 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Flamingo: a Visual Language Model for Few-Shot Learning
Apr 29, 2022
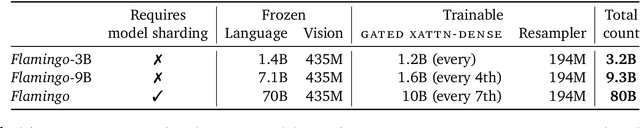
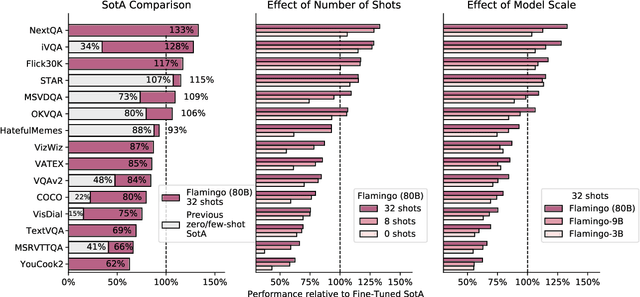
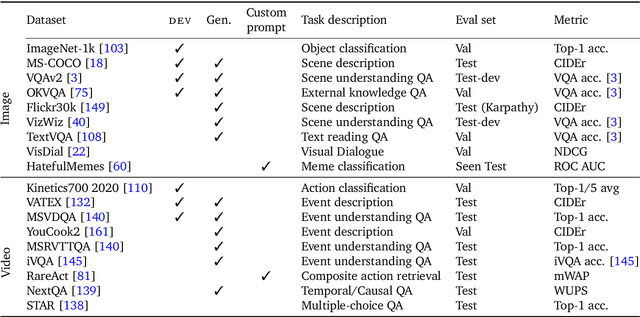
Building models that can be rapidly adapted to numerous tasks using only a handful of annotated examples is an open challenge for multimodal machine learning research. We introduce Flamingo, a family of Visual Language Models (VLM) with this ability. Flamingo models include key architectural innovations to: (i) bridge powerful pretrained vision-only and language-only models, (ii) handle sequences of arbitrarily interleaved visual and textual data, and (iii) seamlessly ingest images or videos as inputs. Thanks to their flexibility, Flamingo models can be trained on large-scale multimodal web corpora containing arbitrarily interleaved text and images, which is key to endow them with in-context few-shot learning capabilities. We perform a thorough evaluation of the proposed Flamingo models, exploring and measuring their ability to rapidly adapt to a variety of image and video understanding benchmarks. These include open-ended tasks such as visual question-answering, where the model is prompted with a question which it has to answer, captioning tasks, which evaluate the ability to describe a scene or an event, and close-ended tasks such as multiple choice visual question-answering. For tasks lying anywhere on this spectrum, we demonstrate that a single Flamingo model can achieve a new state of the art for few-shot learning, simply by prompting the model with task-specific examples. On many of these benchmarks, Flamingo actually surpasses the performance of models that are fine-tuned on thousands of times more task-specific data.
A Step Towards Efficient Evaluation of Complex Perception Tasks in Simulation
Sep 28, 2021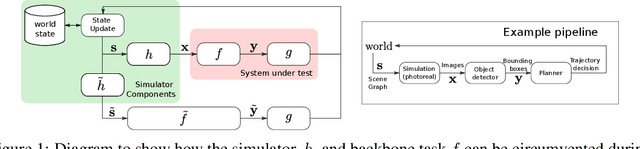
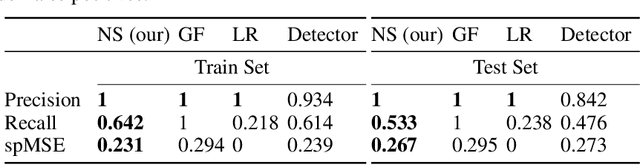
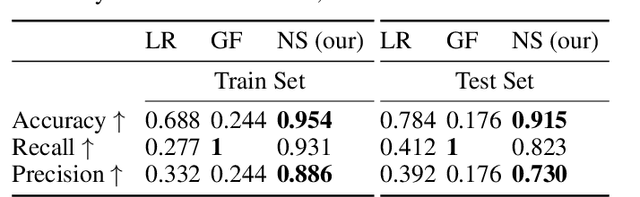
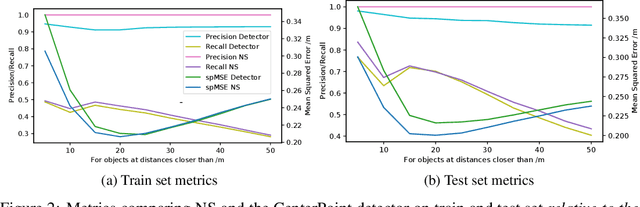
There has been increasing interest in characterising the error behaviour of systems which contain deep learning models before deploying them into any safety-critical scenario. However, characterising such behaviour usually requires large-scale testing of the model that can be extremely computationally expensive for complex real-world tasks. For example, tasks involving compute intensive object detectors as one of their components. In this work, we propose an approach that enables efficient large-scale testing using simplified low-fidelity simulators and without the computational cost of executing expensive deep learning models. Our approach relies on designing an efficient surrogate model corresponding to the compute intensive components of the task under test. We demonstrate the efficacy of our methodology by evaluating the performance of an autonomous driving task in the Carla simulator with reduced computational expense by training efficient surrogate models for PIXOR and CenterPoint LiDAR detectors, whilst demonstrating that the accuracy of the simulation is maintained.
Making Better Mistakes: Leveraging Class Hierarchies with Deep Networks
Dec 19, 2019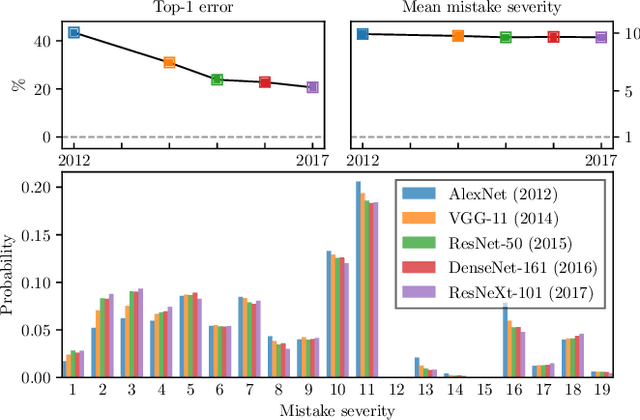
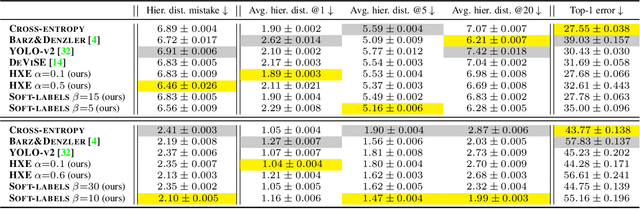
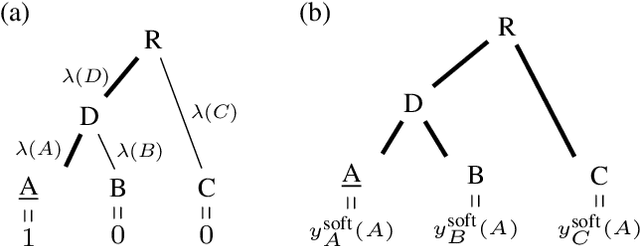
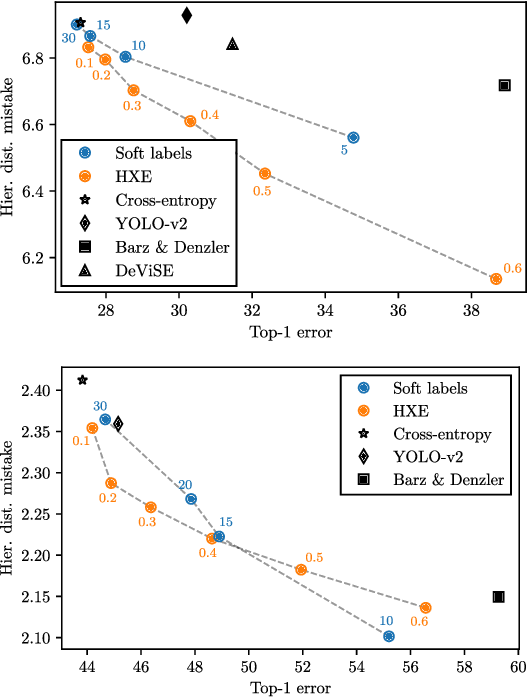
Deep neural networks have improved image classification dramatically over the past decade, but have done so by focusing on performance measures that treat all classes other than the ground truth as equally wrong. This has led to a situation in which mistakes are less likely to be made than before, but are equally likely to be absurd or catastrophic when they do occur. Past works have recognised and tried to address this issue of mistake severity, often by using graph distances in class hierarchies, but this has largely been neglected since the advent of the current deep learning era in computer vision. In this paper, we aim to renew interest in this problem by reviewing past approaches and proposing two simple modifications of the cross-entropy loss which outperform the prior art under several metrics on two large datasets with complex class hierarchies: tieredImageNet and iNaturalist19.
Imagining the Unseen: Learning a Distribution over Incomplete Images with Dense Latent Trees
Aug 14, 2018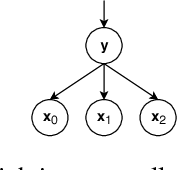
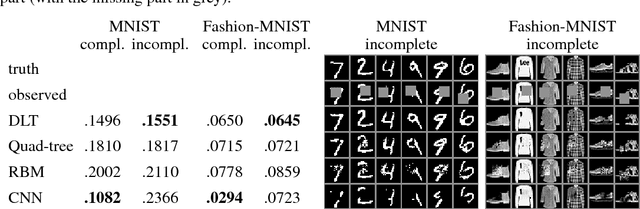
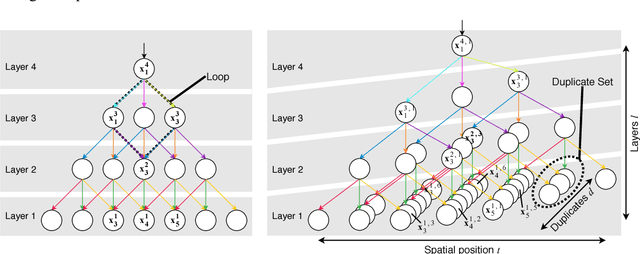

Images are composed as a hierarchy of object parts. We use this insight to create a generative graphical model that defines a hierarchical distribution over image parts. Typically, this leads to intractable inference due to loops in the graph. We propose an alternative model structure, the Dense Latent Tree (DLT), which avoids loops and allows for efficient exact inference, while maintaining a dense connectivity between parts of the hierarchy. The usefulness of DLTs is shown for the example task of image completion on partially observed MNIST and Fashion-MNIST data. We verify having successfully learned a hierarchical model of images by visualising its latent states.
A Dataset for Lane Instance Segmentation in Urban Environments
Aug 02, 2018
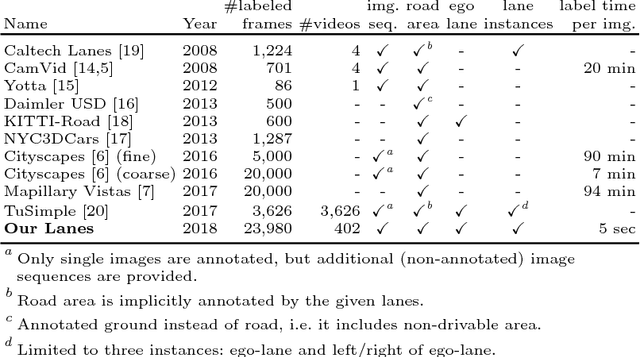
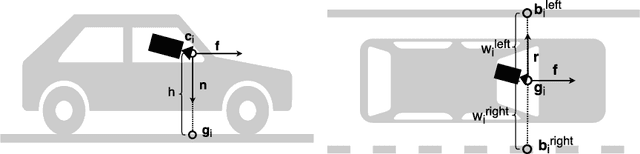
Autonomous vehicles require knowledge of the surrounding road layout, which can be predicted by state-of-the-art CNNs. This work addresses the current lack of data for determining lane instances, which are needed for various driving manoeuvres. The main issue is the time-consuming manual labelling process, typically applied per image. We notice that driving the car is itself a form of annotation. Therefore, we propose a semi-automated method that allows for efficient labelling of image sequences by utilising an estimated road plane in 3D based on where the car has driven and projecting labels from this plane into all images of the sequence. The average labelling time per image is reduced to 5 seconds and only an inexpensive dash-cam is required for data capture. We are releasing a dataset of 24,000 images and additionally show experimental semantic segmentation and instance segmentation results.