 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Model-Based Clustering with Sequential Monte Carlo
Apr 16, 2026In online clustering problems, there is often a large amount of uncertainty over possible cluster assignments that cannot be resolved until more data are observed. This difficulty is compounded when clusters follow complex distributions, as is the case with text data. Sequential Monte Carlo (SMC) methods give a natural way of representing and updating this uncertainty over time, but have prohibitive memory requirements for large-scale problems. We propose a novel SMC algorithm that decomposes clustering problems into approximately independent subproblems, allowing a more compact representation of the algorithm state. Our approach is motivated by the knowledge base construction problem, and we show that our method is able to accurately and efficiently solve clustering problems in this setting and others where traditional SMC struggles.
ARO: A New Lens On Matrix Optimization For Large Models
Feb 09, 2026Matrix-based optimizers have attracted growing interest for improving LLM training efficiency, with significant progress centered on orthogonalization/whitening based methods. While yielding substantial performance gains, a fundamental question arises: can we develop new paradigms beyond orthogonalization, pushing the efficiency frontier further? We present \textbf{Adaptively Rotated Optimization (ARO}, a new matrix optimization framework that treats gradient rotation as a first class design principle. ARO accelerates LLM training by performing normed steepest descent in a rotated coordinate system, where the rotation is determined by a novel norm-informed policy. This perspective yields update rules that go beyond existing orthogonalization and whitening optimizers, improving sample efficiency in practice. To make comparisons reliable, we propose a rigorously controlled benchmarking protocol that reduces confounding and bias. Under this protocol, ARO consistently outperforms AdamW (by 1.3 $\sim$1.35$\times$) and orthogonalization methods (by 1.1$\sim$1.15$\times$) in LLM pretraining at up to 8B activated parameters, and up to $8\times$ overtrain budget, without evidence of diminishing returns. Finally, we discuss how ARO can be reformulated as a symmetry-aware optimizer grounded in rotational symmetries of residual streams, motivating advanced designs that enable computationally efficient exploitation of cross-layer/cross module couplings.
OptRot: Mitigating Weight Outliers via Data-Free Rotations for Post-Training Quantization
Dec 30, 2025The presence of outliers in Large Language Models (LLMs) weights and activations makes them difficult to quantize. Recent work has leveraged rotations to mitigate these outliers. In this work, we propose methods that learn fusible rotations by minimizing principled and cheap proxy objectives to the weight quantization error. We primarily focus on GPTQ as the quantization method. Our main method is OptRot, which reduces weight outliers simply by minimizing the element-wise fourth power of the rotated weights. We show that OptRot outperforms both Hadamard rotations and more expensive, data-dependent methods like SpinQuant and OSTQuant for weight quantization. It also improves activation quantization in the W4A8 setting. We also propose a data-dependent method, OptRot$^{+}$, that further improves performance by incorporating information on the activation covariance. In the W4A4 setting, we see that both OptRot and OptRot$^{+}$ perform worse, highlighting a trade-off between weight and activation quantization.
TURBOATTENTION: Efficient Attention Approximation For High Throughputs LLMs
Dec 11, 2024



Large language model (LLM) inference demands significant amount of computation and memory, especially in the key attention mechanism. While techniques, such as quantization and acceleration algorithms, like FlashAttention, have improved efficiency of the overall inference, they address different aspects of the problem: quantization focuses on weight-activation operations, while FlashAttention improves execution but requires high-precision formats. Recent Key-value (KV) cache quantization reduces memory bandwidth but still needs floating-point dequantization for attention operation. We present TurboAttention, a comprehensive approach to enable quantized execution of attention that simultaneously addresses both memory and computational efficiency. Our solution introduces two key innovations: FlashQ, a headwise attention quantization technique that enables both compression of KV cache and quantized execution of activation-activation multiplication, and Sparsity-based Softmax Approximation (SAS), which eliminates the need for dequantization to FP32 during exponentiation operation in attention. Experimental results demonstrate that TurboAttention achieves 1.2-1.8x speedup in attention, reduces the KV cache size by over 4.4x, and enables up to 2.37x maximum throughput over the FP16 baseline while outperforming state-of-the-art quantization and compression techniques across various datasets and models.
Low-Rank Correction for Quantized LLMs
Dec 10, 2024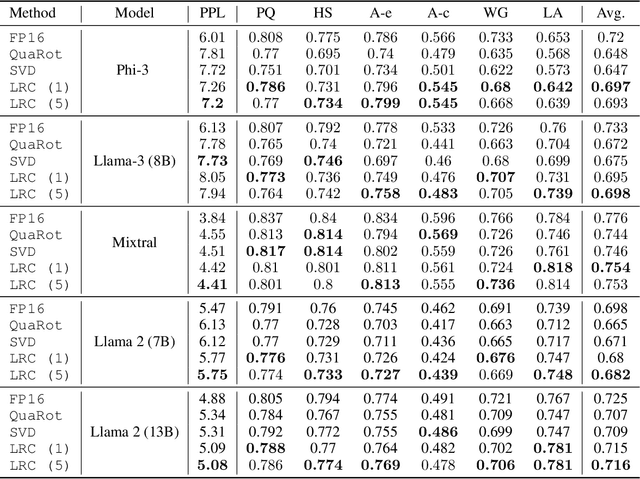
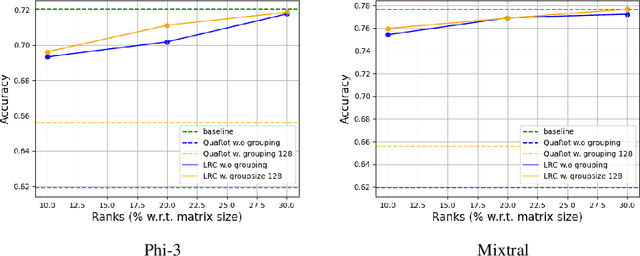
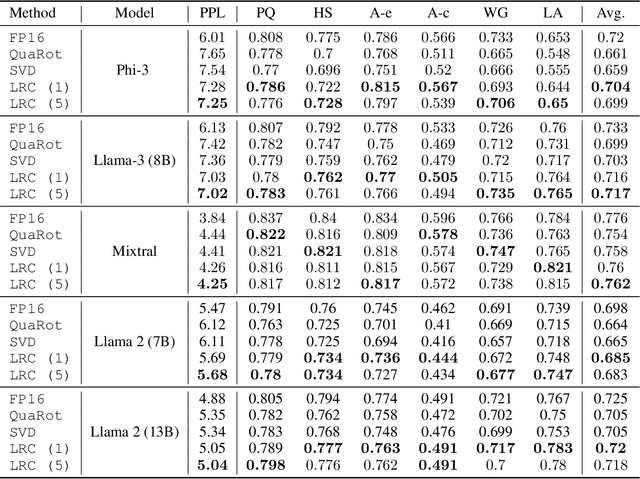
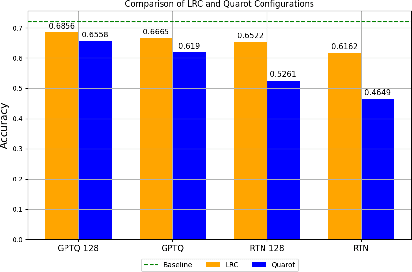
We consider the problem of model compression for Large Language Models (LLMs) at post-training time, where the task is to compress a well-trained model using only a small set of calibration input data. In this work, we introduce a new low-rank approach to correct for quantization errors of \emph{activations} in LLMs: we propose to add low-rank weight matrices in full precision that act on the \emph{unquantized} activations. We then solve a joint optimization problem over the quantized representation of the weights and additional low-rank weight matrices to quantize both weights and activations. We focus on the case of 4-bit weight-and-activation quantization (W4A4). Using ranks equivalent to 10\% of the original weight matrix size, our approach reduces the accuracy gap with the original model by more than 50\%. Using ranks equivalent to 30\% of the original weight matrix, the accuracy gap is closed completely. We demonstrate our results on four recent LLMs, namely Llama-2, Llama-3, Phi-3 and Mixtral models.
Pyramid Vector Quantization for LLMs
Oct 22, 2024


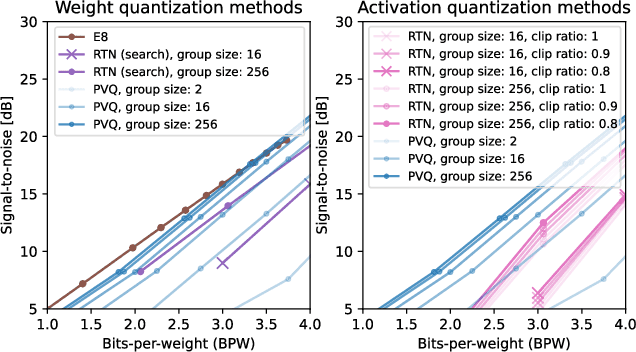
Recent works on compression of large language models (LLM) using quantization considered reparameterizing the architecture such that weights are distributed on the sphere. This demonstratively improves the ability to quantize by increasing the mathematical notion of coherence, resulting in fewer weight outliers without affecting the network output. In this work, we aim to further exploit this spherical geometry of the weights when performing quantization by considering Pyramid Vector Quantization (PVQ) for large language models. Arranging points evenly on the sphere is notoriously difficult, especially in high dimensions, and in case approximate solutions exists, representing points explicitly in a codebook is typically not feasible due to its additional memory cost. Instead, PVQ uses a fixed integer lattice on the sphere by projecting points onto the 1-sphere, which allows for efficient encoding and decoding without requiring an explicit codebook in memory. To obtain a practical algorithm, we propose to combine PVQ with scale quantization for which we derive theoretically optimal quantizations, under empirically verified assumptions. Further, we extend pyramid vector quantization to use Hessian information to minimize quantization error under expected feature activations, instead of only relying on weight magnitudes. Experimentally, we achieves state-of-the-art quantization performance with pareto-optimal trade-off between performance and bits per weight and bits per activation, compared to compared methods. On weight-only, we find that we can quantize a Llama-3 70B model to 3.25 bits per weight and retain 98\% accuracy on downstream tasks.
KBLaM: Knowledge Base augmented Language Model
Oct 14, 2024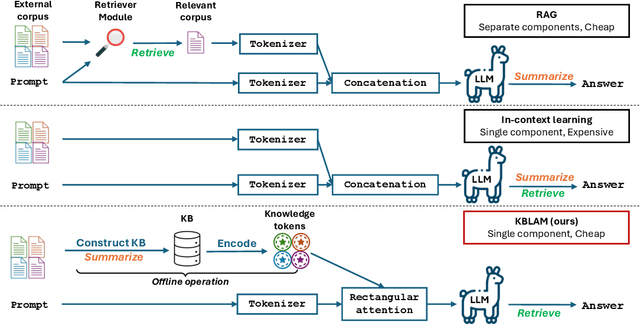
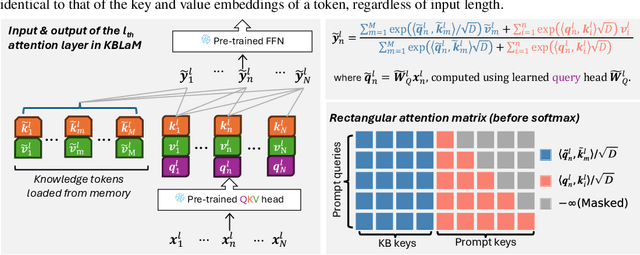
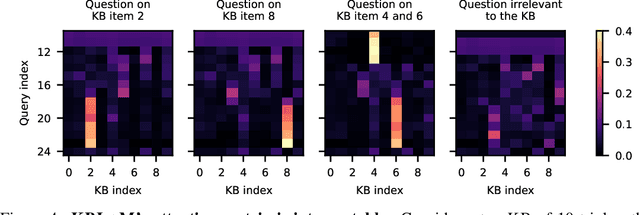
In this paper, we propose Knowledge Base augmented Language Model (KBLaM), a new method for augmenting Large Language Models (LLMs) with external knowledge. KBLaM works with a knowledge base (KB) constructed from a corpus of documents, transforming each piece of knowledge in the KB into continuous key-value vector pairs via pre-trained sentence encoders with linear adapters and integrating them into pre-trained LLMs via a specialized rectangular attention mechanism. Unlike Retrieval-Augmented Generation, KBLaM eliminates external retrieval modules, and unlike in-context learning, its computational overhead scales linearly with KB size rather than quadratically. Our approach enables integrating a large KB of more than 10K triples into an 8B pre-trained LLM of only 8K context window on one single A100 80GB GPU and allows for dynamic updates without model fine-tuning or retraining. Experiments demonstrate KBLaM's effectiveness in various tasks, including question-answering and open-ended reasoning, while providing interpretable insights into its use of the augmented knowledge.
QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs
Mar 30, 2024



We introduce QuaRot, a new Quantization scheme based on Rotations, which is able to quantize LLMs end-to-end, including all weights, activations, and KV cache in 4 bits. QuaRot rotates LLMs in a way that removes outliers from the hidden state without changing the output, making quantization easier. This computational invariance is applied to the hidden state (residual) of the LLM, as well as to the activations of the feed-forward components, aspects of the attention mechanism and to the KV cache. The result is a quantized model where all matrix multiplications are performed in 4-bits, without any channels identified for retention in higher precision. Our quantized LLaMa2-70B model has losses of at most 0.29 WikiText-2 perplexity and retains 99% of the zero-shot performance. Code is available at: https://github.com/spcl/QuaRot.
Structured Entity Extraction Using Large Language Models
Feb 06, 2024

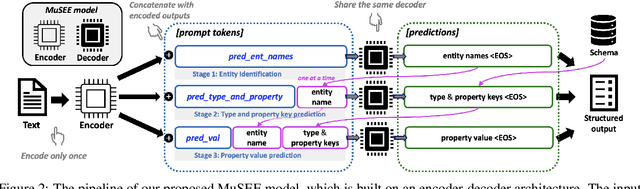

Recent advances in machine learning have significantly impacted the field of information extraction, with Large Language Models (LLMs) playing a pivotal role in extracting structured information from unstructured text. This paper explores the challenges and limitations of current methodologies in structured entity extraction and introduces a novel approach to address these issues. We contribute to the field by first introducing and formalizing the task of Structured Entity Extraction (SEE), followed by proposing Approximate Entity Set OverlaP (AESOP) Metric designed to appropriately assess model performance on this task. Later, we propose a new model that harnesses the power of LLMs for enhanced effectiveness and efficiency through decomposing the entire extraction task into multiple stages. Quantitative evaluation and human side-by-side evaluation confirm that our model outperforms baselines, offering promising directions for future advancements in structured entity extraction.
SliceGPT: Compress Large Language Models by Deleting Rows and Columns
Jan 26, 2024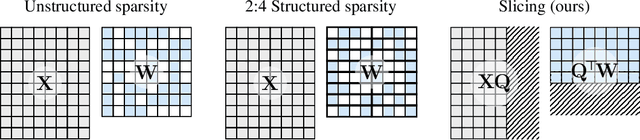
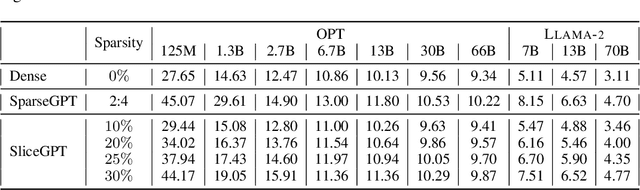

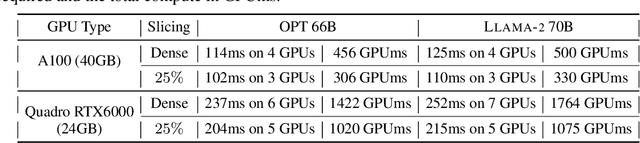
Large language models have become the cornerstone of natural language processing, but their use comes with substantial costs in terms of compute and memory resources. Sparsification provides a solution to alleviate these resource constraints, and recent works have shown that trained models can be sparsified post-hoc. Existing sparsification techniques face challenges as they need additional data structures and offer constrained speedup with current hardware. In this paper we present SliceGPT, a new post-training sparsification scheme which replaces each weight matrix with a smaller (dense) matrix, reducing the embedding dimension of the network. Through extensive experimentation, we show that SliceGPT can remove up to 25% of the model parameters (including embeddings) for LLAMA2-70B, OPT 66B and Phi-2 models while maintaining 99%, 99% and 90% zero-shot task performance of the dense model respectively. Our sliced models run on fewer GPUs and run faster without any additional code optimization: on 24GB consumer GPUs we reduce the total compute for inference on LLAMA2-70B to 64% of that of the dense model; on 40GB A100 GPUs we reduce it to 66%. We offer a new insight, computational invariance in transformer networks, which enables SliceGPT and we hope it will inspire and enable future avenues to reduce memory and computation demands for pre-trained models. Code is available at: https://github.com/microsoft/TransformerCompression