 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Sampling from Masked Diffusion Models via Entropy Bounded Unmasking
May 30, 2025Recent masked diffusion models (MDMs) have shown competitive performance compared to autoregressive models (ARMs) for language modeling. While most literature has focused on performance enhancing sampling procedures, efficient sampling from MDMs has been scarcely explored. We make the observation that often a given sequence of partially masked tokens determines the values of multiple unknown tokens deterministically, meaning that a single prediction of a masked model holds additional information unused by standard sampling procedures. Based on this observation, we introduce EB-Sampler, a simple drop-in replacement for existing samplers, utilizing an Entropy Bounded unmasking procedure that dynamically unmasks multiple tokens in one function evaluation with predefined approximate error tolerance. We formulate the EB-Sampler as part of a broad family of adaptive samplers for which we provide an error analysis that motivates our algorithmic choices. EB-Sampler accelerates sampling from current state of the art MDMs by roughly 2-3x on standard coding and math reasoning benchmarks without loss in performance. We also validate the same procedure works well on smaller reasoning tasks including maze navigation and Sudoku, tasks ARMs often struggle with.
Learning Distributions over Permutations and Rankings with Factorized Representations
May 30, 2025



Learning distributions over permutations is a fundamental problem in machine learning, with applications in ranking, combinatorial optimization, structured prediction, and data association. Existing methods rely on mixtures of parametric families or neural networks with expensive variational inference procedures. In this work, we propose a novel approach that leverages alternative representations for permutations, including Lehmer codes, Fisher-Yates draws, and Insertion-Vectors. These representations form a bijection with the symmetric group, allowing for unconstrained learning using conventional deep learning techniques, and can represent any probability distribution over permutations. Our approach enables a trade-off between expressivity of the model family and computational requirements. In the least expressive and most computationally efficient case, our method subsumes previous families of well established probabilistic models over permutations, including Mallow's and the Repeated Insertion Model. Experiments indicate our method significantly outperforms current approaches on the jigsaw puzzle benchmark, a common task for permutation learning. However, we argue this benchmark is limited in its ability to assess learning probability distributions, as the target is a delta distribution (i.e., a single correct solution exists). We therefore propose two additional benchmarks: learning cyclic permutations and re-ranking movies based on user preference. We show that our method learns non-trivial distributions even in the least expressive mode, while traditional models fail to even generate valid permutations in this setting.
Transformers Can Navigate Mazes With Multi-Step Prediction
Dec 06, 2024



Despite their remarkable success in language modeling, transformers trained to predict the next token in a sequence struggle with long-term planning. This limitation is particularly evident in tasks requiring foresight to plan multiple steps ahead such as maze navigation. The standard next single token prediction objective, however, offers no explicit mechanism to predict multiple steps ahead - or revisit the path taken so far. Consequently, in this work we study whether explicitly predicting multiple steps ahead (and backwards) can improve transformers' maze navigation. We train parameter-matched transformers from scratch, under identical settings, to navigate mazes of varying types and sizes with standard next token prediction and MLM-U, an objective explicitly predicting multiple steps ahead and backwards. We find that MLM-U considerably improves transformers' ability to navigate mazes compared to standard next token prediction across maze types and complexities. We also find MLM-U training is 4x more sample efficient and converges 2x faster in terms of GPU training hours relative to next token training. Finally, for more complex mazes we find MLM-U benefits from scaling to larger transformers. Remarkably, we find transformers trained with MLM-U outperform larger transformers trained with next token prediction using additional supervision from A* search traces. We hope these findings underscore the promise of learning objectives to advance transformers' capacity for long-term planning.
MagicPIG: LSH Sampling for Efficient LLM Generation
Oct 21, 2024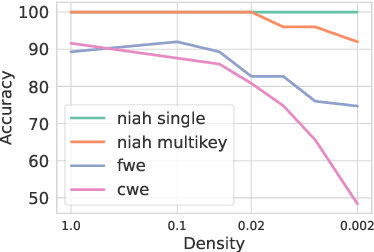
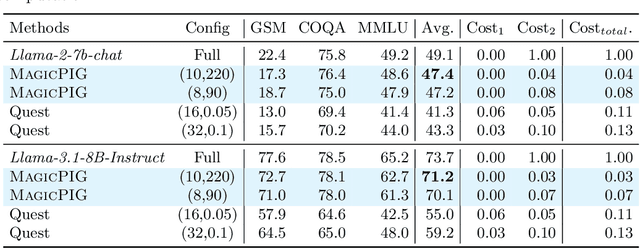
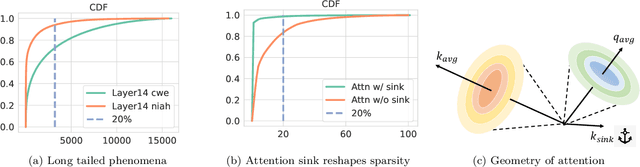
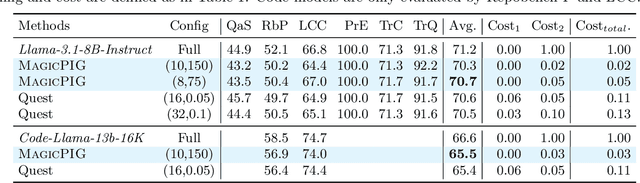
Large language models (LLMs) with long context windows have gained significant attention. However, the KV cache, stored to avoid re-computation, becomes a bottleneck. Various dynamic sparse or TopK-based attention approximation methods have been proposed to leverage the common insight that attention is sparse. In this paper, we first show that TopK attention itself suffers from quality degradation in certain downstream tasks because attention is not always as sparse as expected. Rather than selecting the keys and values with the highest attention scores, sampling with theoretical guarantees can provide a better estimation for attention output. To make the sampling-based approximation practical in LLM generation, we propose MagicPIG, a heterogeneous system based on Locality Sensitive Hashing (LSH). MagicPIG significantly reduces the workload of attention computation while preserving high accuracy for diverse tasks. MagicPIG stores the LSH hash tables and runs the attention computation on the CPU, which allows it to serve longer contexts and larger batch sizes with high approximation accuracy. MagicPIG can improve decoding throughput by $1.9\sim3.9\times$ across various GPU hardware and achieve 110ms decoding latency on a single RTX 4090 for Llama-3.1-8B-Instruct model with a context of 96k tokens. The code is available at \url{https://github.com/Infini-AI-Lab/MagicPIG}.
The Factorization Curse: Which Tokens You Predict Underlie the Reversal Curse and More
Jun 07, 2024



Today's best language models still struggle with hallucinations: factually incorrect generations, which impede their ability to reliably retrieve information seen during training. The reversal curse, where models cannot recall information when probed in a different order than was encountered during training, exemplifies this in information retrieval. We reframe the reversal curse as a factorization curse - a failure of models to learn the same joint distribution under different factorizations. Through a series of controlled experiments with increasing levels of realism including WikiReversal, a setting we introduce to closely simulate a knowledge intensive finetuning task, we find that the factorization curse is an inherent failure of the next-token prediction objective used in popular large language models. Moreover, we demonstrate reliable information retrieval cannot be solved with scale, reversed tokens, or even naive bidirectional-attention training. Consequently, various approaches to finetuning on specialized data would necessarily provide mixed results on downstream tasks, unless the model has already seen the right sequence of tokens. Across five tasks of varying levels of complexity, our results uncover a promising path forward: factorization-agnostic objectives can significantly mitigate the reversal curse and hint at improved knowledge storage and planning capabilities.
From Neurons to Neutrons: A Case Study in Interpretability
May 27, 2024Mechanistic Interpretability (MI) promises a path toward fully understanding how neural networks make their predictions. Prior work demonstrates that even when trained to perform simple arithmetic, models can implement a variety of algorithms (sometimes concurrently) depending on initialization and hyperparameters. Does this mean neuron-level interpretability techniques have limited applicability? We argue that high-dimensional neural networks can learn low-dimensional representations of their training data that are useful beyond simply making good predictions. Such representations can be understood through the mechanistic interpretability lens and provide insights that are surprisingly faithful to human-derived domain knowledge. This indicates that such approaches to interpretability can be useful for deriving a new understanding of a problem from models trained to solve it. As a case study, we extract nuclear physics concepts by studying models trained to reproduce nuclear data.
Memory Mosaics
May 10, 2024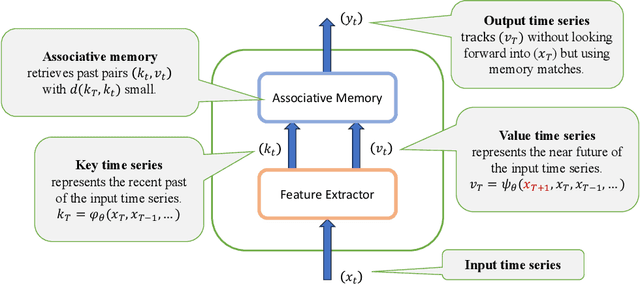
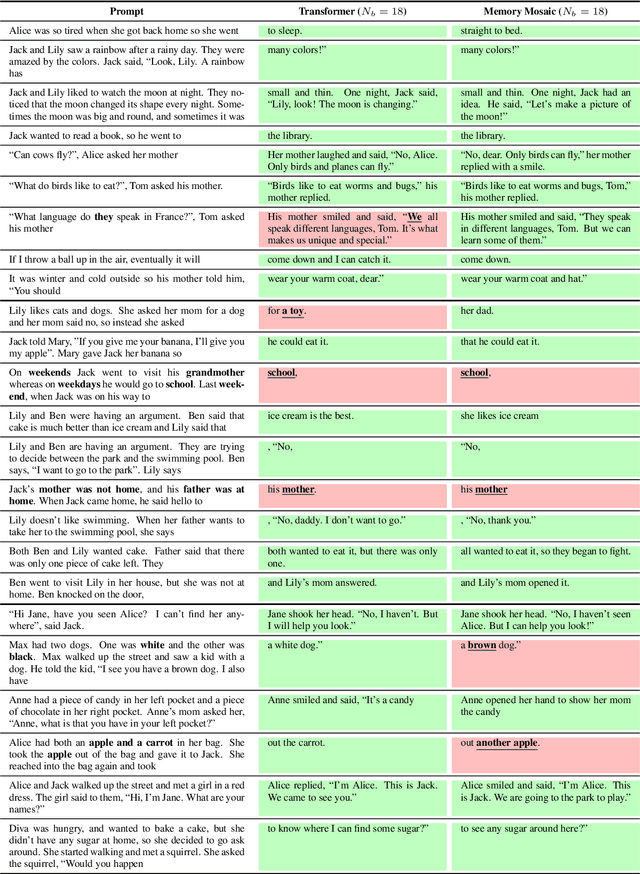


Memory Mosaics are networks of associative memories working in concert to achieve a prediction task of interest. Like transformers, memory mosaics possess compositional capabilities and in-context learning capabilities. Unlike transformers, memory mosaics achieve these capabilities in comparatively transparent ways. We demonstrate these capabilities on toy examples and we also show that memory mosaics perform as well or better than transformers on medium-scale language modeling tasks.
Transforming the Bootstrap: Using Transformers to Compute Scattering Amplitudes in Planar N = 4 Super Yang-Mills Theory
May 09, 2024



We pursue the use of deep learning methods to improve state-of-the-art computations in theoretical high-energy physics. Planar N = 4 Super Yang-Mills theory is a close cousin to the theory that describes Higgs boson production at the Large Hadron Collider; its scattering amplitudes are large mathematical expressions containing integer coefficients. In this paper, we apply Transformers to predict these coefficients. The problem can be formulated in a language-like representation amenable to standard cross-entropy training objectives. We design two related experiments and show that the model achieves high accuracy (> 98%) on both tasks. Our work shows that Transformers can be applied successfully to problems in theoretical physics that require exact solutions.
Salsa Fresca: Angular Embeddings and Pre-Training for ML Attacks on Learning With Errors
Feb 02, 2024



Learning with Errors (LWE) is a hard math problem underlying recently standardized post-quantum cryptography (PQC) systems for key exchange and digital signatures. Prior work proposed new machine learning (ML)-based attacks on LWE problems with small, sparse secrets, but these attacks require millions of LWE samples to train on and take days to recover secrets. We propose three key methods -- better preprocessing, angular embeddings and model pre-training -- to improve these attacks, speeding up preprocessing by $25\times$ and improving model sample efficiency by $10\times$. We demonstrate for the first time that pre-training improves and reduces the cost of ML attacks on LWE. Our architecture improvements enable scaling to larger-dimension LWE problems: this work is the first instance of ML attacks recovering sparse binary secrets in dimension $n=1024$, the smallest dimension used in practice for homomorphic encryption applications of LWE where sparse binary secrets are proposed.
KBFormer: A Diffusion Model for Structured Entity Completion
Dec 08, 2023We develop a generative attention-based approach to modeling structured entities comprising different property types, such as numerical, categorical, string, and composite. This approach handles such heterogeneous data through a mixed continuous-discrete diffusion process over the properties. Our flexible framework can model entities with arbitrary hierarchical properties, enabling applications to structured Knowledge Base (KB) entities and tabular data. Our approach obtains state-of-the-art performance on a majority of cases across 15 datasets. In addition, experiments with a device KB and a nuclear physics dataset demonstrate the model's ability to learn representations useful for entity completion in diverse settings. This has many downstream use cases, including modeling numerical properties with high accuracy - critical for science applications, which also benefit from the model's inherent probabilistic nature.