 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving ML Attacks on LWE with Data Repetition and Stepwise Regression
Apr 05, 2026The Learning with Errors (LWE) problem is a hard math problem in lattice-based cryptography. In the simplest case of binary secrets, it is the subset sum problem, with error. Effective ML attacks on LWE were demonstrated in the case of binary, ternary, and small secrets, succeeding on fairly sparse secrets. The ML attacks recover secrets with up to 3 active bits in the "cruel region" (Nolte et al., 2024) on samples pre-processed with BKZ. We show that using larger training sets and repeated examples enables recovery of denser secrets. Empirically, we observe a power-law relationship between model-based attempts to recover the secrets, dataset size, and repeated examples. We introduce a stepwise regression technique to recover the "cool bits" of the secret.
Transformers know more than they can tell -- Learning the Collatz sequence
Nov 13, 2025We investigate transformer prediction of long Collatz steps, a complex arithmetic function that maps odd integers to their distant successors in the Collatz sequence ( $u_{n+1}=u_n/2$ if $u_n$ is even, $u_{n+1}=(3u_n+1)/2$ if $u_n$ is odd). Model accuracy varies with the base used to encode input and output. It can be as high as $99.7\%$ for bases $24$ and $32$, and as low as $37$ and $25\%$ for bases $11$ and $3$. Yet, all models, no matter the base, follow a common learning pattern. As training proceeds, they learn a sequence of classes of inputs that share the same residual modulo $2^p$. Models achieve near-perfect accuracy on these classes, and less than $1\%$ for all other inputs. This maps to a mathematical property of Collatz sequences: the length of the loops involved in the computation of a long Collatz step can be deduced from the binary representation of its input. The learning pattern reflects the model learning to predict inputs associated with increasing loop lengths. An analysis of failure cases reveals that almost all model errors follow predictable patterns. Hallucination, a common feature of large language models, almost never happens. In over $90\%$ of failures, the model performs the correct calculation, but wrongly estimates loop lengths. Our observations give a full account of the algorithms learned by the models. They suggest that the difficulty of learning such complex arithmetic function lies in figuring the control structure of the computation -- the length of the loops. We believe that the approach outlined here, using mathematical problems as tools for understanding, explaining, and perhaps improving language models, can be applied to a broad range of problems and bear fruitful results.
Int2Int: a framework for mathematics with transformers
Feb 22, 2025This paper documents Int2Int, an open source code base for using transformers on problems of mathematical research, with a focus on number theory and other problems involving integers. Int2Int is a complete PyTorch implementation of a transformer architecture, together with training and evaluation loops, and classes and functions to represent, generate and decode common mathematical objects. Ancillary code for data preparation, and Jupyter Notebooks for visualizing experimental results are also provided. This document presents the main features of Int2Int, serves as its user manual, and provides guidelines on how to extend it. Int2Int is released under the MIT licence, at https://github.com/FacebookResearch/Int2Int.
Extrapolating Jet Radiation with Autoregressive Transformers
Dec 16, 2024



Generative networks are an exciting tool for fast LHC event generation. Usually, they are used to generate configurations with a fixed number of particles. Autoregressive transformers allow us to generate events with variable numbers of particles, very much in line with the physics of QCD jet radiation. We show how they can learn a factorized likelihood for jet radiation and extrapolate in terms of the number of generated jets. For this extrapolation, bootstrapping training data and training with modifications of the likelihood loss can be used.
PatternBoost: Constructions in Mathematics with a Little Help from AI
Nov 01, 2024We introduce PatternBoost, a flexible method for finding interesting constructions in mathematics. Our algorithm alternates between two phases. In the first ``local'' phase, a classical search algorithm is used to produce many desirable constructions. In the second ``global'' phase, a transformer neural network is trained on the best such constructions. Samples from the trained transformer are then used as seeds for the first phase, and the process is repeated. We give a detailed introduction to this technique, and discuss the results of its application to several problems in extremal combinatorics. The performance of PatternBoost varies across different problems, but there are many situations where its performance is quite impressive. Using our technique, we find the best known solutions to several long-standing problems, including the construction of a counterexample to a conjecture that had remained open for 30 years.
Global Lyapunov functions: a long-standing open problem in mathematics, with symbolic transformers
Oct 10, 2024



Despite their spectacular progress, language models still struggle on complex reasoning tasks, such as advanced mathematics. We consider a long-standing open problem in mathematics: discovering a Lyapunov function that ensures the global stability of a dynamical system. This problem has no known general solution, and algorithmic solvers only exist for some small polynomial systems. We propose a new method for generating synthetic training samples from random solutions, and show that sequence-to-sequence transformers trained on such datasets perform better than algorithmic solvers and humans on polynomial systems, and can discover new Lyapunov functions for non-polynomial systems.
Emergent properties with repeated examples
Oct 09, 2024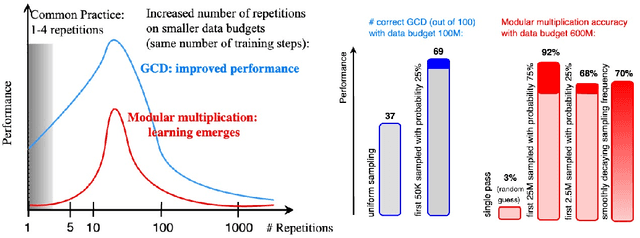

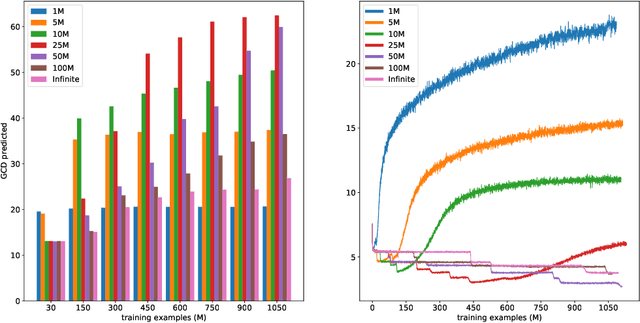
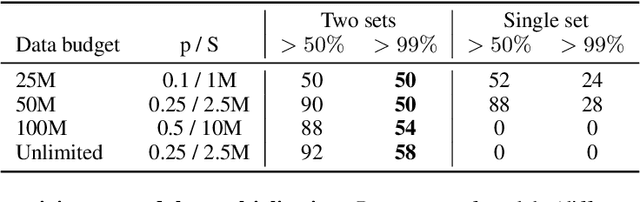
We study the performance of transformers as a function of the number of repetitions of training examples with algorithmically generated datasets. On three problems of mathematics: the greatest common divisor, modular multiplication, and matrix eigenvalues, we show that for a fixed number of training steps, models trained on smaller sets of repeated examples outperform models trained on larger sets of single-use examples. We also demonstrate that two-set training - repeated use of a small random subset of examples, along normal sampling on the rest of the training set - provides for faster learning and better performance. This highlights that the benefits of repetition can outweigh those of data diversity. These datasets and problems provide a controlled setting to shed light on the still poorly understood interplay between generalization and memorization in deep learning.
Transforming the Bootstrap: Using Transformers to Compute Scattering Amplitudes in Planar N = 4 Super Yang-Mills Theory
May 09, 2024



We pursue the use of deep learning methods to improve state-of-the-art computations in theoretical high-energy physics. Planar N = 4 Super Yang-Mills theory is a close cousin to the theory that describes Higgs boson production at the Large Hadron Collider; its scattering amplitudes are large mathematical expressions containing integer coefficients. In this paper, we apply Transformers to predict these coefficients. The problem can be formulated in a language-like representation amenable to standard cross-entropy training objectives. We design two related experiments and show that the model achieves high accuracy (> 98%) on both tasks. Our work shows that Transformers can be applied successfully to problems in theoretical physics that require exact solutions.
Salsa Fresca: Angular Embeddings and Pre-Training for ML Attacks on Learning With Errors
Feb 02, 2024



Learning with Errors (LWE) is a hard math problem underlying recently standardized post-quantum cryptography (PQC) systems for key exchange and digital signatures. Prior work proposed new machine learning (ML)-based attacks on LWE problems with small, sparse secrets, but these attacks require millions of LWE samples to train on and take days to recover secrets. We propose three key methods -- better preprocessing, angular embeddings and model pre-training -- to improve these attacks, speeding up preprocessing by $25\times$ and improving model sample efficiency by $10\times$. We demonstrate for the first time that pre-training improves and reduces the cost of ML attacks on LWE. Our architecture improvements enable scaling to larger-dimension LWE problems: this work is the first instance of ML attacks recovering sparse binary secrets in dimension $n=1024$, the smallest dimension used in practice for homomorphic encryption applications of LWE where sparse binary secrets are proposed.
Can transformers learn the greatest common divisor?
Aug 29, 2023
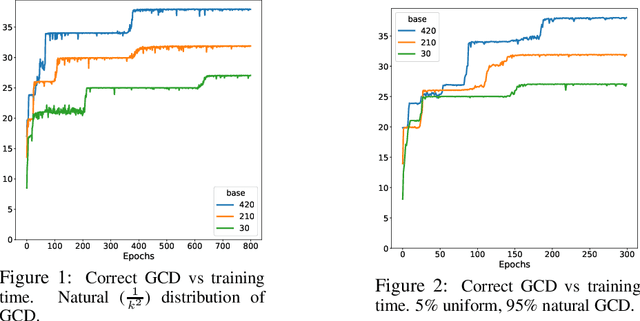
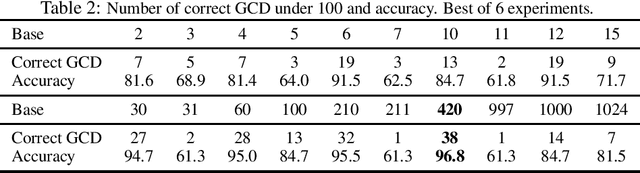
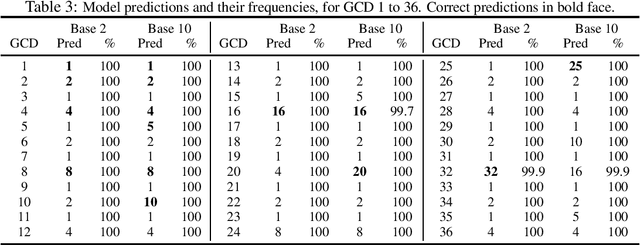
I investigate the capability of small transformers to compute the greatest common divisor (GCD) of two positive integers. When the training distribution and the representation base are carefully chosen, models achieve 98% accuracy and correctly predict 91 of the 100 first GCD. Model predictions are deterministic and fully interpretable. During training, the models learn to cluster input pairs with the same GCD, and classify them by their divisors. Basic models, trained from uniform operands encoded on small bases, only compute a handful of GCD (up to 38 out of 100): the products of divisors of the base. Longer training and larger bases allow some models to "grok" small prime GCD. Training from log-uniform operands boosts performance to 73 correct GCD, and balancing the training distribution of GCD, from inverse square to log-uniform, to 91 GCD. Training models from a uniform distribution of GCD breaks the deterministic model behavior.