 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Correction for Quantized LLMs
Paper and Code
Dec 10, 2024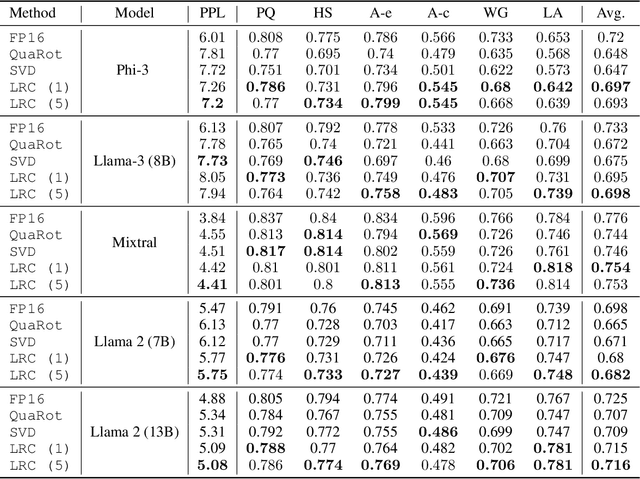
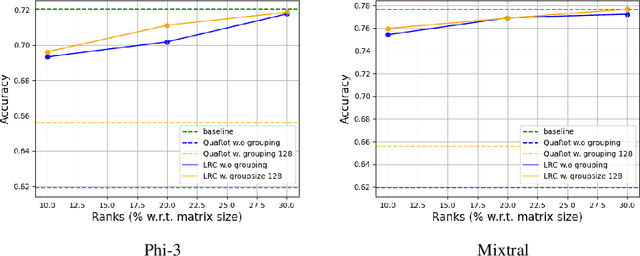
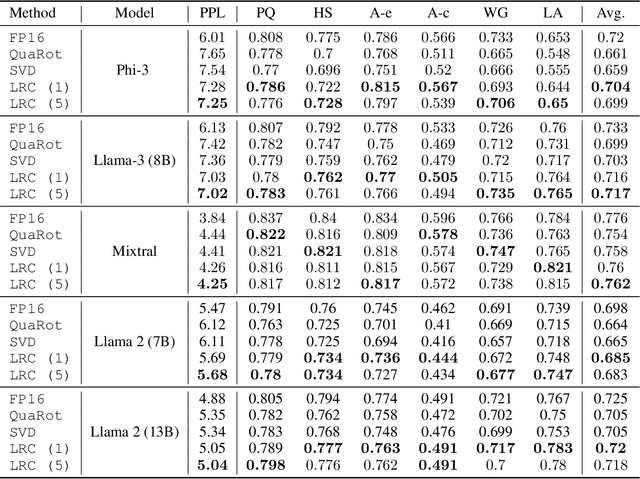
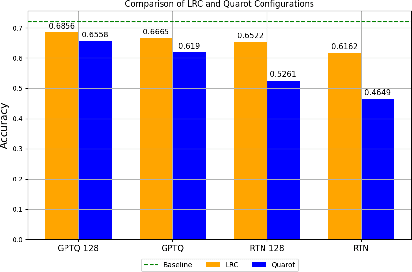
We consider the problem of model compression for Large Language Models (LLMs) at post-training time, where the task is to compress a well-trained model using only a small set of calibration input data. In this work, we introduce a new low-rank approach to correct for quantization errors of \emph{activations} in LLMs: we propose to add low-rank weight matrices in full precision that act on the \emph{unquantized} activations. We then solve a joint optimization problem over the quantized representation of the weights and additional low-rank weight matrices to quantize both weights and activations. We focus on the case of 4-bit weight-and-activation quantization (W4A4). Using ranks equivalent to 10\% of the original weight matrix size, our approach reduces the accuracy gap with the original model by more than 50\%. Using ranks equivalent to 30\% of the original weight matrix, the accuracy gap is closed completely. We demonstrate our results on four recent LLMs, namely Llama-2, Llama-3, Phi-3 and Mixtral models.