at a video, we can often tell whether a person's action is intentional or not. Can we train a model to recognize this? We introduce a dataset of in-the-wild videos of unintentional action, as well as a suite of tasks for recognizing, localizing, and anticipating its onset. We train a supervised neural network as a baseline and analyze its performance compared to human consistency on the tasks. We also investigate self-supervised representations that leverage natural signals in our dataset, and show the effectiveness of an approach that uses the intrinsic speed of video to perform competitively with highly-supervised pretraining. However, a significant gap between machine and human performance remains. The project website is available at https://oops.cs.columbia.edu
NEUZZ: Efficient Fuzzing with NeuralProgram Smoothing
Nov 04, 2018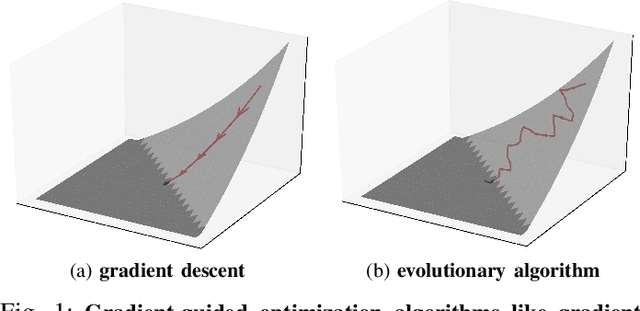
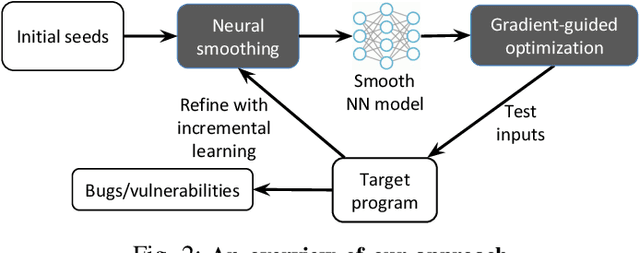
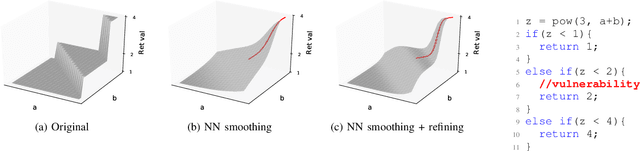
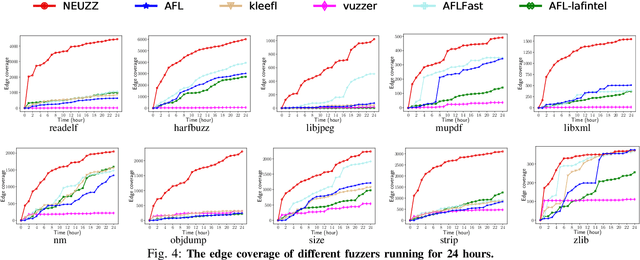
Fuzzing has become the de facto standard technique for finding software vulnerabilities. However, even state-of-the-art fuzzers are not very efficient at finding hard-to-trigger software bugs. Most popular fuzzers use evolutionary guidance to generate inputs that can trigger different bugs. Such evolutionary algorithms, while fast and simple to implement, often get stuck in fruitless sequences of random mutations. Gradient-guided optimization presents a promising alternative to evolutionary guidance. Gradient-guided techniques have been shown to significantly outperform evolutionary algorithms at solving high-dimensional structured optimization problems in domains like machine learning by efficiently utilizing gradients or higher-order derivatives of the underlying function. However, gradient-guided approaches are not directly applicable to fuzzing as real-world program behaviors contain many discontinuities, plateaus, and ridges where the gradient-based methods often get stuck. We observe that this problem can be addressed by creating a smooth surrogate function approximating the discrete branching behavior of target program. In this paper, we propose a novel program smoothing technique using surrogate neural network models that can incrementally learn smooth approximations of a complex, real-world program's branching behaviors. We further demonstrate that such neural network models can be used together with gradient-guided input generation schemes to significantly improve the fuzzing efficiency. Our extensive evaluations demonstrate that NEUZZ significantly outperforms 10 state-of-the-art graybox fuzzers on 10 real-world programs both at finding new bugs and achieving higher edge coverage. NEUZZ found 31 unknown bugs that other fuzzers failed to find in 10 real world programs and achieved 3X more edge coverage than all of the tested graybox fuzzers for 24 hours running.