 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn Words from Narrated Video
Paper and Code

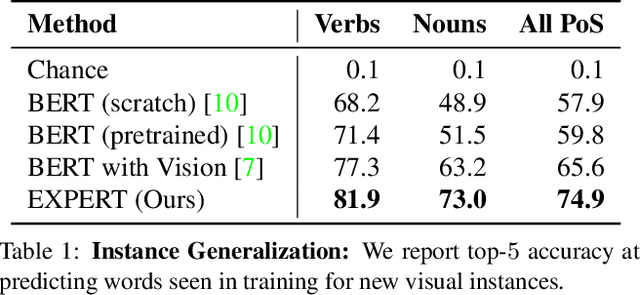

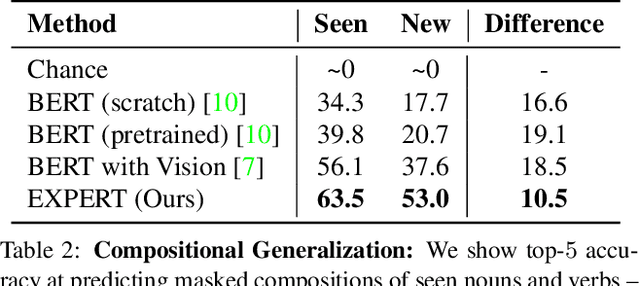
When we travel, we often encounter new scenarios we have never experienced before, with new sights and new words that describe them. We can use our language-learning ability to quickly learn these new words and correlate them with the visual world. In contrast, language models often do not robustly generalize to novel words and compositions. We propose a framework that learns how to learn text representations from visual context. Experiments show that our approach significantly outperforms the state-of-the-art in visual language modeling for acquiring new words and predicting new compositions. Model ablations and visualizations suggest that the visual modality helps our approach more robustly generalize at these tasks. Project webpage is available at https://expert.cs.columbia.edu/