 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Region Constrained Measure Transport in Path Space for Stochastic Optimal Control and Inference
Aug 17, 2025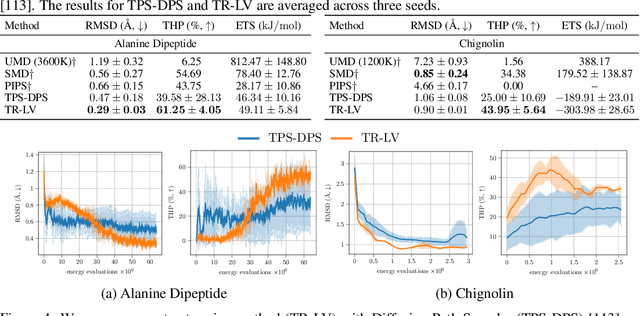
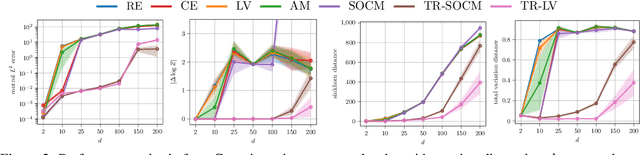
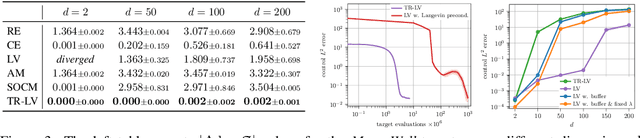
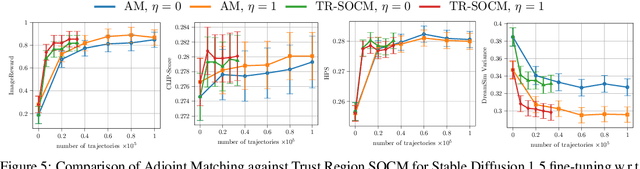
Solving stochastic optimal control problems with quadratic control costs can be viewed as approximating a target path space measure, e.g. via gradient-based optimization. In practice, however, this optimization is challenging in particular if the target measure differs substantially from the prior. In this work, we therefore approach the problem by iteratively solving constrained problems incorporating trust regions that aim for approaching the target measure gradually in a systematic way. It turns out that this trust region based strategy can be understood as a geometric annealing from the prior to the target measure, where, however, the incorporated trust regions lead to a principled and educated way of choosing the time steps in the annealing path. We demonstrate in multiple optimal control applications that our novel method can improve performance significantly, including tasks in diffusion-based sampling, transition path sampling, and fine-tuning of diffusion models.
Meta-learning For Few-Shot Time Series Crop Type Classification: A Benchmark On The EuroCropsML Dataset
Apr 15, 2025Spatial imbalances in crop type data pose significant challenges for accurate classification in remote sensing applications. Algorithms aiming at transferring knowledge from data-rich to data-scarce tasks have thus surged in popularity. However, despite their effectiveness in previous evaluations, their performance in challenging real-world applications is unclear and needs to be evaluated. This study benchmarks transfer learning and several meta-learning algorithms, including (First-Order) Model-Agnostic Meta-Learning ((FO)-MAML), Almost No Inner Loop (ANIL), and Task-Informed Meta-Learning (TIML), on the real-world EuroCropsML time series dataset, which combines farmer-reported crop data with Sentinel-2 satellite observations from Estonia, Latvia, and Portugal. Our findings indicate that MAML-based meta-learning algorithms achieve slightly higher accuracy compared to simpler transfer learning methods when applied to crop type classification tasks in Estonia after pre-training on data from Latvia. However, this improvement comes at the cost of increased computational demands and training time. Moreover, we find that the transfer of knowledge between geographically disparate regions, such as Estonia and Portugal, poses significant challenges to all investigated algorithms. These insights underscore the trade-offs between accuracy and computational resource requirements in selecting machine learning methods for real-world crop type classification tasks and highlight the difficulties of transferring knowledge between different regions of the Earth. To facilitate future research in this domain, we present the first comprehensive benchmark for evaluating transfer and meta-learning methods for crop type classification under real-world conditions. The corresponding code is publicly available at https://github.com/dida-do/eurocrops-meta-learning.
Underdamped Diffusion Bridges with Applications to Sampling
Mar 02, 2025We provide a general framework for learning diffusion bridges that transport prior to target distributions. It includes existing diffusion models for generative modeling, but also underdamped versions with degenerate diffusion matrices, where the noise only acts in certain dimensions. Extending previous findings, our framework allows to rigorously show that score matching in the underdamped case is indeed equivalent to maximizing a lower bound on the likelihood. Motivated by superior convergence properties and compatibility with sophisticated numerical integration schemes of underdamped stochastic processes, we propose \emph{underdamped diffusion bridges}, where a general density evolution is learned rather than prescribed by a fixed noising process. We apply our method to the challenging task of sampling from unnormalized densities without access to samples from the target distribution. Across a diverse range of sampling problems, our approach demonstrates state-of-the-art performance, notably outperforming alternative methods, while requiring significantly fewer discretization steps and no hyperparameter tuning.
From discrete-time policies to continuous-time diffusion samplers: Asymptotic equivalences and faster training
Jan 10, 2025We study the problem of training neural stochastic differential equations, or diffusion models, to sample from a Boltzmann distribution without access to target samples. Existing methods for training such models enforce time-reversal of the generative and noising processes, using either differentiable simulation or off-policy reinforcement learning (RL). We prove equivalences between families of objectives in the limit of infinitesimal discretization steps, linking entropic RL methods (GFlowNets) with continuous-time objects (partial differential equations and path space measures). We further show that an appropriate choice of coarse time discretization during training allows greatly improved sample efficiency and the use of time-local objectives, achieving competitive performance on standard sampling benchmarks with reduced computational cost.
Sequential Controlled Langevin Diffusions
Dec 10, 2024



An effective approach for sampling from unnormalized densities is based on the idea of gradually transporting samples from an easy prior to the complicated target distribution. Two popular methods are (1) Sequential Monte Carlo (SMC), where the transport is performed through successive annealed densities via prescribed Markov chains and resampling steps, and (2) recently developed diffusion-based sampling methods, where a learned dynamical transport is used. Despite the common goal, both approaches have different, often complementary, advantages and drawbacks. The resampling steps in SMC allow focusing on promising regions of the space, often leading to robust performance. While the algorithm enjoys asymptotic guarantees, the lack of flexible, learnable transitions can lead to slow convergence. On the other hand, diffusion-based samplers are learned and can potentially better adapt themselves to the target at hand, yet often suffer from training instabilities. In this work, we present a principled framework for combining SMC with diffusion-based samplers by viewing both methods in continuous time and considering measures on path space. This culminates in the new Sequential Controlled Langevin Diffusion (SCLD) sampling method, which is able to utilize the benefits of both methods and reaches improved performance on multiple benchmark problems, in many cases using only 10% of the training budget of previous diffusion-based samplers.
EuroCropsML: A Time Series Benchmark Dataset For Few-Shot Crop Type Classification
Jul 24, 2024



We introduce EuroCropsML, an analysis-ready remote sensing machine learning dataset for time series crop type classification of agricultural parcels in Europe. It is the first dataset designed to benchmark transnational few-shot crop type classification algorithms that supports advancements in algorithmic development and research comparability. It comprises 706 683 multi-class labeled data points across 176 classes, featuring annual time series of per-parcel median pixel values from Sentinel-2 L1C data for 2021, along with crop type labels and spatial coordinates. Based on the open-source EuroCrops collection, EuroCropsML is publicly available on Zenodo.
Dynamical Measure Transport and Neural PDE Solvers for Sampling
Jul 10, 2024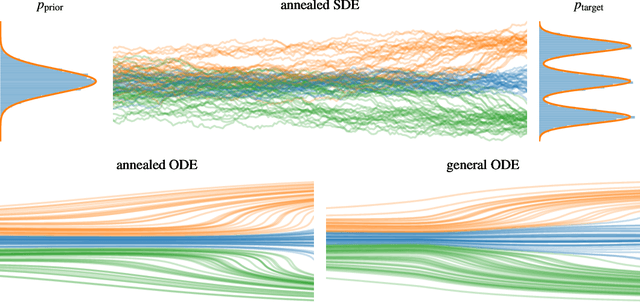



The task of sampling from a probability density can be approached as transporting a tractable density function to the target, known as dynamical measure transport. In this work, we tackle it through a principled unified framework using deterministic or stochastic evolutions described by partial differential equations (PDEs). This framework incorporates prior trajectory-based sampling methods, such as diffusion models or Schr\"odinger bridges, without relying on the concept of time-reversals. Moreover, it allows us to propose novel numerical methods for solving the transport task and thus sampling from complicated targets without the need for the normalization constant or data samples. We employ physics-informed neural networks (PINNs) to approximate the respective PDE solutions, implying both conceptional and computational advantages. In particular, PINNs allow for simulation- and discretization-free optimization and can be trained very efficiently, leading to significantly better mode coverage in the sampling task compared to alternative methods. Moreover, they can readily be fine-tuned with Gauss-Newton methods to achieve high accuracy in sampling.
Bridging discrete and continuous state spaces: Exploring the Ehrenfest process in time-continuous diffusion models
May 06, 2024



Generative modeling via stochastic processes has led to remarkable empirical results as well as to recent advances in their theoretical understanding. In principle, both space and time of the processes can be discrete or continuous. In this work, we study time-continuous Markov jump processes on discrete state spaces and investigate their correspondence to state-continuous diffusion processes given by SDEs. In particular, we revisit the $\textit{Ehrenfest process}$, which converges to an Ornstein-Uhlenbeck process in the infinite state space limit. Likewise, we can show that the time-reversal of the Ehrenfest process converges to the time-reversed Ornstein-Uhlenbeck process. This observation bridges discrete and continuous state spaces and allows to carry over methods from one to the respective other setting. Additionally, we suggest an algorithm for training the time-reversal of Markov jump processes which relies on conditional expectations and can thus be directly related to denoising score matching. We demonstrate our methods in multiple convincing numerical experiments.
Fast and Unified Path Gradient Estimators for Normalizing Flows
Mar 23, 2024Recent work shows that path gradient estimators for normalizing flows have lower variance compared to standard estimators for variational inference, resulting in improved training. However, they are often prohibitively more expensive from a computational point of view and cannot be applied to maximum likelihood training in a scalable manner, which severely hinders their widespread adoption. In this work, we overcome these crucial limitations. Specifically, we propose a fast path gradient estimator which improves computational efficiency significantly and works for all normalizing flow architectures of practical relevance. We then show that this estimator can also be applied to maximum likelihood training for which it has a regularizing effect as it can take the form of a given target energy function into account. We empirically establish its superior performance and reduced variance for several natural sciences applications.
From continuous-time formulations to discretization schemes: tensor trains and robust regression for BSDEs and parabolic PDEs
Jul 28, 2023The numerical approximation of partial differential equations (PDEs) poses formidable challenges in high dimensions since classical grid-based methods suffer from the so-called curse of dimensionality. Recent attempts rely on a combination of Monte Carlo methods and variational formulations, using neural networks for function approximation. Extending previous work (Richter et al., 2021), we argue that tensor trains provide an appealing framework for parabolic PDEs: The combination of reformulations in terms of backward stochastic differential equations and regression-type methods holds the promise of leveraging latent low-rank structures, enabling both compression and efficient computation. Emphasizing a continuous-time viewpoint, we develop iterative schemes, which differ in terms of computational efficiency and robustness. We demonstrate both theoretically and numerically that our methods can achieve a favorable trade-off between accuracy and computational efficiency. While previous methods have been either accurate or fast, we have identified a novel numerical strategy that can often combine both of these aspects.