 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Lane Instance Segmentation in Urban Environments
Paper and Code
Aug 02, 2018
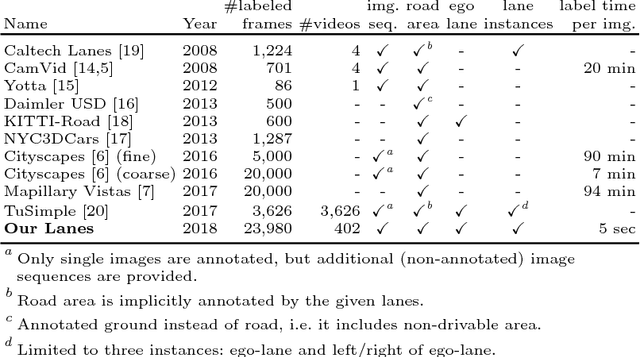
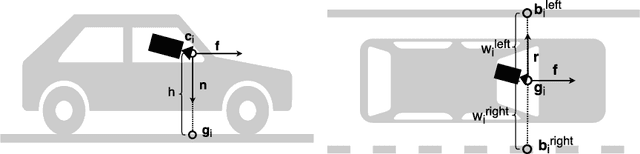
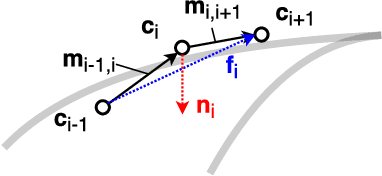
Autonomous vehicles require knowledge of the surrounding road layout, which can be predicted by state-of-the-art CNNs. This work addresses the current lack of data for determining lane instances, which are needed for various driving manoeuvres. The main issue is the time-consuming manual labelling process, typically applied per image. We notice that driving the car is itself a form of annotation. Therefore, we propose a semi-automated method that allows for efficient labelling of image sequences by utilising an estimated road plane in 3D based on where the car has driven and projecting labels from this plane into all images of the sequence. The average labelling time per image is reduced to 5 seconds and only an inexpensive dash-cam is required for data capture. We are releasing a dataset of 24,000 images and additionally show experimental semantic segmentation and instance segmentation results.