 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaffolding Simulations with Deep Learning for High-dimensional Deconvolution
May 10, 2021

A common setting for scientific inference is the ability to sample from a high-fidelity forward model (simulation) without having an explicit probability density of the data. We propose a simulation-based maximum likelihood deconvolution approach in this setting called OmniFold. Deep learning enables this approach to be naturally unbinned and (variable-, and) high-dimensional. In contrast to model parameter estimation, the goal of deconvolution is to remove detector distortions in order to enable a variety of down-stream inference tasks. Our approach is the deep learning generalization of the common Richardson-Lucy approach that is also called Iterative Bayesian Unfolding in particle physics. We show how OmniFold can not only remove detector distortions, but it can also account for noise processes and acceptance effects.
* 6 pages, 1 figure, 1 table
OmniFold: A Method to Simultaneously Unfold All Observables
Nov 20, 2019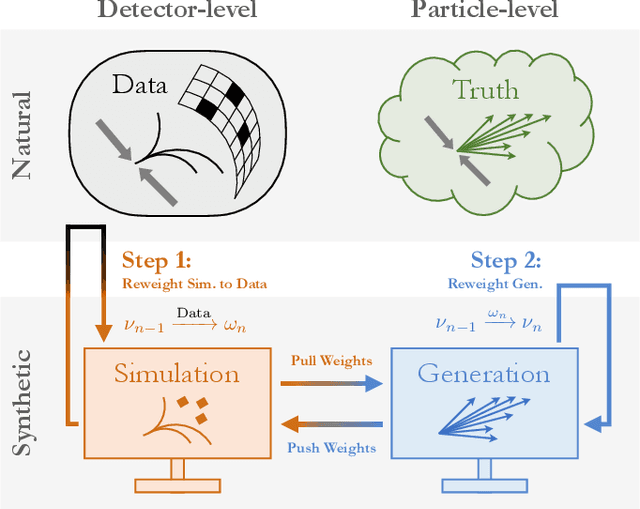
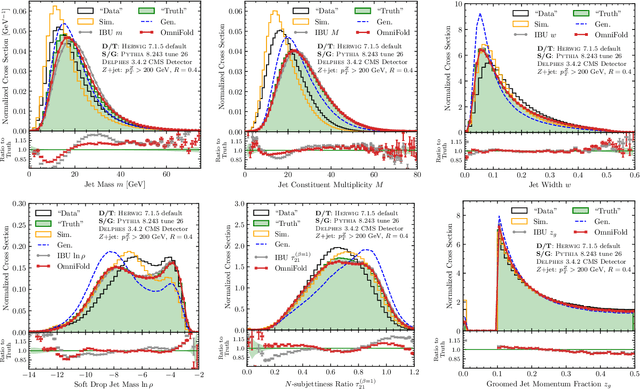
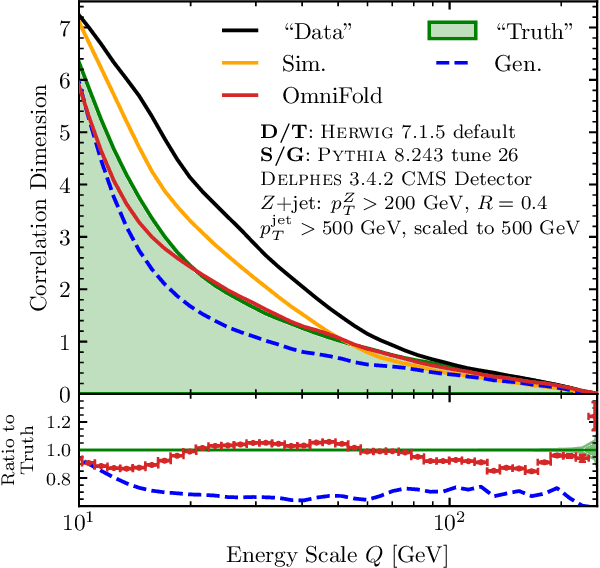
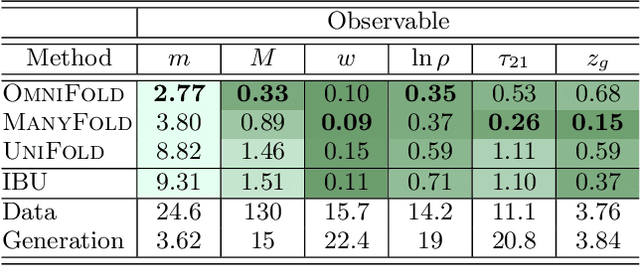
Collider data must be corrected for detector effects ("unfolded") to be compared with theoretical calculations and measurements from other experiments. Unfolding is traditionally done for individual, binned observables without including all information relevant for characterizing the detector response. We introduce OmniFold, an unfolding method that iteratively reweights a simulated dataset, using machine learning to capitalize on all available information. Our approach is unbinned, works for arbitrarily high-dimensional data, and naturally incorporates information from the full phase space. We illustrate this technique on a realistic jet substructure example from the Large Hadron Collider and compare it to standard binned unfolding methods. This new paradigm enables the simultaneous measurement of all observables, including those not yet invented at the time of the analysis.
Energy Flow Networks: Deep Sets for Particle Jets
Oct 11, 2018

A key question for machine learning approaches in particle physics is how to best represent and learn from collider events. As an event is intrinsically a variable-length unordered set of particles, we build upon recent machine learning efforts to learn directly from sets of features. Adapting and specializing the "Deep Sets" framework to particle physics, we introduce Energy Flow Networks, which respect infrared and collinear safety by construction. We also develop Particle Flow Networks, which allow for general energy dependence and the inclusion of additional particle-level information such as charge and flavor. These networks feature a per-particle internal (latent) representation, and summing over all particles yields an overall event-level latent representation. We show how this latent space decomposition unifies existing event representations based on detector images and radiation moments. To demonstrate the power and simplicity of this set-based approach, we apply these networks to the collider task of discriminating quark jets from gluon jets, finding similar or improved performance compared to existing methods. We also show how the learned event representation can be directly visualized, providing insight into the inner workings of the model. These architectures lend themselves to efficiently processing and analyzing events for a wide variety of tasks at the Large Hadron Collider. Implementations and examples of our architectures are available online in our EnergyFlow package.
Deep learning in color: towards automated quark/gluon jet discrimination
Sep 04, 2018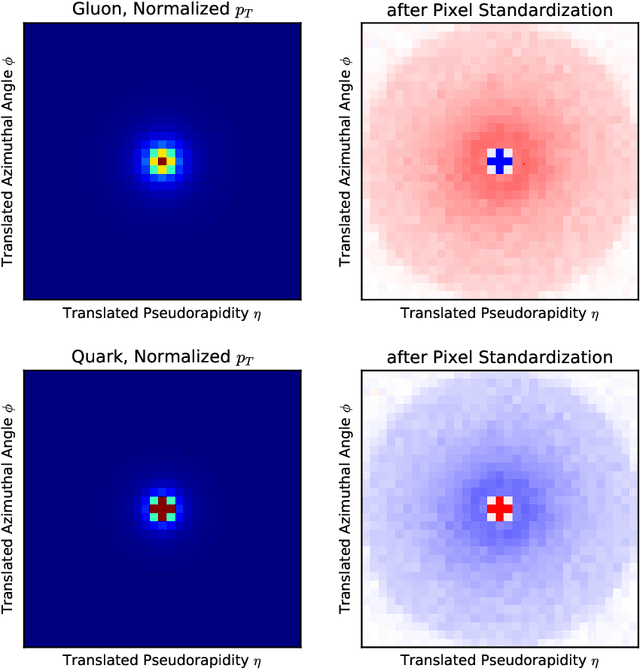



Artificial intelligence offers the potential to automate challenging data-processing tasks in collider physics. To establish its prospects, we explore to what extent deep learning with convolutional neural networks can discriminate quark and gluon jets better than observables designed by physicists. Our approach builds upon the paradigm that a jet can be treated as an image, with intensity given by the local calorimeter deposits. We supplement this construction by adding color to the images, with red, green and blue intensities given by the transverse momentum in charged particles, transverse momentum in neutral particles, and pixel-level charged particle counts. Overall, the deep networks match or outperform traditional jet variables. We also find that, while various simulations produce different quark and gluon jets, the neural networks are surprisingly insensitive to these differences, similar to traditional observables. This suggests that the networks can extract robust physical information from imperfect simulations.
* 23 pages, 9 figures, updated to JHEP version, added table of contents, minor typos fixed
Learning to Classify from Impure Samples with High-Dimensional Data
Jul 24, 2018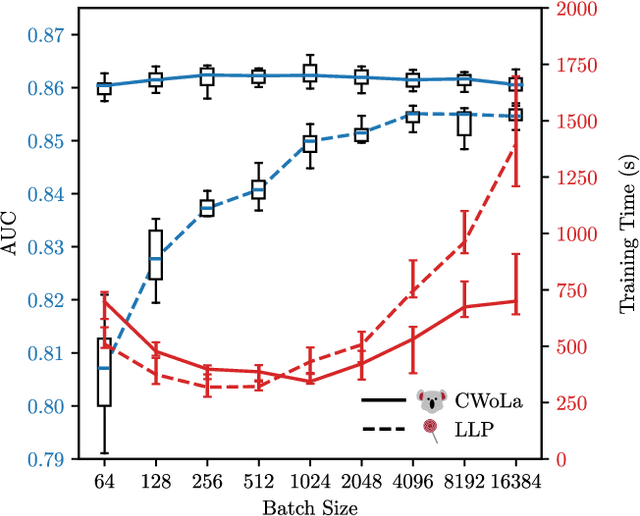



A persistent challenge in practical classification tasks is that labeled training sets are not always available. In particle physics, this challenge is surmounted by the use of simulations. These simulations accurately reproduce most features of data, but cannot be trusted to capture all of the complex correlations exploitable by modern machine learning methods. Recent work in weakly supervised learning has shown that simple, low-dimensional classifiers can be trained using only the impure mixtures present in data. Here, we demonstrate that complex, high-dimensional classifiers can also be trained on impure mixtures using weak supervision techniques, with performance comparable to what could be achieved with pure samples. Using weak supervision will therefore allow us to avoid relying exclusively on simulations for high-dimensional classification. This work opens the door to a new regime whereby complex models are trained directly on data, providing direct access to probe the underlying physics.
* 6 pages, 2 tables, 2 figures. v2: updated to match PRD version
On the Topic of Jets: Disentangling Quarks and Gluons at Colliders
Jun 07, 2018


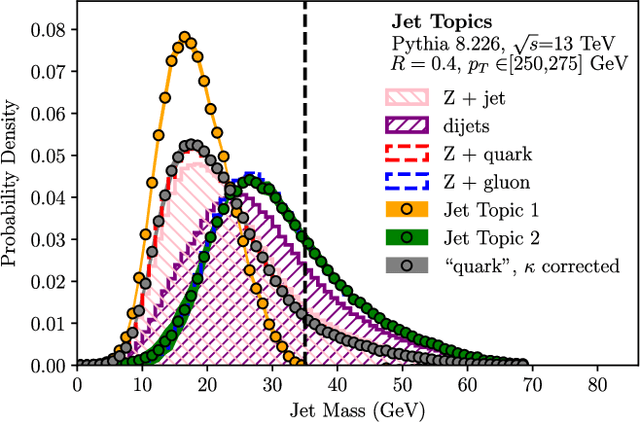
We introduce jet topics: a framework to identify underlying classes of jets from collider data. Because of a close mathematical relationship between distributions of observables in jets and emergent themes in sets of documents, we can apply recent techniques in "topic modeling" to extract jet topics from data with minimal or no input from simulation or theory. As a proof of concept with parton shower samples, we apply jet topics to determine separate quark and gluon jet distributions for constituent multiplicity. We also determine separate quark and gluon rapidity spectra from a mixed Z-plus-jet sample. While jet topics are defined directly from hadron-level multi-differential cross sections, one can also predict jet topics from first-principles theoretical calculations, with potential implications for how to define quark and gluon jets beyond leading-logarithmic accuracy. These investigations suggest that jet topics will be useful for extracting underlying jet distributions and fractions in a wide range of contexts at the Large Hadron Collider.
* 8 pages, 4 figures, 1 table. v2: Improved discussion to match PRL version
Pileup Mitigation with Machine Learning (PUMML)
Jan 08, 2018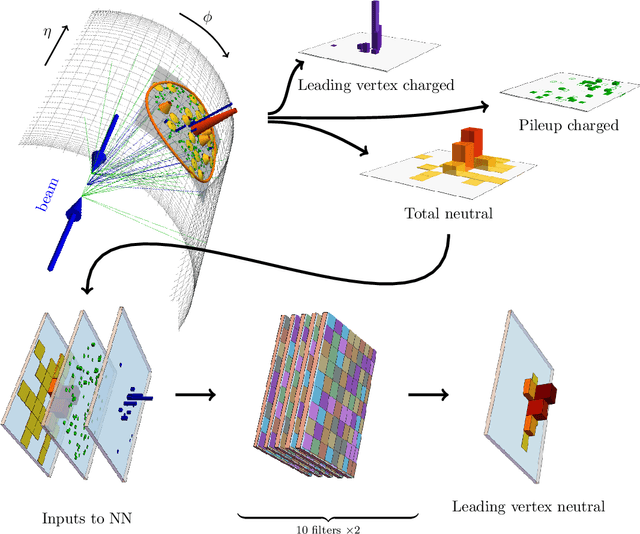
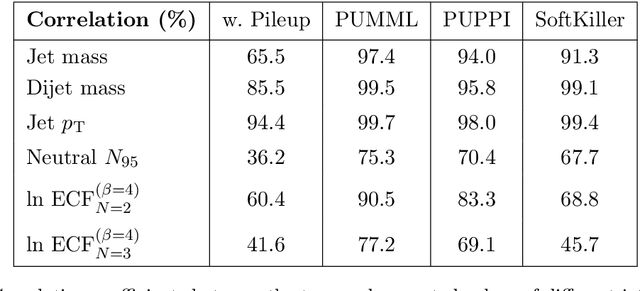
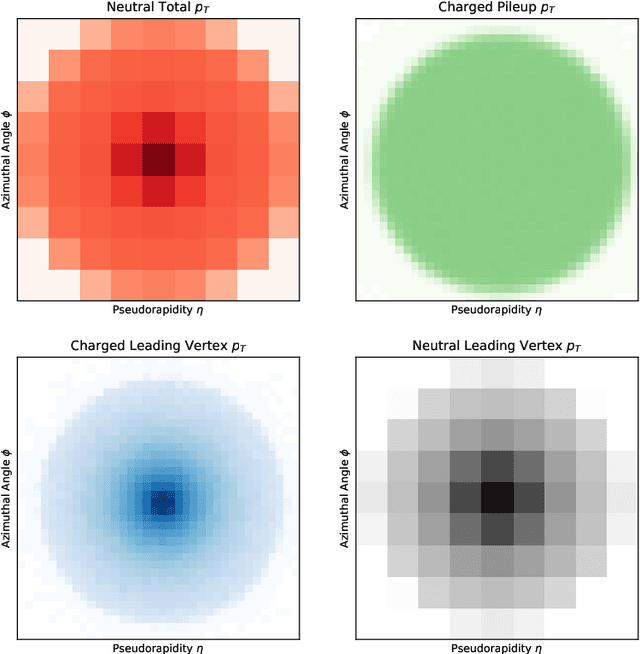
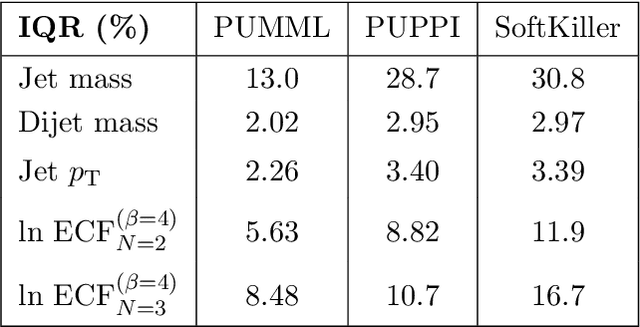
Pileup involves the contamination of the energy distribution arising from the primary collision of interest (leading vertex) by radiation from soft collisions (pileup). We develop a new technique for removing this contamination using machine learning and convolutional neural networks. The network takes as input the energy distribution of charged leading vertex particles, charged pileup particles, and all neutral particles and outputs the energy distribution of particles coming from leading vertex alone. The PUMML algorithm performs remarkably well at eliminating pileup distortion on a wide range of simple and complex jet observables. We test the robustness of the algorithm in a number of ways and discuss how the network can be trained directly on data.
* 20 pages, 8 figures, 2 tables. Updated to JHEP version
Classification without labels: Learning from mixed samples in high energy physics
Nov 18, 2017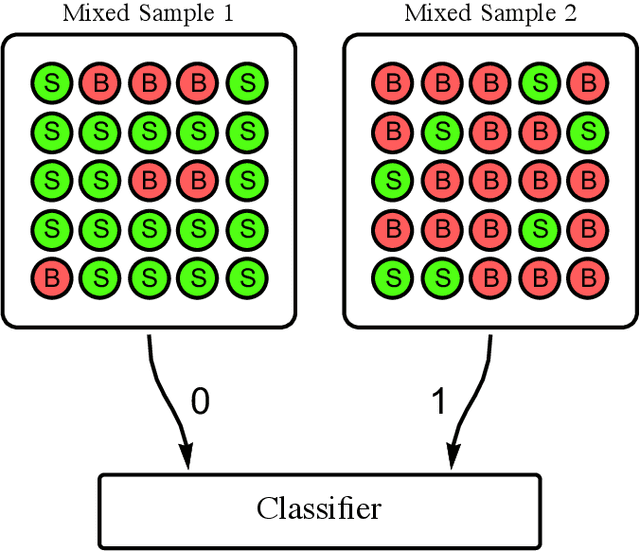
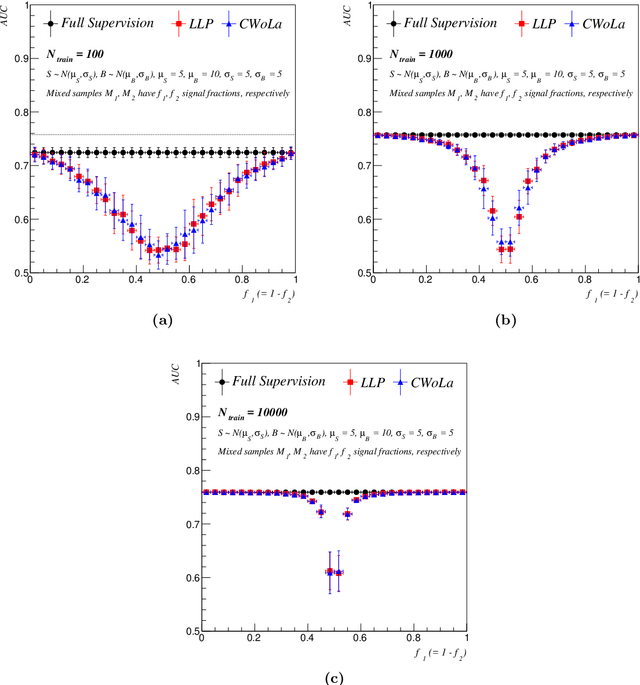
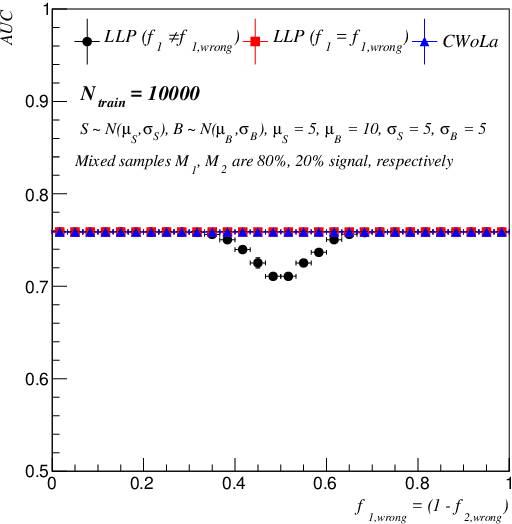

Modern machine learning techniques can be used to construct powerful models for difficult collider physics problems. In many applications, however, these models are trained on imperfect simulations due to a lack of truth-level information in the data, which risks the model learning artifacts of the simulation. In this paper, we introduce the paradigm of classification without labels (CWoLa) in which a classifier is trained to distinguish statistical mixtures of classes, which are common in collider physics. Crucially, neither individual labels nor class proportions are required, yet we prove that the optimal classifier in the CWoLa paradigm is also the optimal classifier in the traditional fully-supervised case where all label information is available. After demonstrating the power of this method in an analytical toy example, we consider a realistic benchmark for collider physics: distinguishing quark- versus gluon-initiated jets using mixed quark/gluon training samples. More generally, CWoLa can be applied to any classification problem where labels or class proportions are unknown or simulations are unreliable, but statistical mixtures of the classes are available.
* 18 pages, 5 figures; v2: intro extended and references added; v3: additional discussion to match JHEP version