 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalizing Mathematics at Scale
May 28, 2026We present AutoformBot, a multi-agent system for building an Autoformalized Textbook Library At Scale (Atlas) in Lean 4. AutoformBot orchestrates thousands of LLM agents, equipped with formal verification tools, dependency-aware task scheduling, and collaborative version control, to translate informal textbook prose into machine-checked definitions and proofs. We apply our methods to a corpus of 26 open-access textbooks spanning analysis, algebra, topology, combinatorics, and probability, producing Atlas: a verified library of over 45,000 Lean 4 declarations and 500 thousand lines of code. We release two artifacts: (i) AutoformBot, the open-source multi-agent framework; and (ii) Atlas, the resulting formal library. Our results suggest that autoformalizing the core content of graduate-level mathematics at scale is now economically and technically feasible. This opens the door to the automated verification of both human- and machine-generated mathematics at a research level.
Automatic Textbook Formalization
Apr 03, 2026We present a case study where an automatic AI system formalizes a textbook with more than 500 pages of graduate-level algebraic combinatorics to Lean. The resulting formalization represents a new milestone in textbook formalization scale and proficiency, moving from early results in undergraduate topology and restructuring of existing library content to a full standalone formalization of a graduate textbook. The formalization comprises 130K lines of code and 5900 Lean declarations and was conducted within one week by a total of 30K Claude 4.5 Opus agents collaborating in parallel on a shared code base via version control, simultaneously setting a record in multi-agent software engineering with usable results. The inference cost matches or undercuts what we estimate as the salaries required for a team of human experts, and we expect there is still the potential for large efficiencies to be made without the need for better models. We make our code, the resulting Lean code base and a side-by-side blueprint website available open-source.
WybeCoder: Verified Imperative Code Generation
Mar 31, 2026Recent progress in large language models (LLMs) has advanced automatic code generation and formal theorem proving, yet software verification has not seen the same improvement. To address this gap, we propose WybeCoder, an agentic code verification framework that enables prove-as-you-generate development where code, invariants, and proofs co-evolve. It builds on a recent framework that combines automatic verification condition generation and SMT solvers with interactive proofs in Lean. To enable systematic evaluation, we translate two benchmarks for functional verification in Lean, Verina and Clever, to equivalent imperative code specifications. On complex algorithms such as Heapsort, we observe consistent performance improvements by scaling our approach, synthesizing dozens of valid invariants and dispatching of dozens of subgoals, resulting in hundreds of lines of verified code, overcoming plateaus reported in previous works. Our best system solves 74% of Verina tasks and 62% of Clever tasks at moderate compute budgets, significantly surpassing previous evaluations and paving a path to automated construction of large-scale datasets of verified imperative code.
LemmaBench: A Live, Research-Level Benchmark to Evaluate LLM Capabilities in Mathematics
Feb 27, 2026We present a new approach for benchmarking Large Language Model (LLM) capabilities on research-level mathematics. Existing benchmarks largely rely on static, hand-curated sets of contest or textbook-style problems as proxies for mathematical research. Instead, we establish an updatable benchmark evaluating models directly on the latest research results in mathematics. This consists of an automatic pipeline that extracts lemmas from arXiv and rewrites them into self-contained statements by making all assumptions and required definitions explicit. It results in a benchmark that can be updated regularly with new problems taken directly from human mathematical research, while previous instances can be used for training without compromising future evaluations. We benchmark current state-of-the-art LLMs, which obtain around 10-15$\%$ accuracy in theorem proving (pass@1) depending on the model, showing that there is currently a large margin of progression for LLMs to reach human-level proving capabilities in a research context.
Traffic Flow Reconstruction from Limited Collected Data
Feb 11, 2026We propose an efficient method for reconstructing traffic density with low penetration rate of probe vehicles. Specifically, we rely on measuring only the initial and final positions of a small number of cars which are generated using microscopic dynamical systems. We then implement a machine learning algorithm from scratch to reconstruct the approximate traffic density. This approach leverages learning techniques to improve the accuracy of density reconstruction despite constraints in available data. For the sake of consistency, we will prove that, if only using data from dynamical systems, the approximate density predicted by our learned-based model converges to a well-known macroscopic traffic flow model when the number of vehicles approaches infinity.
Global Lyapunov functions: a long-standing open problem in mathematics, with symbolic transformers
Oct 10, 2024



Despite their spectacular progress, language models still struggle on complex reasoning tasks, such as advanced mathematics. We consider a long-standing open problem in mathematics: discovering a Lyapunov function that ensures the global stability of a dynamical system. This problem has no known general solution, and algorithmic solvers only exist for some small polynomial systems. We propose a new method for generating synthetic training samples from random solutions, and show that sequence-to-sequence transformers trained on such datasets perform better than algorithmic solvers and humans on polynomial systems, and can discover new Lyapunov functions for non-polynomial systems.
HyperTree Proof Search for Neural Theorem Proving
May 23, 2022

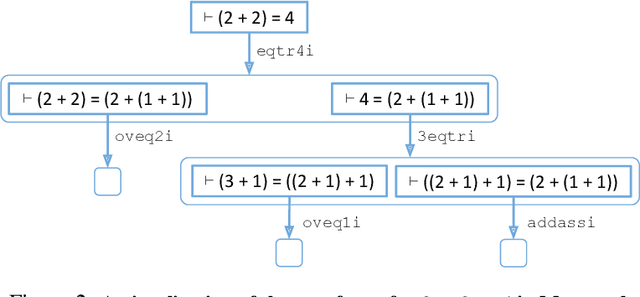
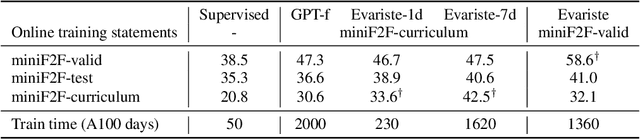
We propose an online training procedure for a transformer-based automated theorem prover. Our approach leverages a new search algorithm, HyperTree Proof Search (HTPS), inspired by the recent success of AlphaZero. Our model learns from previous proof searches through online training, allowing it to generalize to domains far from the training distribution. We report detailed ablations of our pipeline's main components by studying performance on three environments of increasing complexity. In particular, we show that with HTPS alone, a model trained on annotated proofs manages to prove 65.4% of a held-out set of Metamath theorems, significantly outperforming the previous state of the art of 56.5% by GPT-f. Online training on these unproved theorems increases accuracy to 82.6%. With a similar computational budget, we improve the state of the art on the Lean-based miniF2F-curriculum dataset from 31% to 42% proving accuracy.
A deep language model to predict metabolic network equilibria
Dec 07, 2021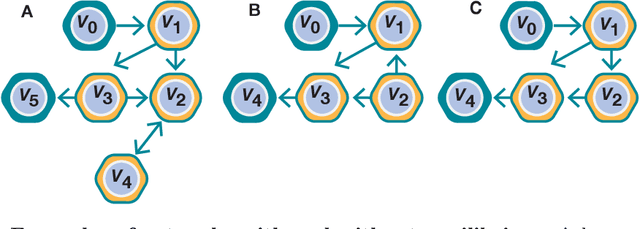


We show that deep learning models, and especially architectures like the Transformer, originally intended for natural language, can be trained on randomly generated datasets to predict to very high accuracy both the qualitative and quantitative features of metabolic networks. Using standard mathematical techniques, we create large sets (40 million elements) of random networks that can be used to train our models. These trained models can predict network equilibrium on random graphs in more than 99% of cases. They can also generalize to graphs with different structure than those encountered at training. Finally, they can predict almost perfectly the equilibria of a small set of known biological networks. Our approach is both very economical in experimental data and uses only small and shallow deep-learning model, far from the large architectures commonly used in machine translation. Such results pave the way for larger use of deep learning models for problems related to biological networks in key areas such as quantitative systems pharmacology, systems biology, and synthetic biology.
Deep Differential System Stability -- Learning advanced computations from examples
Jun 11, 2020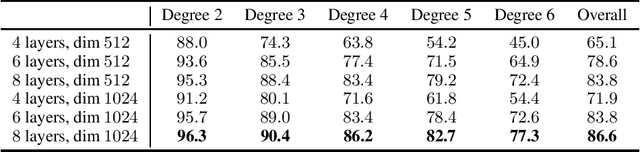

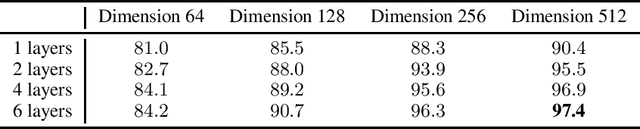
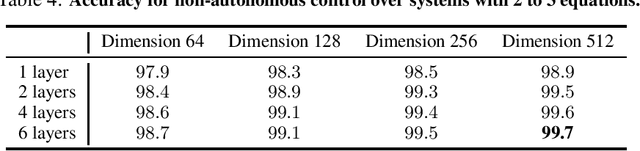
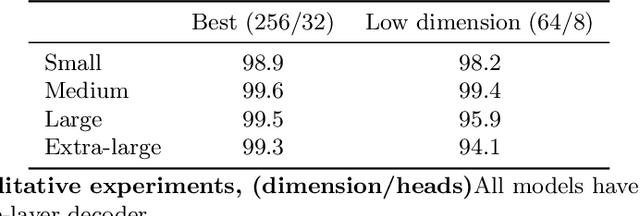
Can advanced mathematical computations be learned from examples? Using transformers over large generated datasets, we train models to learn properties of differential systems, such as local stability, behavior at infinity and controllability. We achieve near perfect estimates of qualitative characteristics of the systems, and good approximations of numerical quantities, demonstrating that neural networks can learn advanced theorems and complex computations without built-in mathematical knowledge.