 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Mathematics Research with AI-Driven Formal Proof Search
May 21, 2026Large language models (LLMs) increasingly excel at mathematical reasoning, but their unreliability limits their utility in mathematics research. A mitigation is using LLMs to generate formal proofs in languages like Lean. We perform the first large-scale evaluation of this method's ability to solve open problems. Our most capable agent autonomously resolved 9 of 353 open Erdős problems at the per-problem cost of a few hundred dollars, proved 44/492 OEIS conjectures, and is being deployed in combinatorics, optimization, graph theory, algebraic geometry, and quantum optics research. A basic agent alternating LLM-based generation with Lean-based verification replicated the Erdős successes but proved costlier on the hardest problems. These findings demonstrate the power of AI-aided formal proof search and shed light on the agent designs that enable it.
An Improved Last-Iterate Convergence Rate for Anchored Gradient Descent Ascent
Apr 04, 2026We analyze the last-iterate convergence of the Anchored Gradient Descent Ascent algorithm for smooth convex-concave min-max problems. While previous work established a last-iterate rate of $\mathcal{O}(1/t^{2-2p})$ for the squared gradient norm, where $p \in (1/2, 1)$, it remained an open problem whether the improved exact $\mathcal{O}(1/t)$ rate is achievable. In this work, we resolve this question in the affirmative. This result was discovered autonomously by an AI system capable of writing formal proofs in Lean. The Lean proof can be accessed at https://github.com/google-deepmind/formal-conjectures/pull/3675/commits/a13226b49fd3b897f4c409194f3bcbeb96a08515
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Jun 16, 2025In this white paper, we present AlphaEvolve, an evolutionary coding agent that substantially enhances capabilities of state-of-the-art LLMs on highly challenging tasks such as tackling open scientific problems or optimizing critical pieces of computational infrastructure. AlphaEvolve orchestrates an autonomous pipeline of LLMs, whose task is to improve an algorithm by making direct changes to the code. Using an evolutionary approach, continuously receiving feedback from one or more evaluators, AlphaEvolve iteratively improves the algorithm, potentially leading to new scientific and practical discoveries. We demonstrate the broad applicability of this approach by applying it to a number of important computational problems. When applied to optimizing critical components of large-scale computational stacks at Google, AlphaEvolve developed a more efficient scheduling algorithm for data centers, found a functionally equivalent simplification in the circuit design of hardware accelerators, and accelerated the training of the LLM underpinning AlphaEvolve itself. Furthermore, AlphaEvolve discovered novel, provably correct algorithms that surpass state-of-the-art solutions on a spectrum of problems in mathematics and computer science, significantly expanding the scope of prior automated discovery methods (Romera-Paredes et al., 2023). Notably, AlphaEvolve developed a search algorithm that found a procedure to multiply two $4 \times 4$ complex-valued matrices using $48$ scalar multiplications; offering the first improvement, after 56 years, over Strassen's algorithm in this setting. We believe AlphaEvolve and coding agents like it can have a significant impact in improving solutions of problems across many areas of science and computation.
FunBO: Discovering Acquisition Functions for Bayesian Optimization with FunSearch
Jun 07, 2024



The sample efficiency of Bayesian optimization algorithms depends on carefully crafted acquisition functions (AFs) guiding the sequential collection of function evaluations. The best-performing AF can vary significantly across optimization problems, often requiring ad-hoc and problem-specific choices. This work tackles the challenge of designing novel AFs that perform well across a variety of experimental settings. Based on FunSearch, a recent work using Large Language Models (LLMs) for discovery in mathematical sciences, we propose FunBO, an LLM-based method that can be used to learn new AFs written in computer code by leveraging access to a limited number of evaluations for a set of objective functions. We provide the analytic expression of all discovered AFs and evaluate them on various global optimization benchmarks and hyperparameter optimization tasks. We show how FunBO identifies AFs that generalize well in and out of the training distribution of functions, thus outperforming established general-purpose AFs and achieving competitive performance against AFs that are customized to specific function types and are learned via transfer-learning algorithms.
Quantum Circuit Optimization with AlphaTensor
Mar 05, 2024



A key challenge in realizing fault-tolerant quantum computers is circuit optimization. Focusing on the most expensive gates in fault-tolerant quantum computation (namely, the T gates), we address the problem of T-count optimization, i.e., minimizing the number of T gates that are needed to implement a given circuit. To achieve this, we develop AlphaTensor-Quantum, a method based on deep reinforcement learning that exploits the relationship between optimizing T-count and tensor decomposition. Unlike existing methods for T-count optimization, AlphaTensor-Quantum can incorporate domain-specific knowledge about quantum computation and leverage gadgets, which significantly reduces the T-count of the optimized circuits. AlphaTensor-Quantum outperforms the existing methods for T-count optimization on a set of arithmetic benchmarks (even when compared without making use of gadgets). Remarkably, it discovers an efficient algorithm akin to Karatsuba's method for multiplication in finite fields. AlphaTensor-Quantum also finds the best human-designed solutions for relevant arithmetic computations used in Shor's algorithm and for quantum chemistry simulation, thus demonstrating it can save hundreds of hours of research by optimizing relevant quantum circuits in a fully automated way.
Order Matters: Probabilistic Modeling of Node Sequence for Graph Generation
Jun 14, 2021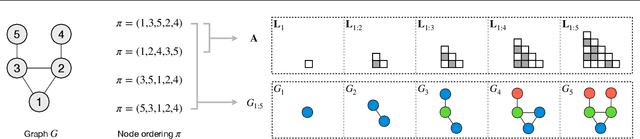

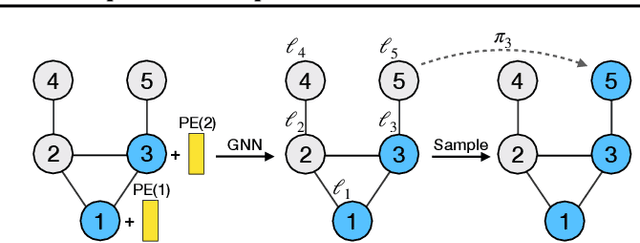
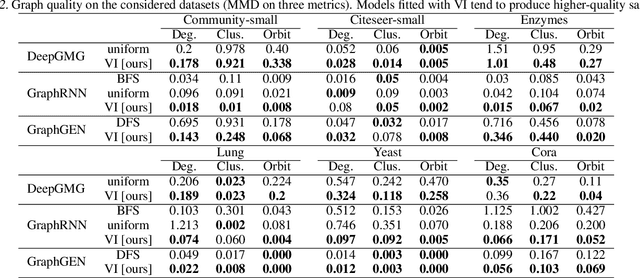
A graph generative model defines a distribution over graphs. One type of generative model is constructed by autoregressive neural networks, which sequentially add nodes and edges to generate a graph. However, the likelihood of a graph under the autoregressive model is intractable, as there are numerous sequences leading to the given graph; this makes maximum likelihood estimation challenging. Instead, in this work we derive the exact joint probability over the graph and the node ordering of the sequential process. From the joint, we approximately marginalize out the node orderings and compute a lower bound on the log-likelihood using variational inference. We train graph generative models by maximizing this bound, without using the ad-hoc node orderings of previous methods. Our experiments show that the log-likelihood bound is significantly tighter than the bound of previous schemes. Moreover, the models fitted with the proposed algorithm can generate high-quality graphs that match the structures of target graphs not seen during training. We have made our code publicly available at \hyperref[https://github.com/tufts-ml/graph-generation-vi]{https://github.com/tufts-ml/graph-generation-vi}.
VarGrad: A Low-Variance Gradient Estimator for Variational Inference
Oct 29, 2020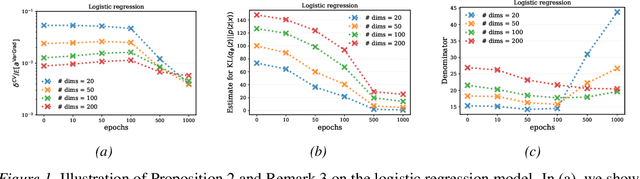
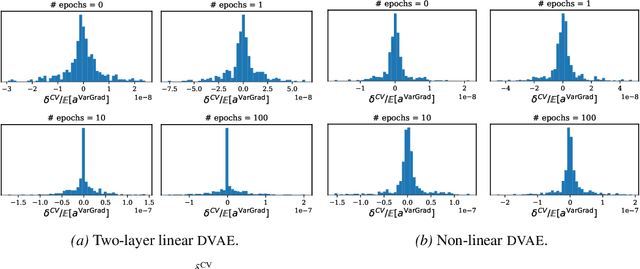
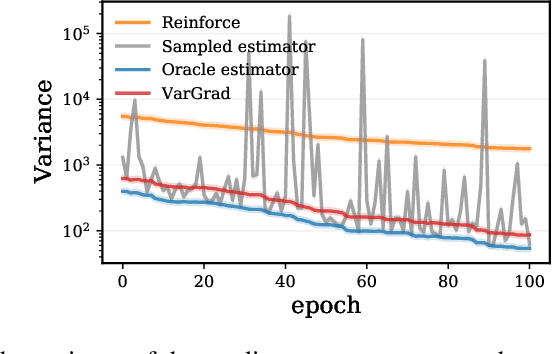
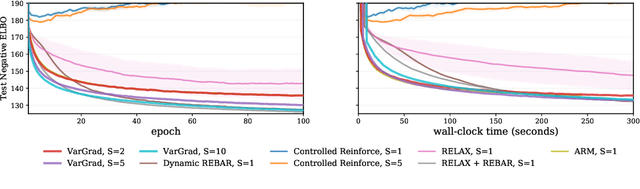
We analyse the properties of an unbiased gradient estimator of the ELBO for variational inference, based on the score function method with leave-one-out control variates. We show that this gradient estimator can be obtained using a new loss, defined as the variance of the log-ratio between the exact posterior and the variational approximation, which we call the $\textit{log-variance loss}$. Under certain conditions, the gradient of the log-variance loss equals the gradient of the (negative) ELBO. We show theoretically that this gradient estimator, which we call $\textit{VarGrad}$ due to its connection to the log-variance loss, exhibits lower variance than the score function method in certain settings, and that the leave-one-out control variate coefficients are close to the optimal ones. We empirically demonstrate that VarGrad offers a favourable variance versus computation trade-off compared to other state-of-the-art estimators on a discrete VAE.
Unbiased Gradient Estimation for Variational Auto-Encoders using Coupled Markov Chains
Oct 05, 2020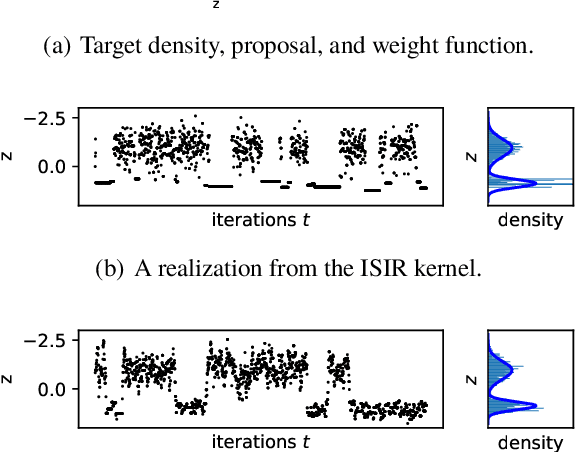
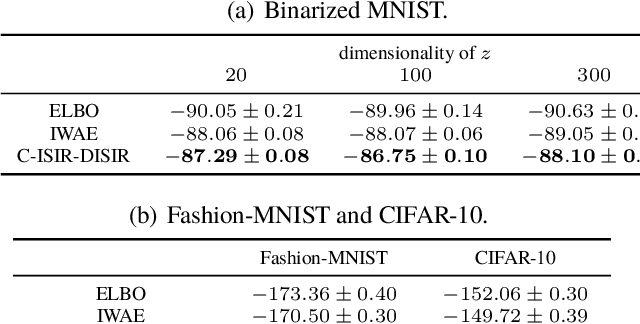
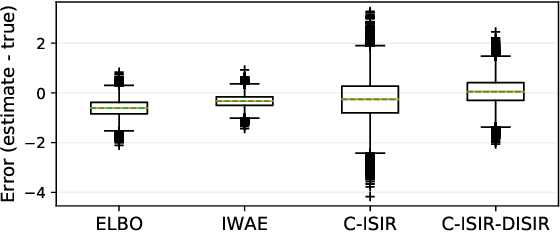
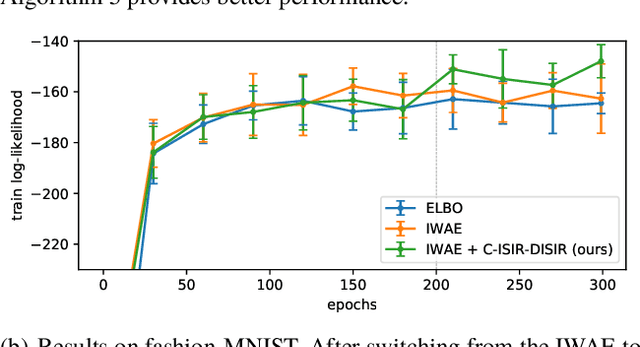
The variational auto-encoder (VAE) is a deep latent variable model that has two neural networks in an autoencoder-like architecture; one of them parameterizes the model's likelihood. Fitting its parameters via maximum likelihood is challenging since the computation of the likelihood involves an intractable integral over the latent space; thus the VAE is trained instead by maximizing a variational lower bound. Here, we develop a maximum likelihood training scheme for VAEs by introducing unbiased gradient estimators of the log-likelihood. We obtain the unbiased estimators by augmenting the latent space with a set of importance samples, similarly to the importance weighted auto-encoder (IWAE), and then constructing a Markov chain Monte Carlo (MCMC) coupling procedure on this augmented space. We provide the conditions under which the estimators can be computed in finite time and have finite variance. We demonstrate experimentally that VAEs fitted with unbiased estimators exhibit better predictive performance on three image datasets.
Prescribed Generative Adversarial Networks
Oct 09, 2019
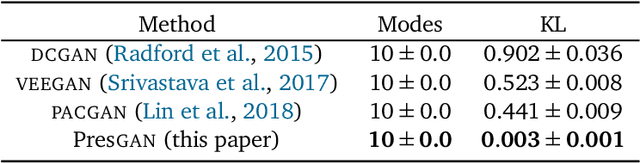
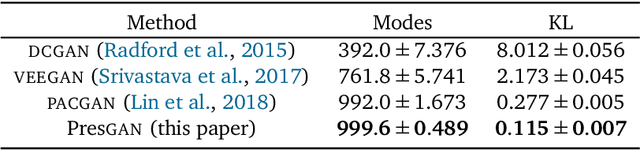
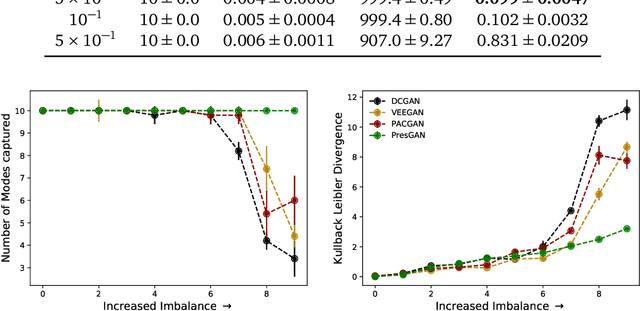
Generative adversarial networks (GANs) are a powerful approach to unsupervised learning. They have achieved state-of-the-art performance in the image domain. However, GANs are limited in two ways. They often learn distributions with low support---a phenomenon known as mode collapse---and they do not guarantee the existence of a probability density, which makes evaluating generalization using predictive log-likelihood impossible. In this paper, we develop the prescribed GAN (PresGAN) to address these shortcomings. PresGANs add noise to the output of a density network and optimize an entropy-regularized adversarial loss. The added noise renders tractable approximations of the predictive log-likelihood and stabilizes the training procedure. The entropy regularizer encourages PresGANs to capture all the modes of the data distribution. Fitting PresGANs involves computing the intractable gradients of the entropy regularization term; PresGANs sidestep this intractability using unbiased stochastic estimates. We evaluate PresGANs on several datasets and found they mitigate mode collapse and generate samples with high perceptual quality. We further found that PresGANs reduce the gap in performance in terms of predictive log-likelihood between traditional GANs and variational autoencoders (VAEs).
The Dynamic Embedded Topic Model
Jul 12, 2019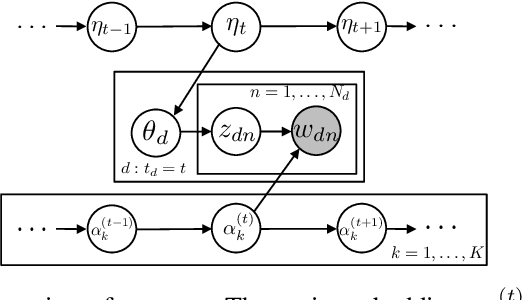

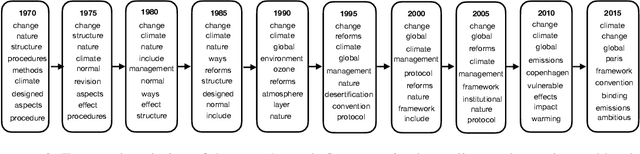
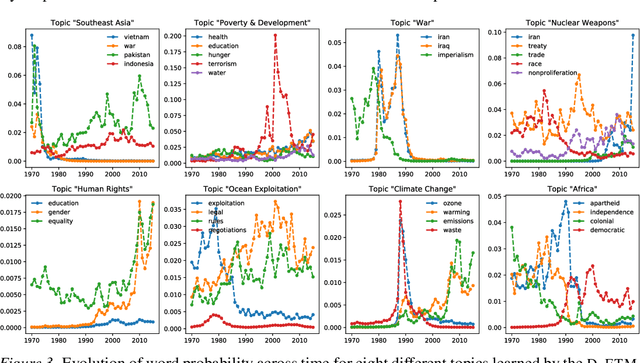
Topic modeling analyzes documents to learn meaningful patterns of words. Dynamic topic models capture how these patterns vary over time for a set of documents that were collected over a large time span. We develop the dynamic embedded topic model (D-ETM), a generative model of documents that combines dynamic latent Dirichlet allocation (D-LDA) and word embeddings. The D-ETM models each word with a categorical distribution whose parameter is given by the inner product between the word embedding and an embedding representation of its assigned topic at a particular time step. The word embeddings allow the D-ETM to generalize to rare words. The D-ETM learns smooth topic trajectories by defining a random walk prior over the embeddings of the topics. We fit the D-ETM using structured amortized variational inference. On a collection of United Nations debates, we find that the D-ETM learns interpretable topics and outperforms D-LDA in terms of both topic quality and predictive performance.