 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Generative Amplification
Sep 09, 2025Generative networks are perfect tools to enhance the speed and precision of LHC simulations. It is important to understand their statistical precision, especially when generating events beyond the size of the training dataset. We present two complementary methods to estimate the amplification factor without large holdout datasets. Averaging amplification uses Bayesian networks or ensembling to estimate amplification from the precision of integrals over given phase-space volumes. Differential amplification uses hypothesis testing to quantify amplification without any resolution loss. Applied to state-of-the-art event generators, both methods indicate that amplification is possible in specific regions of phase space, but not yet across the entire distribution.
Lorentz Local Canonicalization: How to Make Any Network Lorentz-Equivariant
May 26, 2025
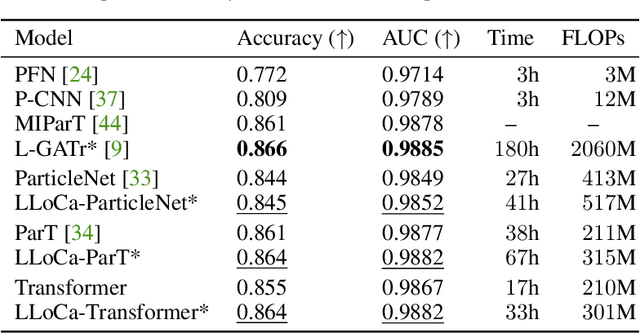
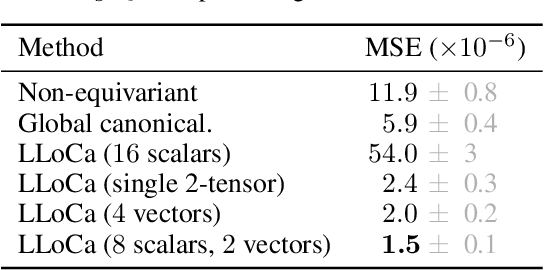
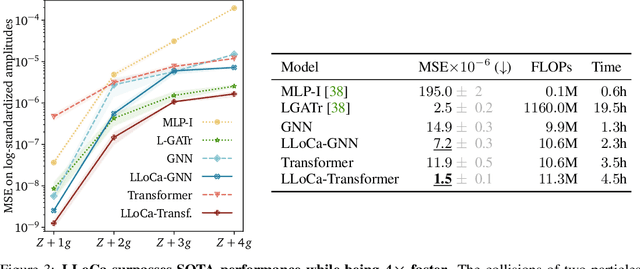
Lorentz-equivariant neural networks are becoming the leading architectures for high-energy physics. Current implementations rely on specialized layers, limiting architectural choices. We introduce Lorentz Local Canonicalization (LLoCa), a general framework that renders any backbone network exactly Lorentz-equivariant. Using equivariantly predicted local reference frames, we construct LLoCa-transformers and graph networks. We adapt a recent approach to geometric message passing to the non-compact Lorentz group, allowing propagation of space-time tensorial features. Data augmentation emerges from LLoCa as a special choice of reference frame. Our models surpass state-of-the-art accuracy on relevant particle physics tasks, while being $4\times$ faster and using $5$-$100\times$ fewer FLOPs.
Extrapolating Jet Radiation with Autoregressive Transformers
Dec 16, 2024



Generative networks are an exciting tool for fast LHC event generation. Usually, they are used to generate configurations with a fixed number of particles. Autoregressive transformers allow us to generate events with variable numbers of particles, very much in line with the physics of QCD jet radiation. We show how they can learn a factorized likelihood for jet radiation and extrapolate in terms of the number of generated jets. For this extrapolation, bootstrapping training data and training with modifications of the likelihood loss can be used.
A Lorentz-Equivariant Transformer for All of the LHC
Nov 01, 2024We show that the Lorentz-Equivariant Geometric Algebra Transformer (L-GATr) yields state-of-the-art performance for a wide range of machine learning tasks at the Large Hadron Collider. L-GATr represents data in a geometric algebra over space-time and is equivariant under Lorentz transformations. The underlying architecture is a versatile and scalable transformer, which is able to break symmetries if needed. We demonstrate the power of L-GATr for amplitude regression and jet classification, and then benchmark it as the first Lorentz-equivariant generative network. For all three LHC tasks, we find significant improvements over previous architectures.
Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics
May 23, 2024Extracting scientific understanding from particle-physics experiments requires solving diverse learning problems with high precision and good data efficiency. We propose the Lorentz Geometric Algebra Transformer (L-GATr), a new multi-purpose architecture for high-energy physics. L-GATr represents high-energy data in a geometric algebra over four-dimensional space-time and is equivariant under Lorentz transformations, the symmetry group of relativistic kinematics. At the same time, the architecture is a Transformer, which makes it versatile and scalable to large systems. L-GATr is first demonstrated on regression and classification tasks from particle physics. We then construct the first Lorentz-equivariant generative model: a continuous normalizing flow based on an L-GATr network, trained with Riemannian flow matching. Across our experiments, L-GATr is on par with or outperforms strong domain-specific baselines.