 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacking Motion Planners Using Adversarial Perception Errors
Nov 21, 2023



Autonomous driving (AD) systems are often built and tested in a modular fashion, where the performance of different modules is measured using task-specific metrics. These metrics should be chosen so as to capture the downstream impact of each module and the performance of the system as a whole. For example, high perception quality should enable prediction and planning to be performed safely. Even though this is true in general, we show here that it is possible to construct planner inputs that score very highly on various perception quality metrics but still lead to planning failures. In an analogy to adversarial attacks on image classifiers, we call such inputs \textbf{adversarial perception errors} and show they can be systematically constructed using a simple boundary-attack algorithm. We demonstrate the effectiveness of this algorithm by finding attacks for two different black-box planners in several urban and highway driving scenarios using the CARLA simulator. Finally, we analyse the properties of these attacks and show that they are isolated in the input space of the planner, and discuss their implications for AD system deployment and testing.
Attacking deep networks with surrogate-based adversarial black-box methods is easy
Mar 16, 2022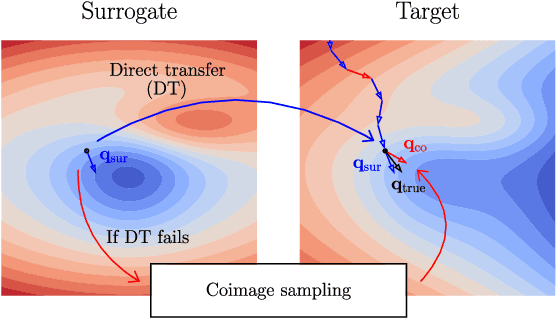
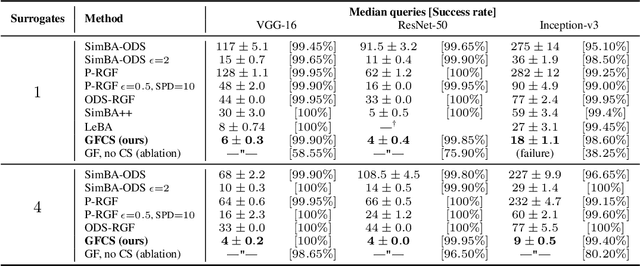
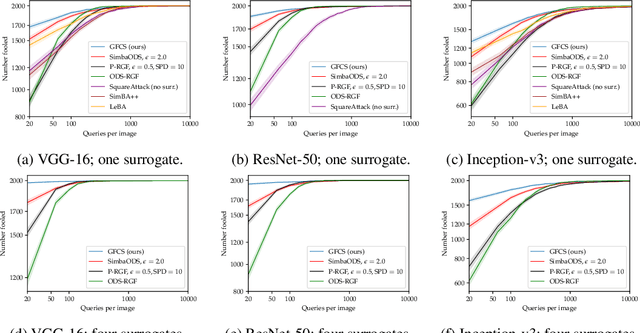
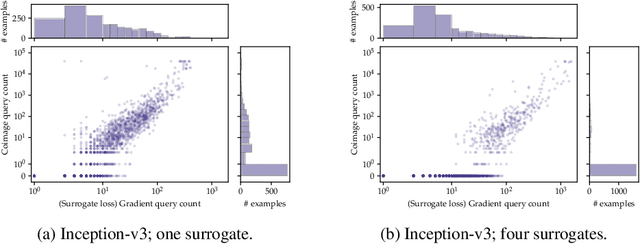
A recent line of work on black-box adversarial attacks has revived the use of transfer from surrogate models by integrating it into query-based search. However, we find that existing approaches of this type underperform their potential, and can be overly complicated besides. Here, we provide a short and simple algorithm which achieves state-of-the-art results through a search which uses the surrogate network's class-score gradients, with no need for other priors or heuristics. The guiding assumption of the algorithm is that the studied networks are in a fundamental sense learning similar functions, and that a transfer attack from one to the other should thus be fairly "easy". This assumption is validated by the extremely low query counts and failure rates achieved: e.g. an untargeted attack on a VGG-16 ImageNet network using a ResNet-152 as the surrogate yields a median query count of 6 at a success rate of 99.9%. Code is available at https://github.com/fiveai/GFCS.
Making Better Mistakes: Leveraging Class Hierarchies with Deep Networks
Dec 19, 2019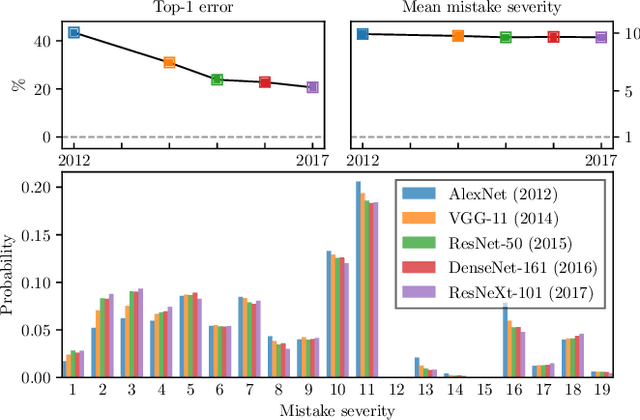
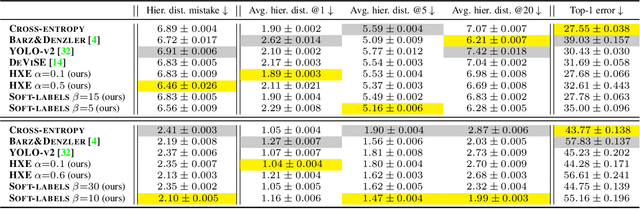
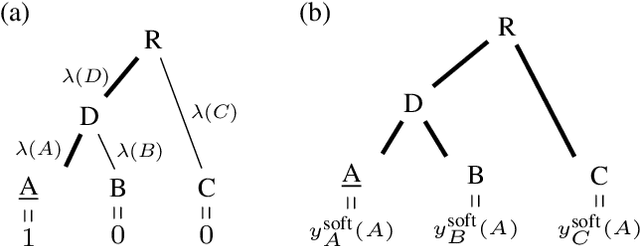
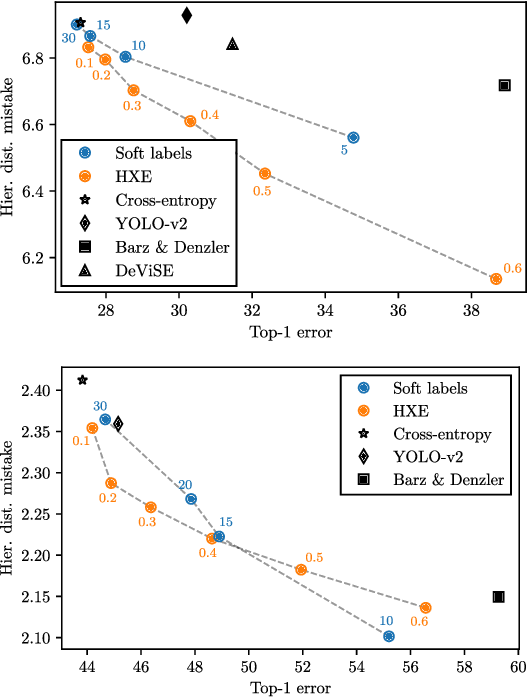
Deep neural networks have improved image classification dramatically over the past decade, but have done so by focusing on performance measures that treat all classes other than the ground truth as equally wrong. This has led to a situation in which mistakes are less likely to be made than before, but are equally likely to be absurd or catastrophic when they do occur. Past works have recognised and tried to address this issue of mistake severity, often by using graph distances in class hierarchies, but this has largely been neglected since the advent of the current deep learning era in computer vision. In this paper, we aim to renew interest in this problem by reviewing past approaches and proposing two simple modifications of the cross-entropy loss which outperform the prior art under several metrics on two large datasets with complex class hierarchies: tieredImageNet and iNaturalist19.
Real-Time RGB-D Camera Pose Estimation in Novel Scenes using a Relocalisation Cascade
Oct 29, 2018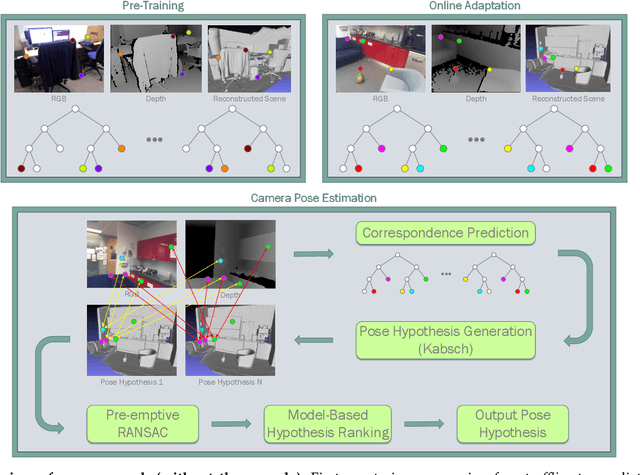
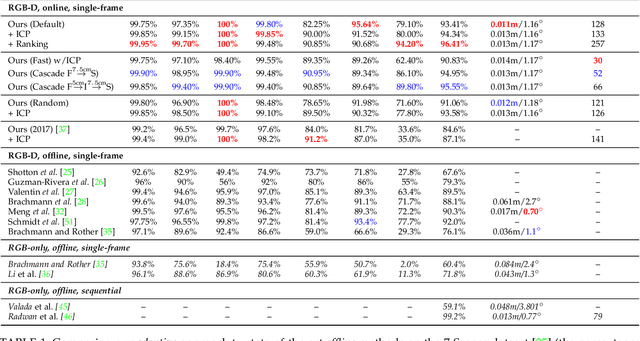

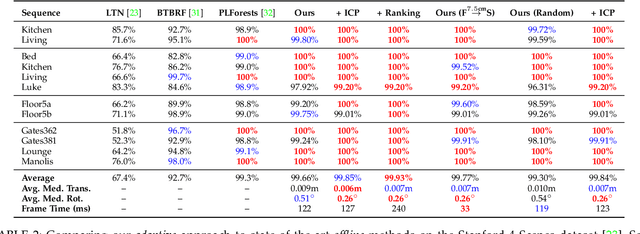
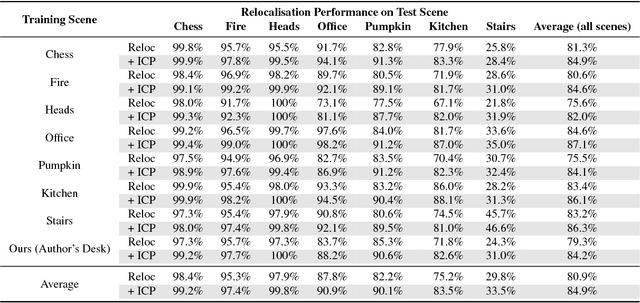
Camera pose estimation is an important problem in computer vision. Common techniques either match the current image against keyframes with known poses, directly regress the pose, or establish correspondences between keypoints in the image and points in the scene to estimate the pose. In recent years, regression forests have become a popular alternative to establish such correspondences. They achieve accurate results, but have traditionally needed to be trained offline on the target scene, preventing relocalisation in new environments. Recently, we showed how to circumvent this limitation by adapting a pre-trained forest to a new scene on the fly. The adapted forests achieved relocalisation performance that was on par with that of offline forests, and our approach was able to estimate the camera pose in close to real time. In this paper, we present an extension of this work that achieves significantly better relocalisation performance whilst running fully in real time. To achieve this, we make several changes to the original approach: (i) instead of accepting the camera pose hypothesis without question, we make it possible to score the final few hypotheses using a geometric approach and select the most promising; (ii) we chain several instantiations of our relocaliser together in a cascade, allowing us to try faster but less accurate relocalisation first, only falling back to slower, more accurate relocalisation as necessary; and (iii) we tune the parameters of our cascade to achieve effective overall performance. These changes allow us to significantly improve upon the performance our original state-of-the-art method was able to achieve on the well-known 7-Scenes and Stanford 4 Scenes benchmarks. As additional contributions, we present a way of visualising the internal behaviour of our forests and show how to entirely circumvent the need to pre-train a forest on a generic scene.
With Friends Like These, Who Needs Adversaries?
Jul 23, 2018

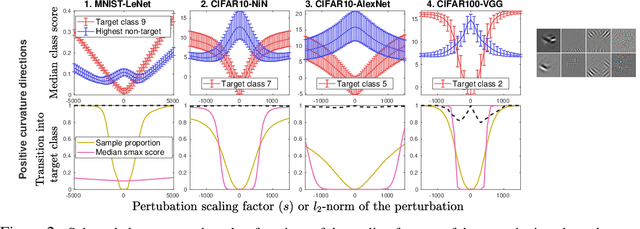
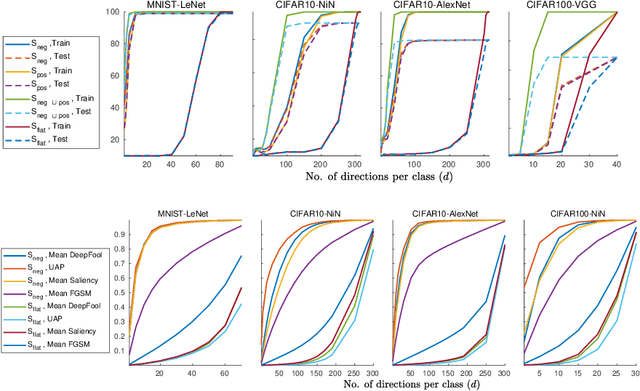
The vulnerability of deep image classification networks to adversarial attack is now well known, but less well understood. Via a novel experimental analysis, we illustrate some facts about deep convolutional networks (DCNs) that shed new light on their behaviour and its connection to the problem of adversaries, with two key results. The first is a straightforward explanation of the existence of universal adversarial perturbations and their association with specific class identities, obtained by analysing the properties of nets' logit responses as functions of 1D movements along specific image-space directions. The second is the clear demonstration of the tight coupling between classification performance and vulnerability to adversarial attack within the spaces spanned by these directions. Prior work has noted the importance of low-dimensional subspaces in adversarial vulnerability: we illustrate that this likewise represents the nets' notion of saliency. In all, we provide a digestible perspective from which to understand previously reported results which have appeared disjoint or contradictory, with implications for efforts to construct neural nets that are both accurate and robust to adversarial attack.
Learn To Pay Attention
Apr 26, 2018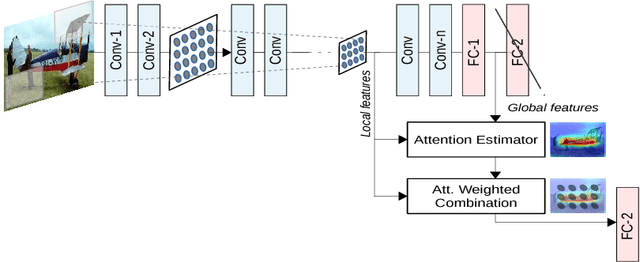
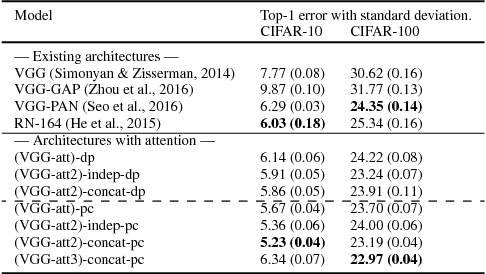
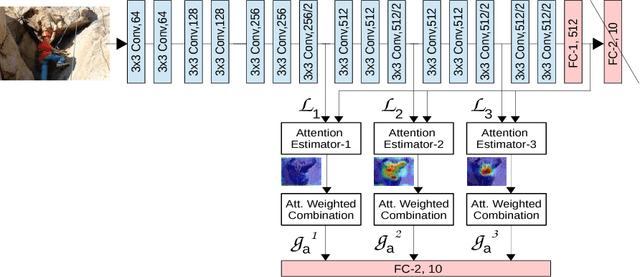
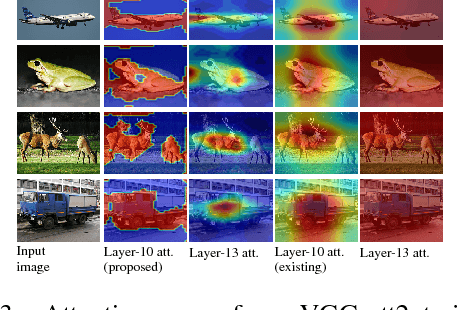
We propose an end-to-end-trainable attention module for convolutional neural network (CNN) architectures built for image classification. The module takes as input the 2D feature vector maps which form the intermediate representations of the input image at different stages in the CNN pipeline, and outputs a 2D matrix of scores for each map. Standard CNN architectures are modified through the incorporation of this module, and trained under the constraint that a convex combination of the intermediate 2D feature vectors, as parameterised by the score matrices, must \textit{alone} be used for classification. Incentivised to amplify the relevant and suppress the irrelevant or misleading, the scores thus assume the role of attention values. Our experimental observations provide clear evidence to this effect: the learned attention maps neatly highlight the regions of interest while suppressing background clutter. Consequently, the proposed function is able to bootstrap standard CNN architectures for the task of image classification, demonstrating superior generalisation over 6 unseen benchmark datasets. When binarised, our attention maps outperform other CNN-based attention maps, traditional saliency maps, and top object proposals for weakly supervised segmentation as demonstrated on the Object Discovery dataset. We also demonstrate improved robustness against the fast gradient sign method of adversarial attack.
On-the-Fly Adaptation of Regression Forests for Online Camera Relocalisation
Jun 26, 2017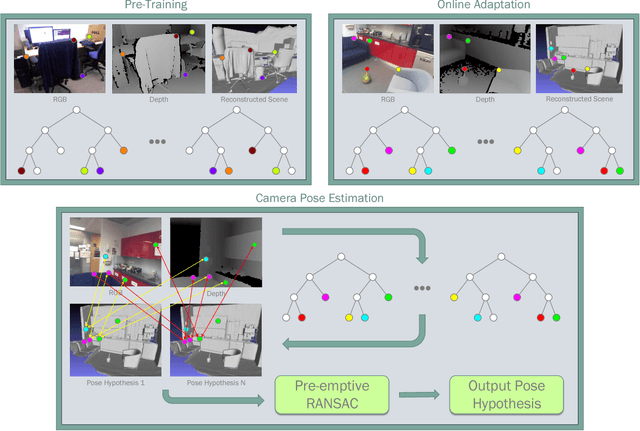


Camera relocalisation is an important problem in computer vision, with applications in simultaneous localisation and mapping, virtual/augmented reality and navigation. Common techniques either match the current image against keyframes with known poses coming from a tracker, or establish 2D-to-3D correspondences between keypoints in the current image and points in the scene in order to estimate the camera pose. Recently, regression forests have become a popular alternative to establish such correspondences. They achieve accurate results, but must be trained offline on the target scene, preventing relocalisation in new environments. In this paper, we show how to circumvent this limitation by adapting a pre-trained forest to a new scene on the fly. Our adapted forests achieve relocalisation performance that is on par with that of offline forests, and our approach runs in under 150ms, making it desirable for real-time systems that require online relocalisation.