 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lorentz-Equivariant Transformer for All of the LHC
Nov 01, 2024We show that the Lorentz-Equivariant Geometric Algebra Transformer (L-GATr) yields state-of-the-art performance for a wide range of machine learning tasks at the Large Hadron Collider. L-GATr represents data in a geometric algebra over space-time and is equivariant under Lorentz transformations. The underlying architecture is a versatile and scalable transformer, which is able to break symmetries if needed. We demonstrate the power of L-GATr for amplitude regression and jet classification, and then benchmark it as the first Lorentz-equivariant generative network. For all three LHC tasks, we find significant improvements over previous architectures.
Moment Unfolding
Jul 15, 2024



Deconvolving ("unfolding'') detector distortions is a critical step in the comparison of cross section measurements with theoretical predictions in particle and nuclear physics. However, most existing approaches require histogram binning while many theoretical predictions are at the level of statistical moments. We develop a new approach to directly unfold distribution moments as a function of another observable without having to first discretize the data. Our Moment Unfolding technique uses machine learning and is inspired by Generative Adversarial Networks (GANs). We demonstrate the performance of this approach using jet substructure measurements in collider physics. With this illustrative example, we find that our Moment Unfolding protocol is more precise than bin-based approaches and is as or more precise than completely unbinned methods.
Lorentz-Equivariant Geometric Algebra Transformers for High-Energy Physics
May 23, 2024Extracting scientific understanding from particle-physics experiments requires solving diverse learning problems with high precision and good data efficiency. We propose the Lorentz Geometric Algebra Transformer (L-GATr), a new multi-purpose architecture for high-energy physics. L-GATr represents high-energy data in a geometric algebra over four-dimensional space-time and is equivariant under Lorentz transformations, the symmetry group of relativistic kinematics. At the same time, the architecture is a Transformer, which makes it versatile and scalable to large systems. L-GATr is first demonstrated on regression and classification tasks from particle physics. We then construct the first Lorentz-equivariant generative model: a continuous normalizing flow based on an L-GATr network, trained with Riemannian flow matching. Across our experiments, L-GATr is on par with or outperforms strong domain-specific baselines.
PAPERCLIP: Associating Astronomical Observations and Natural Language with Multi-Modal Models
Mar 13, 2024



We present PAPERCLIP (Proposal Abstracts Provide an Effective Representation for Contrastive Language-Image Pre-training), a method which associates astronomical observations imaged by telescopes with natural language using a neural network model. The model is fine-tuned from a pre-trained Contrastive Language-Image Pre-training (CLIP) model using successful observing proposal abstracts and corresponding downstream observations, with the abstracts optionally summarized via guided generation using large language models (LLMs). Using observations from the Hubble Space Telescope (HST) as an example, we show that the fine-tuned model embodies a meaningful joint representation between observations and natural language through tests targeting image retrieval (i.e., finding the most relevant observations using natural language queries) and description retrieval (i.e., querying for astrophysical object classes and use cases most relevant to a given observation). Our study demonstrates the potential for using generalist foundation models rather than task-specific models for interacting with astronomical data by leveraging text as an interface.
Moments of Clarity: Streamlining Latent Spaces in Machine Learning using Moment Pooling
Mar 13, 2024Many machine learning applications involve learning a latent representation of data, which is often high-dimensional and difficult to directly interpret. In this work, we propose "Moment Pooling", a natural extension of Deep Sets networks which drastically decrease latent space dimensionality of these networks while maintaining or even improving performance. Moment Pooling generalizes the summation in Deep Sets to arbitrary multivariate moments, which enables the model to achieve a much higher effective latent dimensionality for a fixed latent dimension. We demonstrate Moment Pooling on the collider physics task of quark/gluon jet classification by extending Energy Flow Networks (EFNs) to Moment EFNs. We find that Moment EFNs with latent dimensions as small as 1 perform similarly to ordinary EFNs with higher latent dimension. This small latent dimension allows for the internal representation to be directly visualized and interpreted, which in turn enables the learned internal jet representation to be extracted in closed form.
EPiC-GAN: Equivariant Point Cloud Generation for Particle Jets
Jan 17, 2023With the vast data-collecting capabilities of current and future high-energy collider experiments, there is an increasing demand for computationally efficient simulations. Generative machine learning models enable fast event generation, yet so far these approaches are largely constrained to fixed data structures and rigid detector geometries. In this paper, we introduce EPiC-GAN - equivariant point cloud generative adversarial network - which can produce point clouds of variable multiplicity. This flexible framework is based on deep sets and is well suited for simulating sprays of particles called jets. The generator and discriminator utilize multiple EPiC layers with an interpretable global latent vector. Crucially, the EPiC layers do not rely on pairwise information sharing between particles, which leads to a significant speed-up over graph- and transformer-based approaches with more complex relation diagrams. We demonstrate that EPiC-GAN scales well to large particle multiplicities and achieves high generation fidelity on benchmark jet generation tasks.
Bias and Priors in Machine Learning Calibrations for High Energy Physics
May 10, 2022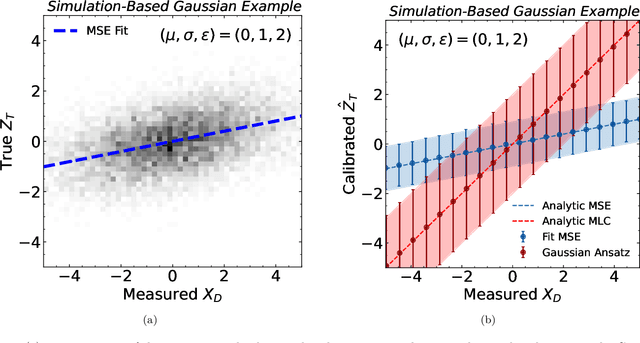
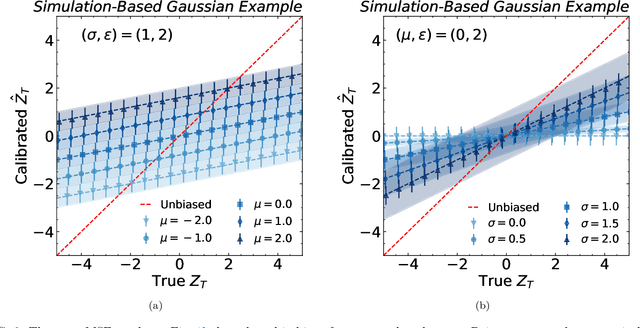
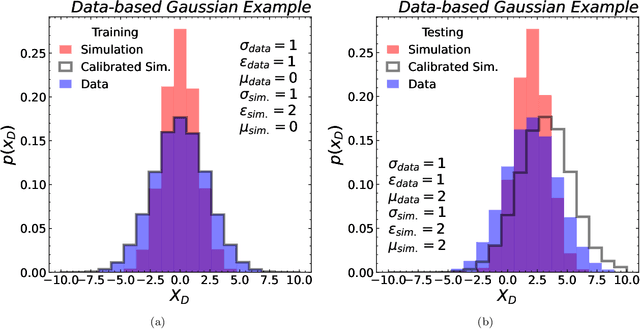
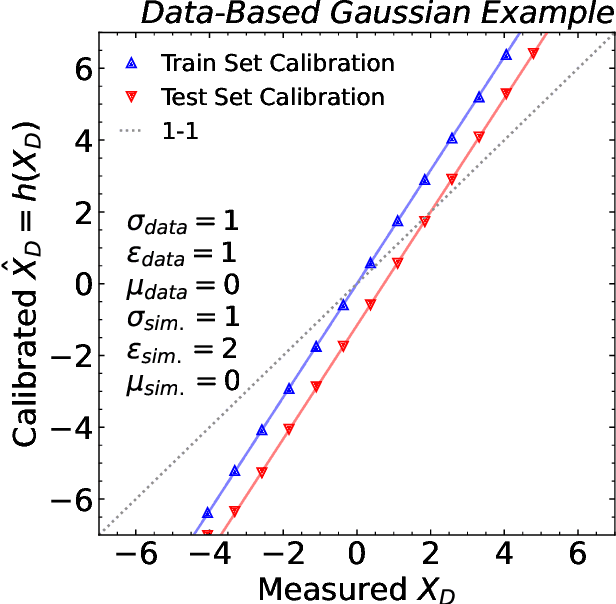
Machine learning offers an exciting opportunity to improve the calibration of nearly all reconstructed objects in high-energy physics detectors. However, machine learning approaches often depend on the spectra of examples used during training, an issue known as prior dependence. This is an undesirable property of a calibration, which needs to be applicable in a variety of environments. The purpose of this paper is to explicitly highlight the prior dependence of some machine learning-based calibration strategies. We demonstrate how some recent proposals for both simulation-based and data-based calibrations inherit properties of the sample used for training, which can result in biases for downstream analyses. In the case of simulation-based calibration, we argue that our recently proposed Gaussian Ansatz approach can avoid some of the pitfalls of prior dependence, whereas prior-independent data-based calibration remains an open problem.
Scaffolding Simulations with Deep Learning for High-dimensional Deconvolution
May 10, 2021

A common setting for scientific inference is the ability to sample from a high-fidelity forward model (simulation) without having an explicit probability density of the data. We propose a simulation-based maximum likelihood deconvolution approach in this setting called OmniFold. Deep learning enables this approach to be naturally unbinned and (variable-, and) high-dimensional. In contrast to model parameter estimation, the goal of deconvolution is to remove detector distortions in order to enable a variety of down-stream inference tasks. Our approach is the deep learning generalization of the common Richardson-Lucy approach that is also called Iterative Bayesian Unfolding in particle physics. We show how OmniFold can not only remove detector distortions, but it can also account for noise processes and acceptance effects.
* 6 pages, 1 figure, 1 table
E Pluribus Unum Ex Machina: Learning from Many Collider Events at Once
Feb 07, 2021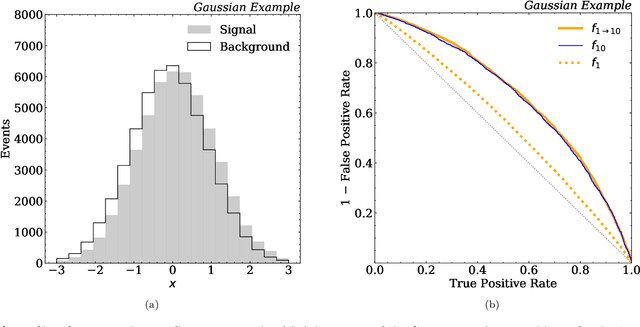
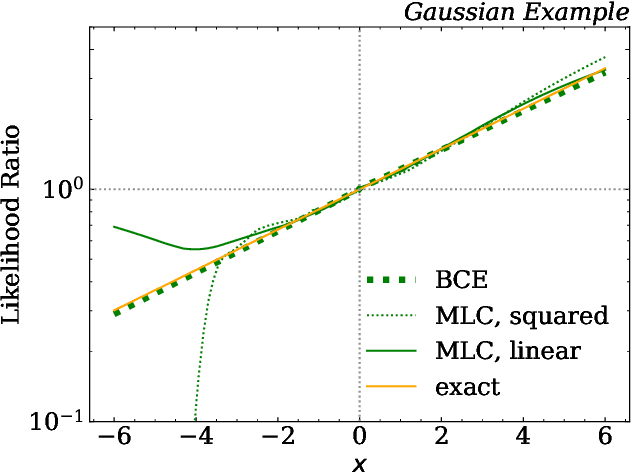


There have been a number of recent proposals to enhance the performance of machine learning strategies for collider physics by combining many distinct events into a single ensemble feature. To evaluate the efficacy of these proposals, we study the connection between single-event classifiers and multi-event classifiers under the assumption that collider events are independent and identically distributed (IID). We show how one can build optimal multi-event classifiers from single-event classifiers, and we also show how to construct multi-event classifiers such that they produce optimal single-event classifiers. This is illustrated for a Gaussian example as well as for classification tasks relevant for searches and measurements at the Large Hadron Collider. We extend our discussion to regression tasks by showing how they can be phrased in terms of parametrized classifiers. Empirically, we find that training a single-event (per-instance) classifier is more effective than training a multi-event (per-ensemble) classifier, as least for the cases we studied, and we relate this fact to properties of the loss function gradient in the two cases. While we did not identify a clear benefit from using multi-event classifiers in the collider context, we speculate on the potential value of these methods in cases involving only approximate independence, as relevant for jet substructure studies.
OmniFold: A Method to Simultaneously Unfold All Observables
Nov 20, 2019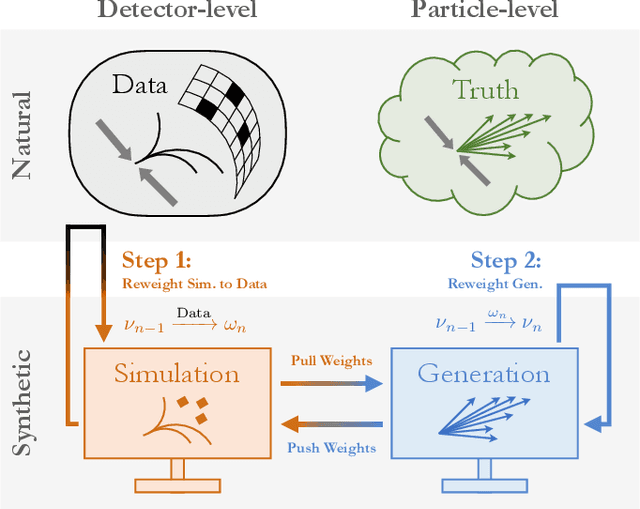
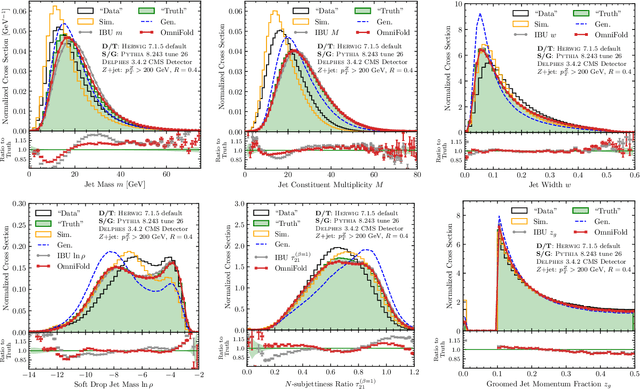
Collider data must be corrected for detector effects ("unfolded") to be compared with theoretical calculations and measurements from other experiments. Unfolding is traditionally done for individual, binned observables without including all information relevant for characterizing the detector response. We introduce OmniFold, an unfolding method that iteratively reweights a simulated dataset, using machine learning to capitalize on all available information. Our approach is unbinned, works for arbitrarily high-dimensional data, and naturally incorporates information from the full phase space. We illustrate this technique on a realistic jet substructure example from the Large Hadron Collider and compare it to standard binned unfolding methods. This new paradigm enables the simultaneous measurement of all observables, including those not yet invented at the time of the analysis.