Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning in Deep Gaussian Processes with Multi-kernel Layers
Paper and Code



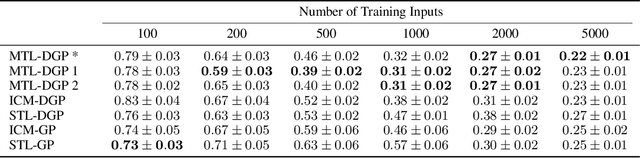
We present a multi-task learning formulation for Deep Gaussian processes (DGPs), describing a multi-kernel architecture for DGP layers. The proposed model is a non-linear mixture of latent Gaussian processes (GPs) with components shared between the tasks, in addition to separate task-specific components. Our formulation allows for learning complex relationships between tasks. We benchmark our model on three real-world datasets showing empirically that our formulation is able to improve the learning performance and transfer information between the tasks, outperforming state-of-the-art GP-based single-task learning and multi-task learning models.
View paper on