 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Alignment Isn't Enough: Response-Path Attacks on LLM Agents
May 04, 2026Bring-Your-Own-Key (BYOK) agent architectures let users route LLM traffic through third-party relays, creating a critical integrity gap: a malicious relay can modify an aligned LLM response after generation but before agent execution. We formalize this post-alignment tampering threat and show that, without end-to-end integrity, the relay can observe, suppress, or replace downstream messages, making even perfectly aligned LLMs ineffective against such attacks. We instantiate this threat as the Relay Tampering Attack (RTA), which performs multi-round strategic rewriting, minimal security-critical edits, and stealth restoration by resubmitting tampered outputs to the upstream LLM. Across AgentDojo and ASB with six LLMs, RTA achieves up to 99.1% attack success, outperforming prompt-injection baselines with modest overhead. Case studies on OpenClaw and Claude Code demonstrate real-world feasibility, and evaluations of four defenses show that none fully prevent RTA. Finally, we propose a time-based detection defense that mitigates RTA while preserving agent utility.
On Protecting Agentic Systems' Intellectual Property via Watermarking
Feb 09, 2026The evolution of Large Language Models (LLMs) into agentic systems that perform autonomous reasoning and tool use has created significant intellectual property (IP) value. We demonstrate that these systems are highly vulnerable to imitation attacks, where adversaries steal proprietary capabilities by training imitation models on victim outputs. Crucially, existing LLM watermarking techniques fail in this domain because real-world agentic systems often operate as grey boxes, concealing the internal reasoning traces required for verification. This paper presents AGENTWM, the first watermarking framework designed specifically for agentic models. AGENTWM exploits the semantic equivalence of action sequences, injecting watermarks by subtly biasing the distribution of functionally identical tool execution paths. This mechanism allows AGENTWM to embed verifiable signals directly into the visible action trajectory while remaining indistinguishable to users. We develop an automated pipeline to generate robust watermark schemes and a rigorous statistical hypothesis testing procedure for verification. Extensive evaluations across three complex domains demonstrate that AGENTWM achieves high detection accuracy with negligible impact on agent performance. Our results confirm that AGENTWM effectively protects agentic IP against adaptive adversaries, who cannot remove the watermarks without severely degrading the stolen model's utility.
From Similarity to Vulnerability: Key Collision Attack on LLM Semantic Caching
Jan 30, 2026Semantic caching has emerged as a pivotal technique for scaling LLM applications, widely adopted by major providers including AWS and Microsoft. By utilizing semantic embedding vectors as cache keys, this mechanism effectively minimizes latency and redundant computation for semantically similar queries. In this work, we conceptualize semantic cache keys as a form of fuzzy hashes. We demonstrate that the locality required to maximize cache hit rates fundamentally conflicts with the cryptographic avalanche effect necessary for collision resistance. Our conceptual analysis formalizes this inherent trade-off between performance (locality) and security (collision resilience), revealing that semantic caching is naturally vulnerable to key collision attacks. While prior research has focused on side-channel and privacy risks, we present the first systematic study of integrity risks arising from cache collisions. We introduce CacheAttack, an automated framework for launching black-box collision attacks. We evaluate CacheAttack in security-critical tasks and agentic workflows. It achieves a hit rate of 86\% in LLM response hijacking and can induce malicious behaviors in LLM agent, while preserving strong transferability across different embedding models. A case study on a financial agent further illustrates the real-world impact of these vulnerabilities. Finally, we discuss mitigation strategies.
CompressionAttack: Exploiting Prompt Compression as a New Attack Surface in LLM-Powered Agents
Oct 27, 2025LLM-powered agents often use prompt compression to reduce inference costs, but this introduces a new security risk. Compression modules, which are optimized for efficiency rather than safety, can be manipulated by adversarial inputs, causing semantic drift and altering LLM behavior. This work identifies prompt compression as a novel attack surface and presents CompressionAttack, the first framework to exploit it. CompressionAttack includes two strategies: HardCom, which uses discrete adversarial edits for hard compression, and SoftCom, which performs latent-space perturbations for soft compression. Experiments on multiple LLMs show up to 80% attack success and 98% preference flips, while remaining highly stealthy and transferable. Case studies in VSCode Cline and Ollama confirm real-world impact, and current defenses prove ineffective, highlighting the need for stronger protections.
NeuDep: Neural Binary Memory Dependence Analysis
Oct 04, 2022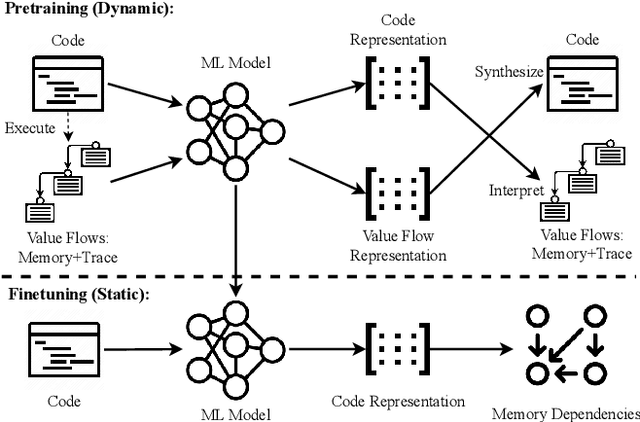

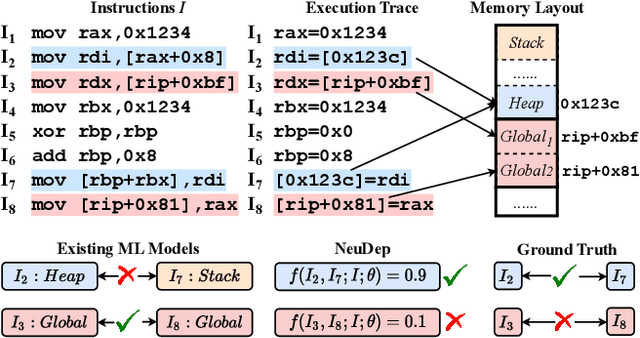
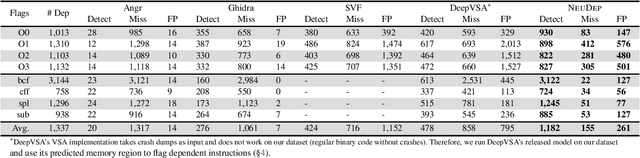
Determining whether multiple instructions can access the same memory location is a critical task in binary analysis. It is challenging as statically computing precise alias information is undecidable in theory. The problem aggravates at the binary level due to the presence of compiler optimizations and the absence of symbols and types. Existing approaches either produce significant spurious dependencies due to conservative analysis or scale poorly to complex binaries. We present a new machine-learning-based approach to predict memory dependencies by exploiting the model's learned knowledge about how binary programs execute. Our approach features (i) a self-supervised procedure that pretrains a neural net to reason over binary code and its dynamic value flows through memory addresses, followed by (ii) supervised finetuning to infer the memory dependencies statically. To facilitate efficient learning, we develop dedicated neural architectures to encode the heterogeneous inputs (i.e., code, data values, and memory addresses from traces) with specific modules and fuse them with a composition learning strategy. We implement our approach in NeuDep and evaluate it on 41 popular software projects compiled by 2 compilers, 4 optimizations, and 4 obfuscation passes. We demonstrate that NeuDep is more precise (1.5x) and faster (3.5x) than the current state-of-the-art. Extensive probing studies on security-critical reverse engineering tasks suggest that NeuDep understands memory access patterns, learns function signatures, and is able to match indirect calls. All these tasks either assist or benefit from inferring memory dependencies. Notably, NeuDep also outperforms the current state-of-the-art on these tasks.
On Training Robust PDF Malware Classifiers
Apr 06, 2019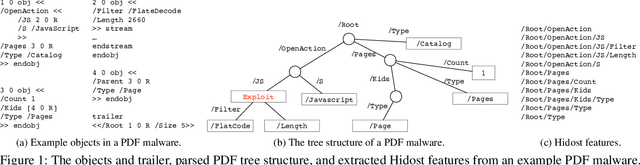


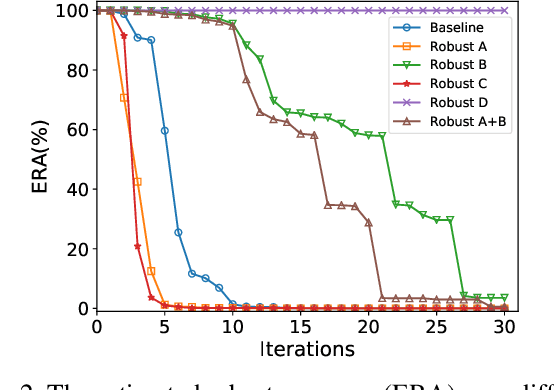
Although state-of-the-art PDF malware classifiers can be trained with almost perfect test accuracy (99%) and extremely low false positive rate (under 0.1%), it has been shown that even a simple adversary can evade them. A practically useful malware classifier must be robust against evasion attacks. However, achieving such robustness is an extremely challenging task. In this paper, we take the first steps towards training robust PDF malware classifiers with verifiable robustness properties. For instance, a robustness property can enforce that no matter how many pages from benign documents are inserted into a PDF malware, the classifier must still classify it as malicious. We demonstrate how the worst-case behavior of a malware classifier with respect to specific robustness properties can be formally verified. Furthermore, we find that training classifiers that satisfy formally verified robustness properties can increase the computation cost of unbounded (i.e., not bounded by the robustness properties) attackers by eliminating simple evasion attacks. Specifically, we propose a new distance metric that operates on the PDF tree structure and specify two classes of robustness properties including subtree insertions and deletions. We utilize state-of-the-art verifiably robust training method to build robust PDF malware classifiers. Our results show that, we can achieve 99% verified robust accuracy, while maintaining 99.80% accuracy and 0.41% false positive rate. With simple robustness properties, the state-of-the-art unbounded attacker found no successful evasion on the robust classifier in 6 hours. Even for a new unbounded adaptive attacker we have designed, the number of successful evasions within a fixed time budget is cut down by 4x.
NEUZZ: Efficient Fuzzing with NeuralProgram Smoothing
Nov 04, 2018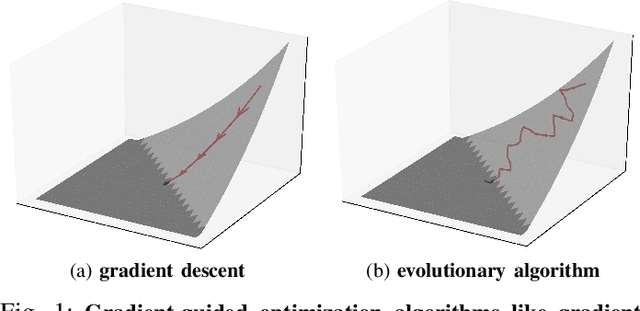
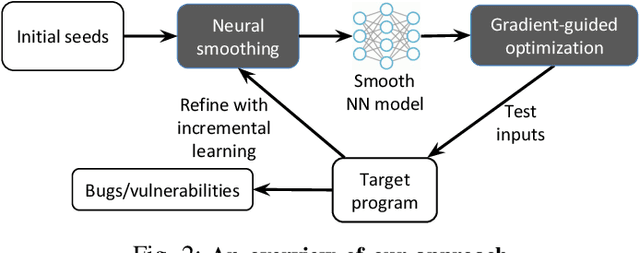
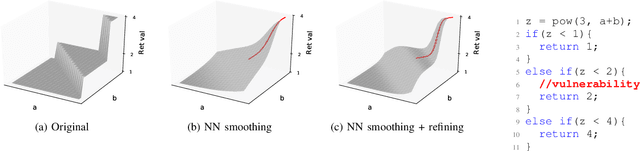
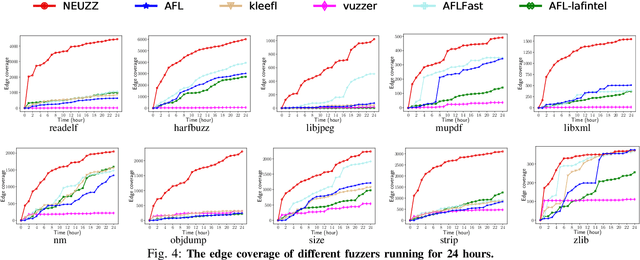
Fuzzing has become the de facto standard technique for finding software vulnerabilities. However, even state-of-the-art fuzzers are not very efficient at finding hard-to-trigger software bugs. Most popular fuzzers use evolutionary guidance to generate inputs that can trigger different bugs. Such evolutionary algorithms, while fast and simple to implement, often get stuck in fruitless sequences of random mutations. Gradient-guided optimization presents a promising alternative to evolutionary guidance. Gradient-guided techniques have been shown to significantly outperform evolutionary algorithms at solving high-dimensional structured optimization problems in domains like machine learning by efficiently utilizing gradients or higher-order derivatives of the underlying function. However, gradient-guided approaches are not directly applicable to fuzzing as real-world program behaviors contain many discontinuities, plateaus, and ridges where the gradient-based methods often get stuck. We observe that this problem can be addressed by creating a smooth surrogate function approximating the discrete branching behavior of target program. In this paper, we propose a novel program smoothing technique using surrogate neural network models that can incrementally learn smooth approximations of a complex, real-world program's branching behaviors. We further demonstrate that such neural network models can be used together with gradient-guided input generation schemes to significantly improve the fuzzing efficiency. Our extensive evaluations demonstrate that NEUZZ significantly outperforms 10 state-of-the-art graybox fuzzers on 10 real-world programs both at finding new bugs and achieving higher edge coverage. NEUZZ found 31 unknown bugs that other fuzzers failed to find in 10 real world programs and achieved 3X more edge coverage than all of the tested graybox fuzzers for 24 hours running.