 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeCat: An End-to-End Model for Multi-Speaker TTS & Many-to-Many Fine-Grained Prosody Transfer
Jun 20, 2023We present eCat, a novel end-to-end multispeaker model capable of: a) generating long-context speech with expressive and contextually appropriate prosody, and b) performing fine-grained prosody transfer between any pair of seen speakers. eCat is trained using a two-stage training approach. In Stage I, the model learns speaker-independent word-level prosody representations in an end-to-end fashion from speech. In Stage II, we learn to predict the prosody representations using the contextual information available in text. We compare eCat to CopyCat2, a model capable of both fine-grained prosody transfer (FPT) and multi-speaker TTS. We show that eCat statistically significantly reduces the gap in naturalness between CopyCat2 and human recordings by an average of 46.7% across 2 languages, 3 locales, and 7 speakers, along with better target-speaker similarity in FPT. We also compare eCat to VITS, and show a statistically significant preference.
Transfer learning with causal counterfactual reasoning in Decision Transformers
Oct 27, 2021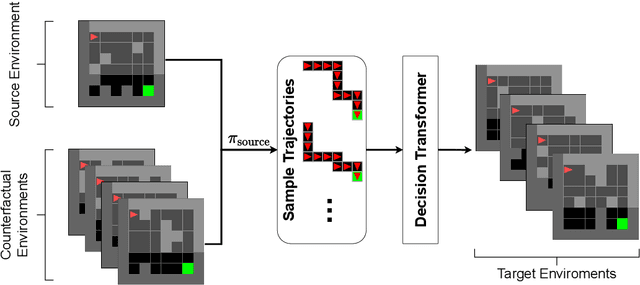



The ability to adapt to changes in environmental contingencies is an important challenge in reinforcement learning. Indeed, transferring previously acquired knowledge to environments with unseen structural properties can greatly enhance the flexibility and efficiency by which novel optimal policies may be constructed. In this work, we study the problem of transfer learning under changes in the environment dynamics. In this study, we apply causal reasoning in the offline reinforcement learning setting to transfer a learned policy to new environments. Specifically, we use the Decision Transformer (DT) architecture to distill a new policy on the new environment. The DT is trained on data collected by performing policy rollouts on factual and counterfactual simulations from the source environment. We show that this mechanism can bootstrap a successful policy on the target environment while retaining most of the reward.
VarGrad: A Low-Variance Gradient Estimator for Variational Inference
Oct 29, 2020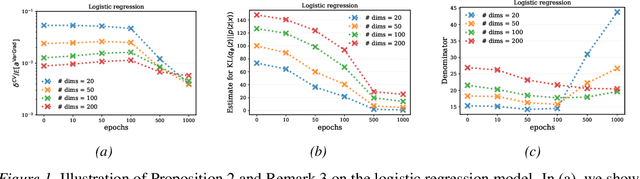
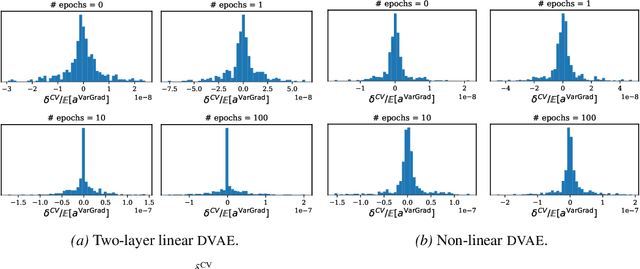
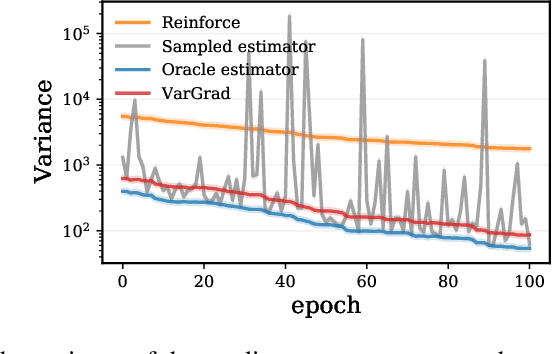
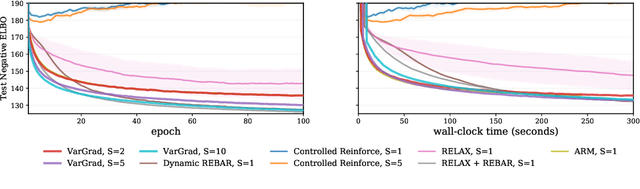
We analyse the properties of an unbiased gradient estimator of the ELBO for variational inference, based on the score function method with leave-one-out control variates. We show that this gradient estimator can be obtained using a new loss, defined as the variance of the log-ratio between the exact posterior and the variational approximation, which we call the $\textit{log-variance loss}$. Under certain conditions, the gradient of the log-variance loss equals the gradient of the (negative) ELBO. We show theoretically that this gradient estimator, which we call $\textit{VarGrad}$ due to its connection to the log-variance loss, exhibits lower variance than the score function method in certain settings, and that the leave-one-out control variate coefficients are close to the optimal ones. We empirically demonstrate that VarGrad offers a favourable variance versus computation trade-off compared to other state-of-the-art estimators on a discrete VAE.
Amortized variance reduction for doubly stochastic objectives
Mar 09, 2020

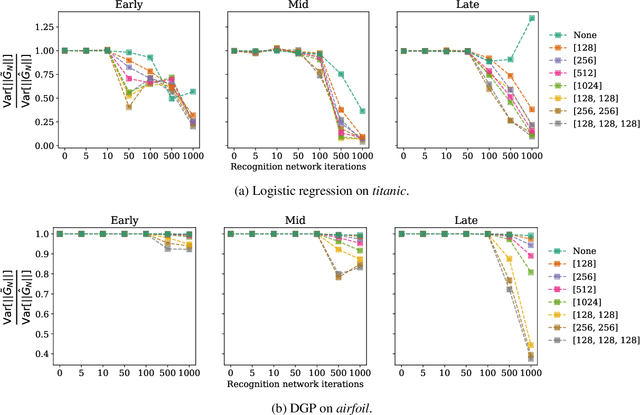
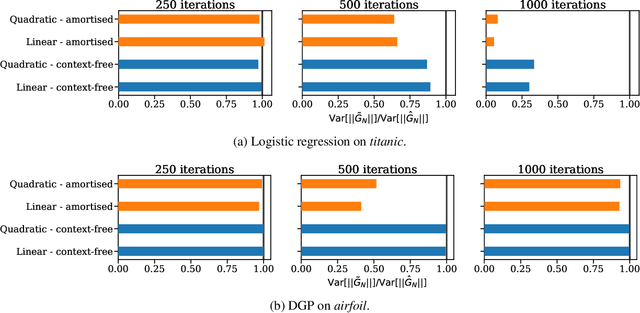
Approximate inference in complex probabilistic models such as deep Gaussian processes requires the optimisation of doubly stochastic objective functions. These objectives incorporate randomness both from mini-batch subsampling of the data and from Monte Carlo estimation of expectations. If the gradient variance is high, the stochastic optimisation problem becomes difficult with a slow rate of convergence. Control variates can be used to reduce the variance, but past approaches do not take into account how mini-batch stochasticity affects sampling stochasticity, resulting in sub-optimal variance reduction. We propose a new approach in which we use a recognition network to cheaply approximate the optimal control variate for each mini-batch, with no additional model gradient computations. We illustrate the properties of this proposal and test its performance on logistic regression and deep Gaussian processes.
Generalized Bayesian Filtering via Sequential Monte Carlo
Feb 23, 2020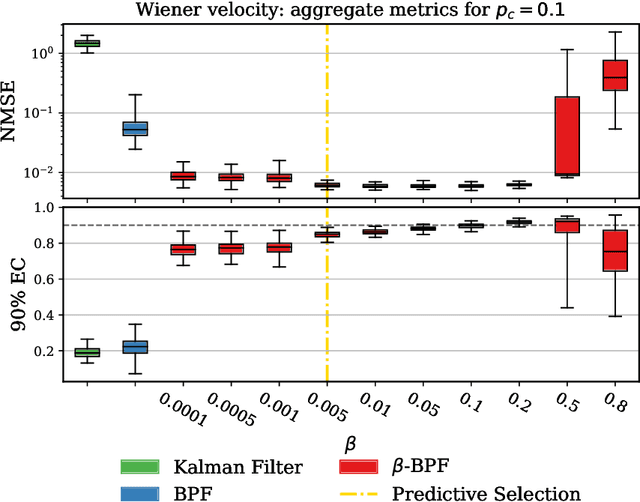
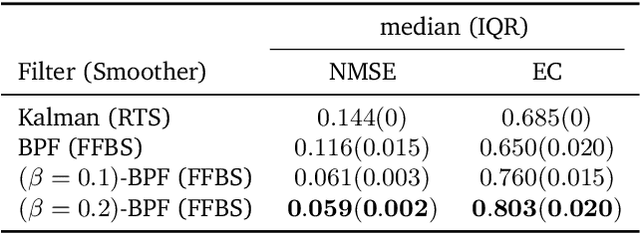
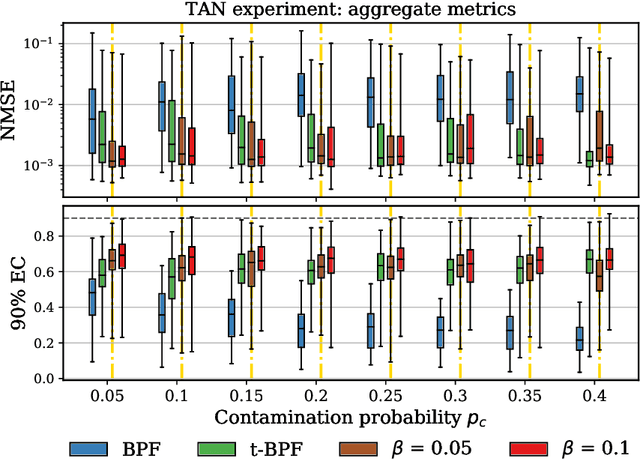
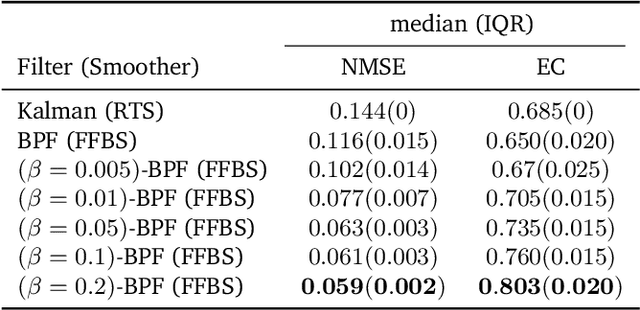
We introduce a framework for inference in general state-space hidden Markov models (HMMs) under likelihood misspecification. In particular, we leverage the loss-theoretic perspective of generalized Bayesian inference (GBI) to define generalized filtering recursions in HMMs, that can tackle the problem of inference under model misspecification. In doing so, we arrive at principled procedures for robust inference against observation contamination through the $\beta$-divergence. Operationalizing the proposed framework is made possible via sequential Monte Carlo methods (SMC). The standard particle methods, and their associated convergence results, are readily generalized to the new setting. We demonstrate our approach to object tracking and Gaussian process regression problems, and observe improved performance over standard filtering algorithms.
Multi-task Learning in Deep Gaussian Processes with Multi-kernel Layers
May 29, 2019


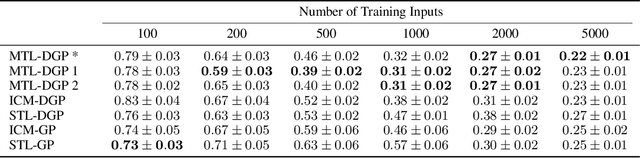
We present a multi-task learning formulation for Deep Gaussian processes (DGPs), describing a multi-kernel architecture for DGP layers. The proposed model is a non-linear mixture of latent Gaussian processes (GPs) with components shared between the tasks, in addition to separate task-specific components. Our formulation allows for learning complex relationships between tasks. We benchmark our model on three real-world datasets showing empirically that our formulation is able to improve the learning performance and transfer information between the tasks, outperforming state-of-the-art GP-based single-task learning and multi-task learning models.