 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards In-context Scene Understanding
Jun 02, 2023In-context learning$\unicode{x2013}$the ability to configure a model's behavior with different prompts$\unicode{x2013}$has revolutionized the field of natural language processing, alleviating the need for task-specific models and paving the way for generalist models capable of assisting with any query. Computer vision, in contrast, has largely stayed in the former regime: specialized decoders and finetuning protocols are generally required to perform dense tasks such as semantic segmentation and depth estimation. In this work we explore a simple mechanism for in-context learning of such scene understanding tasks: nearest neighbor retrieval from a prompt of annotated features. We propose a new pretraining protocol$\unicode{x2013}$leveraging attention within and across images$\unicode{x2013}$which yields representations particularly useful in this regime. The resulting Hummingbird model, suitably prompted, performs various scene understanding tasks without modification while approaching the performance of specialists that have been finetuned for each task. Moreover, Hummingbird can be configured to perform new tasks much more efficiently than finetuned models, raising the possibility of scene understanding in the interactive assistant regime.
Three ways to improve feature alignment for open vocabulary detection
Mar 23, 2023
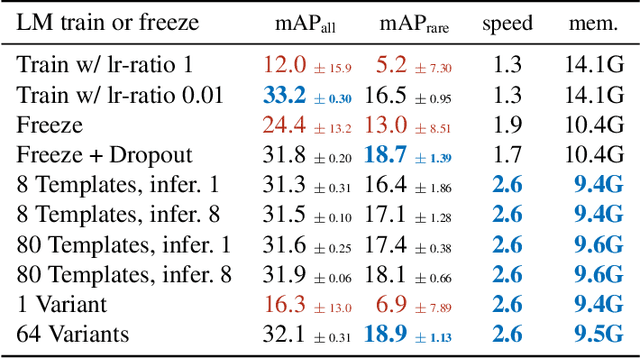
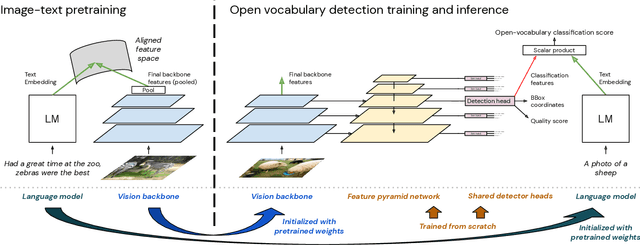
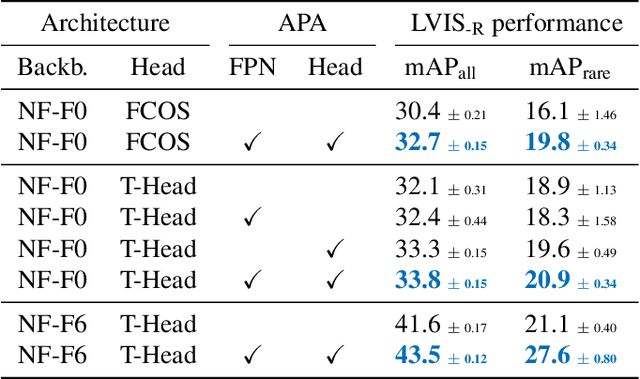
The core problem in zero-shot open vocabulary detection is how to align visual and text features, so that the detector performs well on unseen classes. Previous approaches train the feature pyramid and detection head from scratch, which breaks the vision-text feature alignment established during pretraining, and struggles to prevent the language model from forgetting unseen classes. We propose three methods to alleviate these issues. Firstly, a simple scheme is used to augment the text embeddings which prevents overfitting to a small number of classes seen during training, while simultaneously saving memory and computation. Secondly, the feature pyramid network and the detection head are modified to include trainable gated shortcuts, which encourages vision-text feature alignment and guarantees it at the start of detection training. Finally, a self-training approach is used to leverage a larger corpus of image-text pairs thus improving detection performance on classes with no human annotated bounding boxes. Our three methods are evaluated on the zero-shot version of the LVIS benchmark, each of them showing clear and significant benefits. Our final network achieves the new stateof-the-art on the mAP-all metric and demonstrates competitive performance for mAP-rare, as well as superior transfer to COCO and Objects365.
Object discovery and representation networks
Mar 16, 2022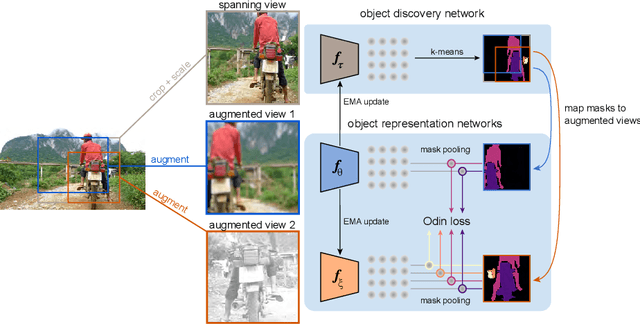
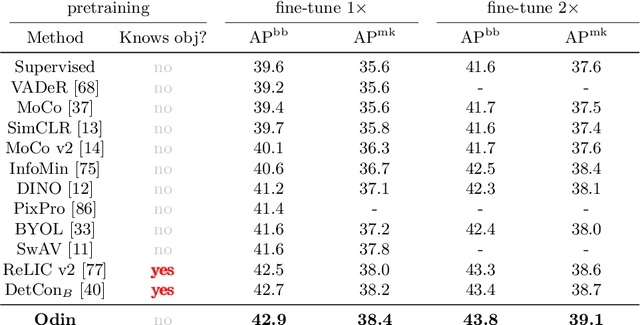


The promise of self-supervised learning (SSL) is to leverage large amounts of unlabeled data to solve complex tasks. While there has been excellent progress with simple, image-level learning, recent methods have shown the advantage of including knowledge of image structure. However, by introducing hand-crafted image segmentations to define regions of interest, or specialized augmentation strategies, these methods sacrifice the simplicity and generality that makes SSL so powerful. Instead, we propose a self-supervised learning paradigm that discovers the structure encoded in these priors by itself. Our method, Odin, couples object discovery and representation networks to discover meaningful image segmentations without any supervision. The resulting learning paradigm is simpler, less brittle, and more general, and achieves state-of-the-art transfer learning results for object detection and instance segmentation on COCO, and semantic segmentation on PASCAL and Cityscapes, while strongly surpassing supervised pre-training for video segmentation on DAVIS.
Input-level Inductive Biases for 3D Reconstruction
Dec 06, 2021



Much of the recent progress in 3D vision has been driven by the development of specialized architectures that incorporate geometrical inductive biases. In this paper we tackle 3D reconstruction using a domain agnostic architecture and study how instead to inject the same type of inductive biases directly as extra inputs to the model. This approach makes it possible to apply existing general models, such as Perceivers, on this rich domain, without the need for architectural changes, while simultaneously maintaining data efficiency of bespoke models. In particular we study how to encode cameras, projective ray incidence and epipolar geometry as model inputs, and demonstrate competitive multi-view depth estimation performance on multiple benchmarks.
NeRF in detail: Learning to sample for view synthesis
Jun 09, 2021



Neural radiance fields (NeRF) methods have demonstrated impressive novel view synthesis performance. The core approach is to render individual rays by querying a neural network at points sampled along the ray to obtain the density and colour of the sampled points, and integrating this information using the rendering equation. Since dense sampling is computationally prohibitive, a common solution is to perform coarse-to-fine sampling. In this work we address a clear limitation of the vanilla coarse-to-fine approach -- that it is based on a heuristic and not trained end-to-end for the task at hand. We introduce a differentiable module that learns to propose samples and their importance for the fine network, and consider and compare multiple alternatives for its neural architecture. Training the proposal module from scratch can be unstable due to lack of supervision, so an effective pre-training strategy is also put forward. The approach, named `NeRF in detail' (NeRF-ID), achieves superior view synthesis quality over NeRF and the state-of-the-art on the synthetic Blender benchmark and on par or better performance on the real LLFF-NeRF scenes. Furthermore, by leveraging the predicted sample importance, a 25% saving in computation can be achieved without significantly sacrificing the rendering quality.
Self-Supervised MultiModal Versatile Networks
Jun 29, 2020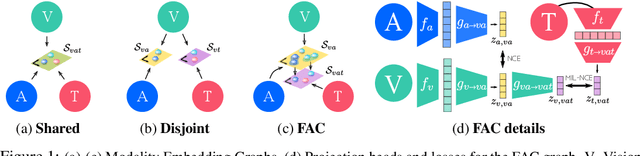
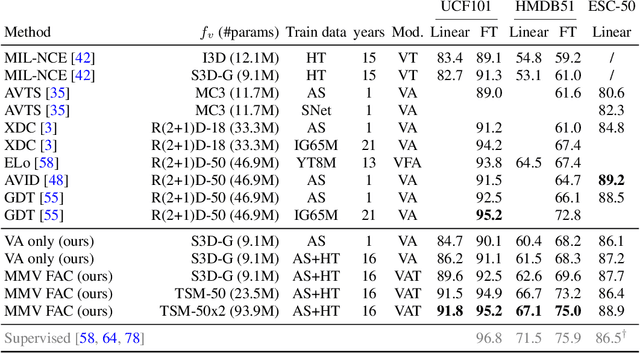
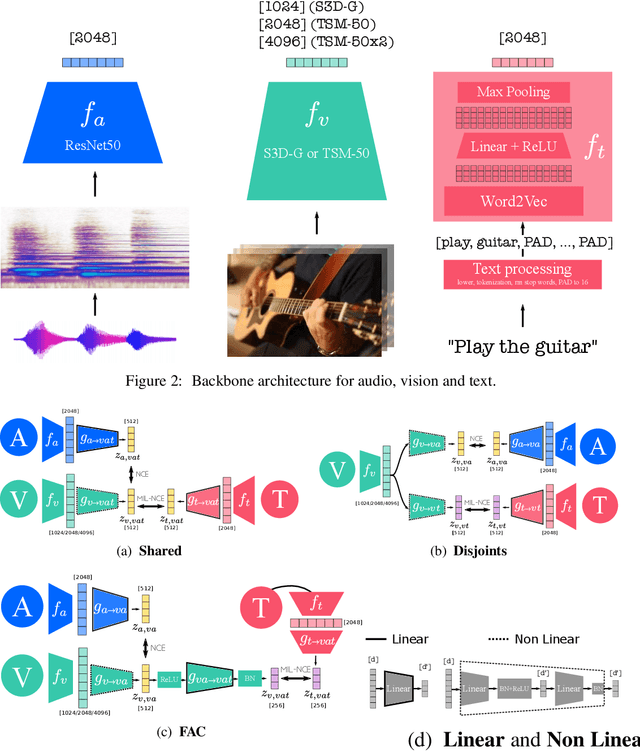
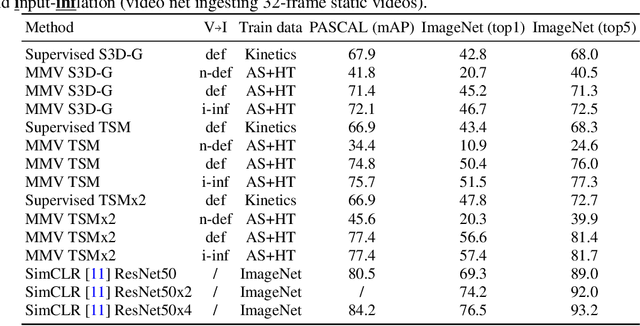
Videos are a rich source of multi-modal supervision. In this work, we learn representations using self-supervision by leveraging three modalities naturally present in videos: vision, audio and language. To this end, we introduce the notion of a multimodal versatile network -- a network that can ingest multiple modalities and whose representations enable downstream tasks in multiple modalities. In particular, we explore how best to combine the modalities, such that fine-grained representations of audio and vision can be maintained, whilst also integrating text into a common embedding. Driven by versatility, we also introduce a novel process of deflation, so that the networks can be effortlessly applied to the visual data in the form of video or a static image. We demonstrate how such networks trained on large collections of unlabelled video data can be applied on video, video-text, image and audio tasks. Equipped with these representations, we obtain state-of-the-art performance on multiple challenging benchmarks including UCF101, HMDB51 and ESC-50 when compared to previous self-supervised work.
Efficient Neighbourhood Consensus Networks via Submanifold Sparse Convolutions
Apr 22, 2020

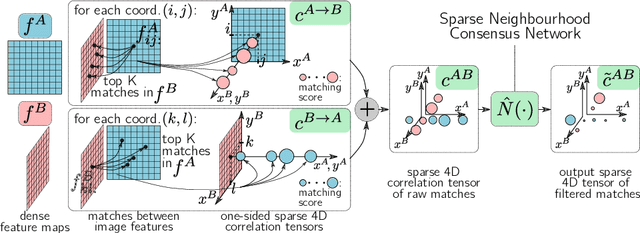
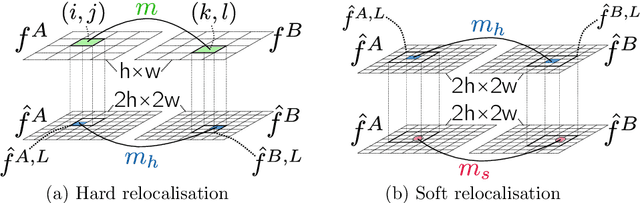
In this work we target the problem of estimating accurately localised correspondences between a pair of images. We adopt the recent Neighbourhood Consensus Networks that have demonstrated promising performance for difficult correspondence problems and propose modifications to overcome their main limitations: large memory consumption, large inference time and poorly localised correspondences. Our proposed modifications can reduce the memory footprint and execution time more than $10\times$, with equivalent results. This is achieved by sparsifying the correlation tensor containing tentative matches, and its subsequent processing with a 4D CNN using submanifold sparse convolutions. Localisation accuracy is significantly improved by processing the input images in higher resolution, which is possible due to the reduced memory footprint, and by a novel two-stage correspondence relocalisation module. The proposed Sparse-NCNet method obtains state-of-the-art results on the HPatches Sequences and InLoc visual localisation benchmarks, and competitive results in the Aachen Day-Night benchmark.
Compact Deep Aggregation for Set Retrieval
Mar 26, 2020



The objective of this work is to learn a compact embedding of a set of descriptors that is suitable for efficient retrieval and ranking, whilst maintaining discriminability of the individual descriptors. We focus on a specific example of this general problem -- that of retrieving images containing multiple faces from a large scale dataset of images. Here the set consists of the face descriptors in each image, and given a query for multiple identities, the goal is then to retrieve, in order, images which contain all the identities, all but one, \etc To this end, we make the following contributions: first, we propose a CNN architecture -- {\em SetNet} -- to achieve the objective: it learns face descriptors and their aggregation over a set to produce a compact fixed length descriptor designed for set retrieval, and the score of an image is a count of the number of identities that match the query; second, we show that this compact descriptor has minimal loss of discriminability up to two faces per image, and degrades slowly after that -- far exceeding a number of baselines; third, we explore the speed vs.\ retrieval quality trade-off for set retrieval using this compact descriptor; and, finally, we collect and annotate a large dataset of images containing various number of celebrities, which we use for evaluation and is publicly released.
Controllable Attention for Structured Layered Video Decomposition
Oct 24, 2019



The objective of this paper is to be able to separate a video into its natural layers, and to control which of the separated layers to attend to. For example, to be able to separate reflections, transparency or object motion. We make the following three contributions: (i) we introduce a new structured neural network architecture that explicitly incorporates layers (as spatial masks) into its design. This improves separation performance over previous general purpose networks for this task; (ii) we demonstrate that we can augment the architecture to leverage external cues such as audio for controllability and to help disambiguation; and (iii) we experimentally demonstrate the effectiveness of our approach and training procedure with controlled experiments while also showing that the proposed model can be successfully applied to real-word applications such as reflection removal and action recognition in cluttered scenes.
Object Discovery with a Copy-Pasting GAN
May 27, 2019



We tackle the problem of object discovery, where objects are segmented for a given input image, and the system is trained without using any direct supervision whatsoever. A novel copy-pasting GAN framework is proposed, where the generator learns to discover an object in one image by compositing it into another image such that the discriminator cannot tell that the resulting image is fake. After carefully addressing subtle issues, such as preventing the generator from `cheating', this game results in the generator learning to select objects, as copy-pasting objects is most likely to fool the discriminator. The system is shown to work well on four very different datasets, including large object appearance variations in challenging cluttered backgrounds.