 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
DORSal: Diffusion for Object-centric Representations of Scenes $\textit{et al.}$
Jun 13, 2023Recent progress in 3D scene understanding enables scalable learning of representations across large datasets of diverse scenes. As a consequence, generalization to unseen scenes and objects, rendering novel views from just a single or a handful of input images, and controllable scene generation that supports editing, is now possible. However, training jointly on a large number of scenes typically compromises rendering quality when compared to single-scene optimized models such as NeRFs. In this paper, we leverage recent progress in diffusion models to equip 3D scene representation learning models with the ability to render high-fidelity novel views, while retaining benefits such as object-level scene editing to a large degree. In particular, we propose DORSal, which adapts a video diffusion architecture for 3D scene generation conditioned on object-centric slot-based representations of scenes. On both complex synthetic multi-object scenes and on the real-world large-scale Street View dataset, we show that DORSal enables scalable neural rendering of 3D scenes with object-level editing and improves upon existing approaches.
Diffusion Self-Guidance for Controllable Image Generation
Jun 11, 2023Large-scale generative models are capable of producing high-quality images from detailed text descriptions. However, many aspects of an image are difficult or impossible to convey through text. We introduce self-guidance, a method that provides greater control over generated images by guiding the internal representations of diffusion models. We demonstrate that properties such as the shape, location, and appearance of objects can be extracted from these representations and used to steer sampling. Self-guidance works similarly to classifier guidance, but uses signals present in the pretrained model itself, requiring no additional models or training. We show how a simple set of properties can be composed to perform challenging image manipulations, such as modifying the position or size of objects, merging the appearance of objects in one image with the layout of another, composing objects from many images into one, and more. We also show that self-guidance can be used to edit real images. For results and an interactive demo, see our project page at https://dave.ml/selfguidance/
MIMEx: Intrinsic Rewards from Masked Input Modeling
May 15, 2023
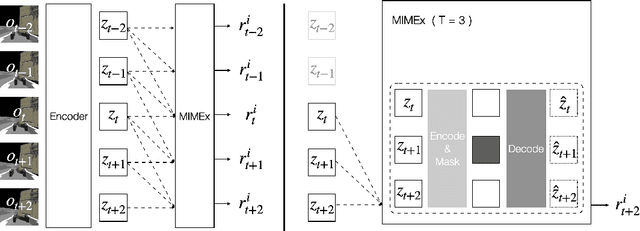
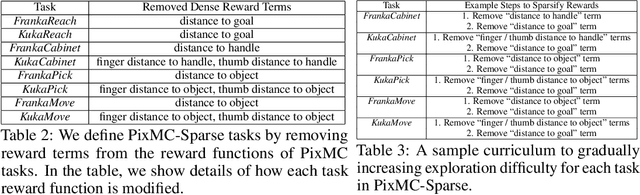
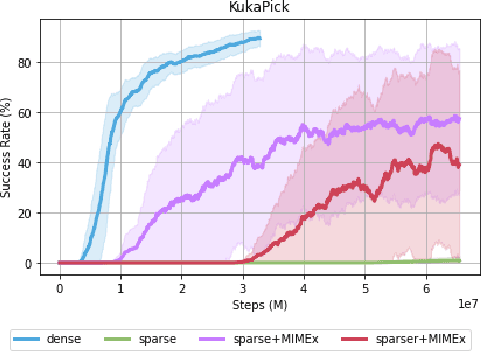
Exploring in environments with high-dimensional observations is hard. One promising approach for exploration is to use intrinsic rewards, which often boils down to estimating "novelty" of states, transitions, or trajectories with deep networks. Prior works have shown that conditional prediction objectives such as masked autoencoding can be seen as stochastic estimation of pseudo-likelihood. We show how this perspective naturally leads to a unified view on existing intrinsic reward approaches: they are special cases of conditional prediction, where the estimation of novelty can be seen as pseudo-likelihood estimation with different mask distributions. From this view, we propose a general framework for deriving intrinsic rewards -- Masked Input Modeling for Exploration (MIMEx) -- where the mask distribution can be flexibly tuned to control the difficulty of the underlying conditional prediction task. We demonstrate that MIMEx can achieve superior results when compared against competitive baselines on a suite of challenging sparse-reward visuomotor tasks.
Scalable Adaptive Computation for Iterative Generation
Dec 22, 2022



We present the Recurrent Interface Network (RIN), a neural net architecture that allocates computation adaptively to the input according to the distribution of information, allowing it to scale to iterative generation of high-dimensional data. Hidden units of RINs are partitioned into the interface, which is locally connected to inputs, and latents, which are decoupled from inputs and can exchange information globally. The RIN block selectively reads from the interface into latents for high-capacity processing, with incremental updates written back to the interface. Stacking multiple blocks enables effective routing across local and global levels. While routing adds overhead, the cost can be amortized in recurrent computation settings where inputs change gradually while more global context persists, such as iterative generation using diffusion models. To this end, we propose a latent self-conditioning technique that "warm-starts" the latents at each iteration of the generation process. When applied to diffusion models operating directly on pixels, RINs yield state-of-the-art image and video generation without cascades or guidance, while being domain-agnostic and up to 10$\times$ more efficient compared to specialized 2D and 3D U-Nets.
Object Permanence Emerges in a Random Walk along Memory
Apr 04, 2022
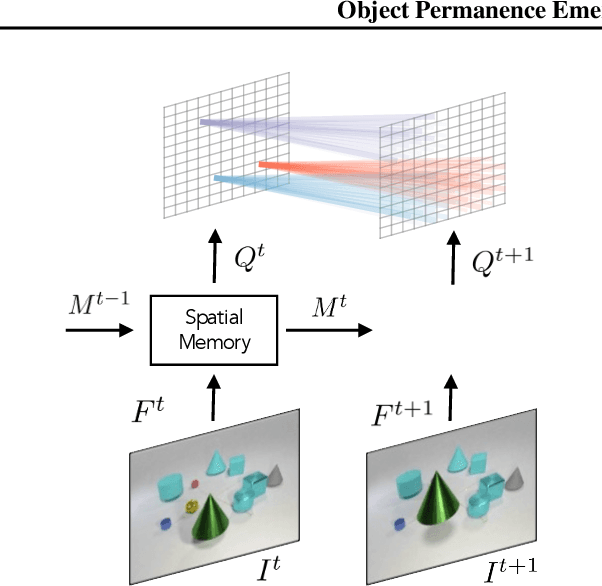

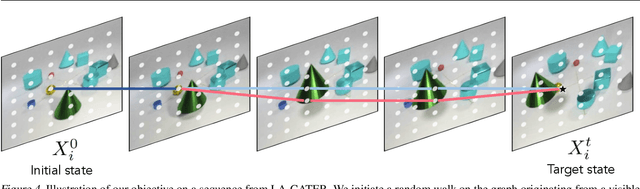
This paper proposes a self-supervised objective for learning representations that localize objects under occlusion - a property known as object permanence. A central question is the choice of learning signal in cases of total occlusion. Rather than directly supervising the locations of invisible objects, we propose a self-supervised objective that requires neither human annotation, nor assumptions about object dynamics. We show that object permanence can emerge by optimizing for temporal coherence of memory: we fit a Markov walk along a space-time graph of memories, where the states in each time step are non-Markovian features from a sequence encoder. This leads to a memory representation that stores occluded objects and predicts their motion, to better localize them. The resulting model outperforms existing approaches on several datasets of increasing complexity and realism, despite requiring minimal supervision and assumptions, and hence being broadly applicable.
Discovering Objects that Can Move
Mar 18, 2022
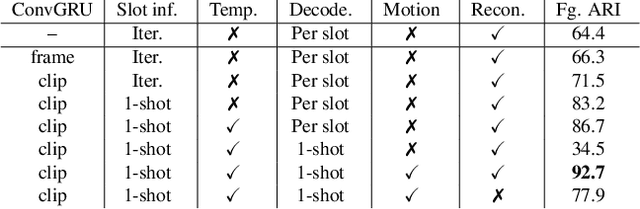
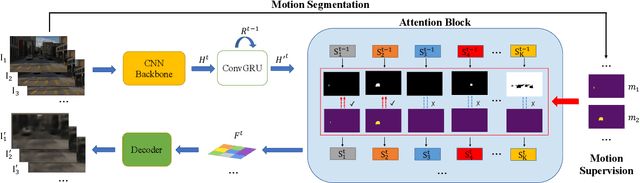
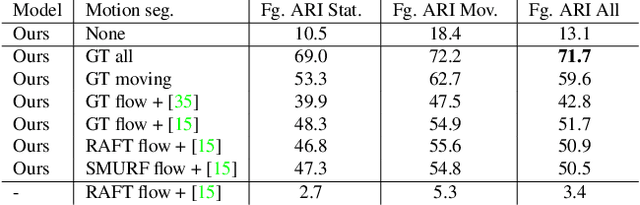
This paper studies the problem of object discovery -- separating objects from the background without manual labels. Existing approaches utilize appearance cues, such as color, texture, and location, to group pixels into object-like regions. However, by relying on appearance alone, these methods fail to separate objects from the background in cluttered scenes. This is a fundamental limitation since the definition of an object is inherently ambiguous and context-dependent. To resolve this ambiguity, we choose to focus on dynamic objects -- entities that can move independently in the world. We then scale the recent auto-encoder based frameworks for unsupervised object discovery from toy synthetic images to complex real-world scenes. To this end, we simplify their architecture, and augment the resulting model with a weak learning signal from general motion segmentation algorithms. Our experiments demonstrate that, despite only capturing a small subset of the objects that move, this signal is enough to generalize to segment both moving and static instances of dynamic objects. We show that our model scales to a newly collected, photo-realistic synthetic dataset with street driving scenarios. Additionally, we leverage ground truth segmentation and flow annotations in this dataset for thorough ablation and evaluation. Finally, our experiments on the real-world KITTI benchmark demonstrate that the proposed approach outperforms both heuristic- and learning-based methods by capitalizing on motion cues.
Learning Pixel Trajectories with Multiscale Contrastive Random Walks
Jan 20, 2022
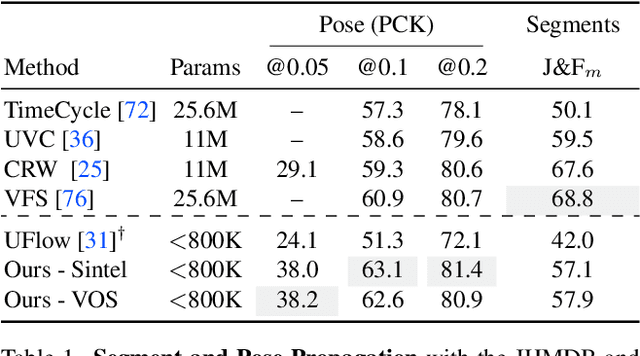
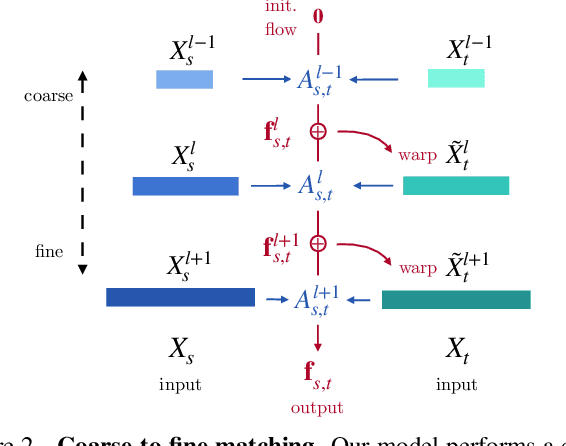

A range of video modeling tasks, from optical flow to multiple object tracking, share the same fundamental challenge: establishing space-time correspondence. Yet, approaches that dominate each space differ. We take a step towards bridging this gap by extending the recent contrastive random walk formulation to much denser, pixel-level space-time graphs. The main contribution is introducing hierarchy into the search problem by computing the transition matrix between two frames in a coarse-to-fine manner, forming a multiscale contrastive random walk when extended in time. This establishes a unified technique for self-supervised learning of optical flow, keypoint tracking, and video object segmentation. Experiments demonstrate that, for each of these tasks, the unified model achieves performance competitive with strong self-supervised approaches specific to that task. Project site: https://jasonbian97.github.io/flowwalk
Space-Time Correspondence as a Contrastive Random Walk
Jun 25, 2020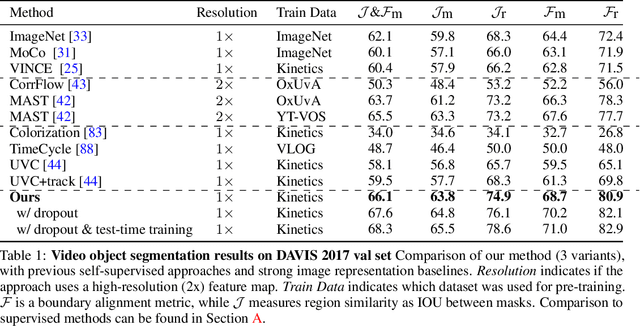
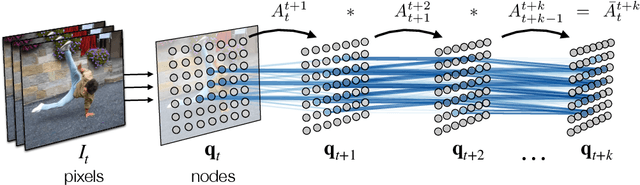

This paper proposes a simple self-supervised approach for learning representations for visual correspondence from raw video. We cast correspondence as link prediction in a space-time graph constructed from a video. In this graph, the nodes are patches sampled from each frame, and nodes adjacent in time can share a directed edge. We learn a node embedding in which pairwise similarity defines transition probabilities of a random walk. Prediction of long-range correspondence is efficiently computed as a walk along this graph. The embedding learns to guide the walk by placing high probability along paths of correspondence. Targets are formed without supervision, by cycle-consistency: we train the embedding to maximize the likelihood of returning to the initial node when walking along a graph constructed from a `palindrome' of frames. We demonstrate that the approach allows for learning representations from large unlabeled video. Despite its simplicity, the method outperforms the self-supervised state-of-the-art on a variety of label propagation tasks involving objects, semantic parts, and pose. Moreover, we show that self-supervised adaptation at test-time and edge dropout improve transfer for object-level correspondence.
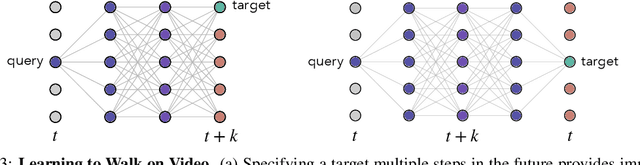
Towards Practical Multi-Object Manipulation using Relational Reinforcement Learning
Dec 23, 2019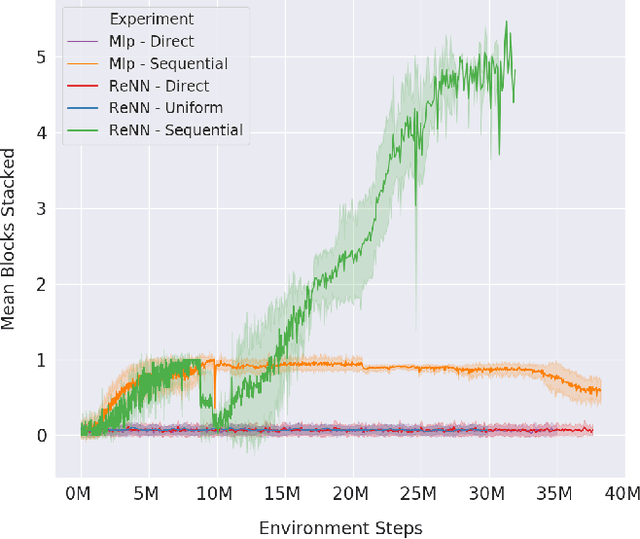

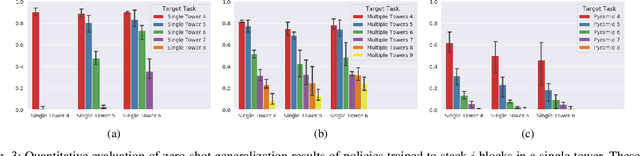
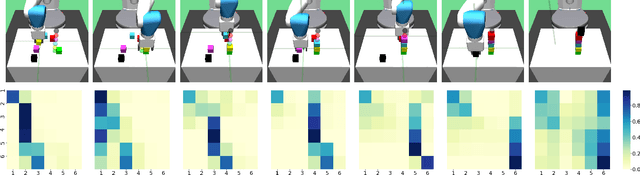
Learning robotic manipulation tasks using reinforcement learning with sparse rewards is currently impractical due to the outrageous data requirements. Many practical tasks require manipulation of multiple objects, and the complexity of such tasks increases with the number of objects. Learning from a curriculum of increasingly complex tasks appears to be a natural solution, but unfortunately, does not work for many scenarios. We hypothesize that the inability of the state-of-the-art algorithms to effectively utilize a task curriculum stems from the absence of inductive biases for transferring knowledge from simpler to complex tasks. We show that graph-based relational architectures overcome this limitation and enable learning of complex tasks when provided with a simple curriculum of tasks with increasing numbers of objects. We demonstrate the utility of our framework on a simulated block stacking task. Starting from scratch, our agent learns to stack six blocks into a tower. Despite using step-wise sparse rewards, our method is orders of magnitude more data-efficient and outperforms the existing state-of-the-art method that utilizes human demonstrations. Furthermore, the learned policy exhibits zero-shot generalization, successfully stacking blocks into taller towers and previously unseen configurations such as pyramids, without any further training.