 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Step Towards Efficient Evaluation of Complex Perception Tasks in Simulation
Sep 28, 2021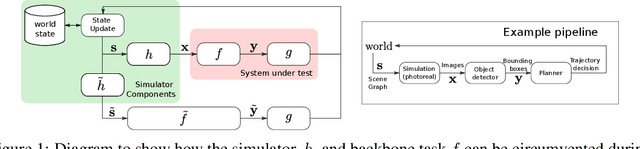
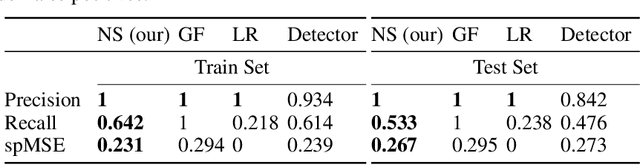
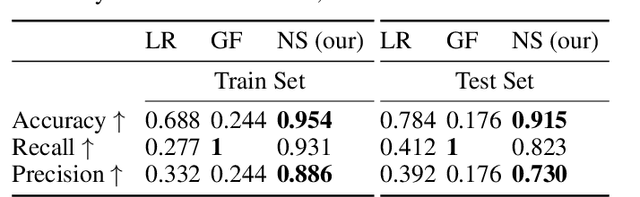
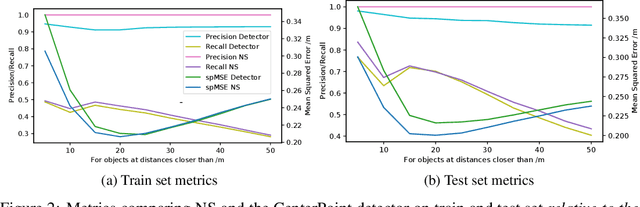
There has been increasing interest in characterising the error behaviour of systems which contain deep learning models before deploying them into any safety-critical scenario. However, characterising such behaviour usually requires large-scale testing of the model that can be extremely computationally expensive for complex real-world tasks. For example, tasks involving compute intensive object detectors as one of their components. In this work, we propose an approach that enables efficient large-scale testing using simplified low-fidelity simulators and without the computational cost of executing expensive deep learning models. Our approach relies on designing an efficient surrogate model corresponding to the compute intensive components of the task under test. We demonstrate the efficacy of our methodology by evaluating the performance of an autonomous driving task in the Carla simulator with reduced computational expense by training efficient surrogate models for PIXOR and CenterPoint LiDAR detectors, whilst demonstrating that the accuracy of the simulation is maintained.
Bottom-Up Top-Down Cues for Weakly-Supervised Semantic Segmentation
Apr 09, 2017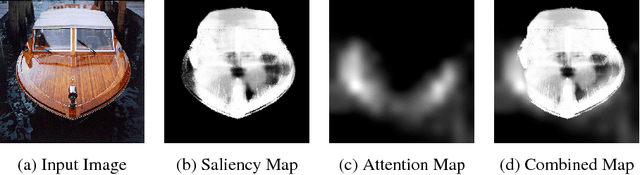
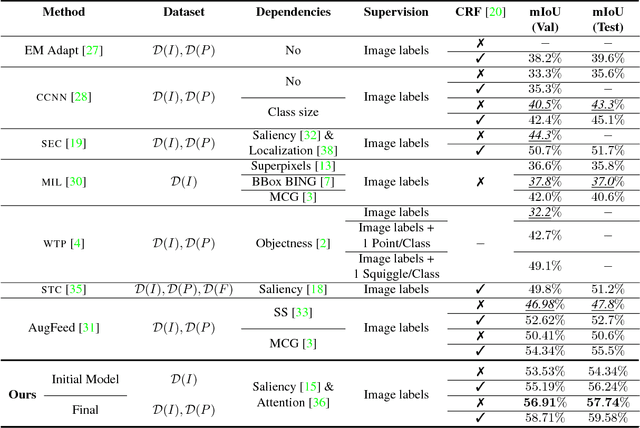

We consider the task of learning a classifier for semantic segmentation using weak supervision in the form of image labels which specify the object classes present in the image. Our method uses deep convolutional neural networks (CNNs) and adopts an Expectation-Maximization (EM) based approach. We focus on the following three aspects of EM: (i) initialization; (ii) latent posterior estimation (E-step) and (iii) the parameter update (M-step). We show that saliency and attention maps, our bottom-up and top-down cues respectively, of simple images provide very good cues to learn an initialization for the EM-based algorithm. Intuitively, we show that before trying to learn to segment complex images, it is much easier and highly effective to first learn to segment a set of simple images and then move towards the complex ones. Next, in order to update the parameters, we propose minimizing the combination of the standard softmax loss and the KL divergence between the true latent posterior and the likelihood given by the CNN. We argue that this combination is more robust to wrong predictions made by the expectation step of the EM method. We support this argument with empirical and visual results. Extensive experiments and discussions show that: (i) our method is very simple and intuitive; (ii) requires only image-level labels; and (iii) consistently outperforms other weakly-supervised state-of-the-art methods with a very high margin on the PASCAL VOC 2012 dataset.