 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject discovery and representation networks
Paper and Code
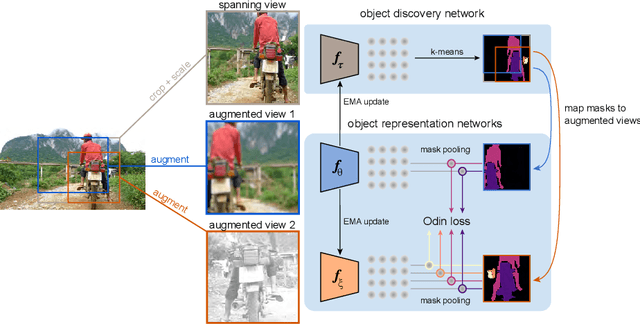
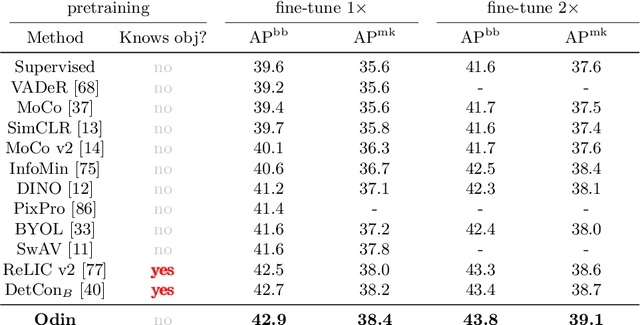


The promise of self-supervised learning (SSL) is to leverage large amounts of unlabeled data to solve complex tasks. While there has been excellent progress with simple, image-level learning, recent methods have shown the advantage of including knowledge of image structure. However, by introducing hand-crafted image segmentations to define regions of interest, or specialized augmentation strategies, these methods sacrifice the simplicity and generality that makes SSL so powerful. Instead, we propose a self-supervised learning paradigm that discovers the structure encoded in these priors by itself. Our method, Odin, couples object discovery and representation networks to discover meaningful image segmentations without any supervision. The resulting learning paradigm is simpler, less brittle, and more general, and achieves state-of-the-art transfer learning results for object detection and instance segmentation on COCO, and semantic segmentation on PASCAL and Cityscapes, while strongly surpassing supervised pre-training for video segmentation on DAVIS.