 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Analysis of Pretrained Language Models for Text-to-Speech
Sep 04, 2023State-of-the-art text-to-speech (TTS) systems have utilized pretrained language models (PLMs) to enhance prosody and create more natural-sounding speech. However, while PLMs have been extensively researched for natural language understanding (NLU), their impact on TTS has been overlooked. In this study, we aim to address this gap by conducting a comparative analysis of different PLMs for two TTS tasks: prosody prediction and pause prediction. Firstly, we trained a prosody prediction model using 15 different PLMs. Our findings revealed a logarithmic relationship between model size and quality, as well as significant performance differences between neutral and expressive prosody. Secondly, we employed PLMs for pause prediction and found that the task was less sensitive to small models. We also identified a strong correlation between our empirical results and the GLUE scores obtained for these language models. To the best of our knowledge, this is the first study of its kind to investigate the impact of different PLMs on TTS.
eCat: An End-to-End Model for Multi-Speaker TTS & Many-to-Many Fine-Grained Prosody Transfer
Jun 20, 2023We present eCat, a novel end-to-end multispeaker model capable of: a) generating long-context speech with expressive and contextually appropriate prosody, and b) performing fine-grained prosody transfer between any pair of seen speakers. eCat is trained using a two-stage training approach. In Stage I, the model learns speaker-independent word-level prosody representations in an end-to-end fashion from speech. In Stage II, we learn to predict the prosody representations using the contextual information available in text. We compare eCat to CopyCat2, a model capable of both fine-grained prosody transfer (FPT) and multi-speaker TTS. We show that eCat statistically significantly reduces the gap in naturalness between CopyCat2 and human recordings by an average of 46.7% across 2 languages, 3 locales, and 7 speakers, along with better target-speaker similarity in FPT. We also compare eCat to VITS, and show a statistically significant preference.
GiBERT: Introducing Linguistic Knowledge into BERT through a Lightweight Gated Injection Method
Oct 23, 2020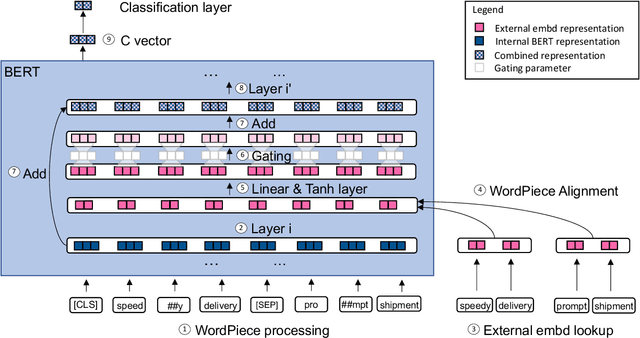
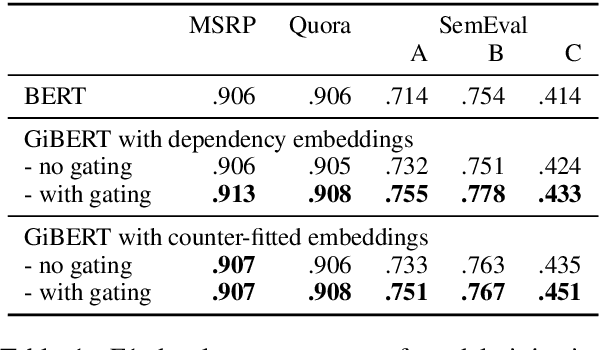
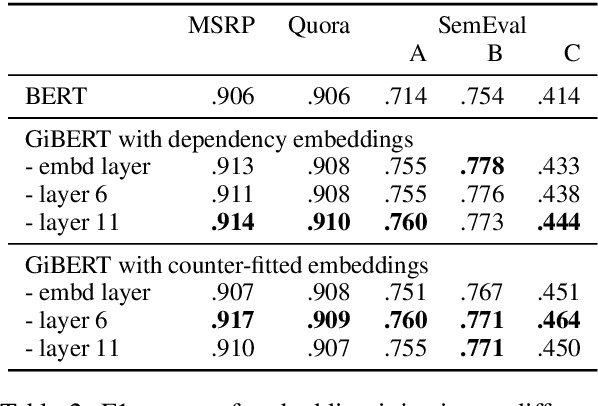
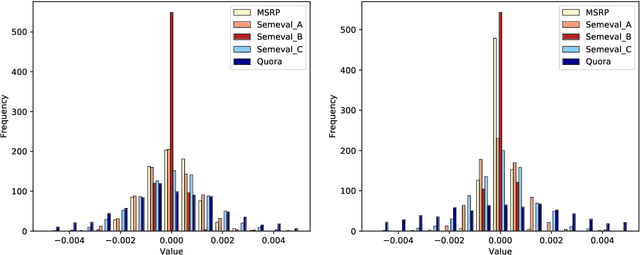
Large pre-trained language models such as BERT have been the driving force behind recent improvements across many NLP tasks. However, BERT is only trained to predict missing words - either behind masks or in the next sentence - and has no knowledge of lexical, syntactic or semantic information beyond what it picks up through unsupervised pre-training. We propose a novel method to explicitly inject linguistic knowledge in the form of word embeddings into any layer of a pre-trained BERT. Our performance improvements on multiple semantic similarity datasets when injecting dependency-based and counter-fitted embeddings indicate that such information is beneficial and currently missing from the original model. Our qualitative analysis shows that counter-fitted embedding injection particularly helps with cases involving synonym pairs.
Better Early than Late: Fusing Topics with Word Embeddings for Neural Question Paraphrase Identification
Jul 22, 2020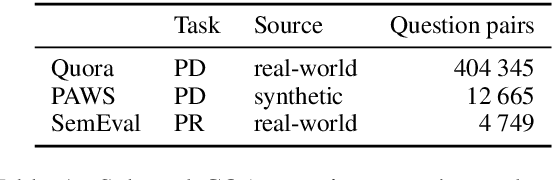
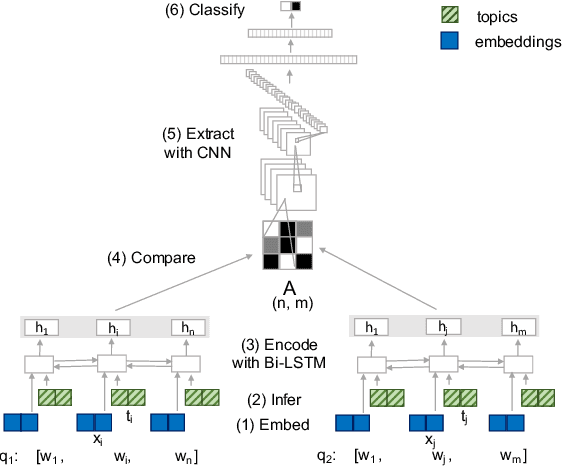

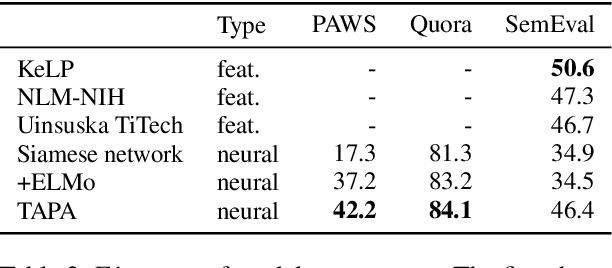
Question paraphrase identification is a key task in Community Question Answering (CQA) to determine if an incoming question has been previously asked. Many current models use word embeddings to identify duplicate questions, but the use of topic models in feature-engineered systems suggests that they can be helpful for this task, too. We therefore propose two ways of merging topics with word embeddings (early vs. late fusion) in a new neural architecture for question paraphrase identification. Our results show that our system outperforms neural baselines on multiple CQA datasets, while an ablation study highlights the importance of topics and especially early topic-embedding fusion in our architecture.