 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Better Mistakes: Leveraging Class Hierarchies with Deep Networks
Paper and Code
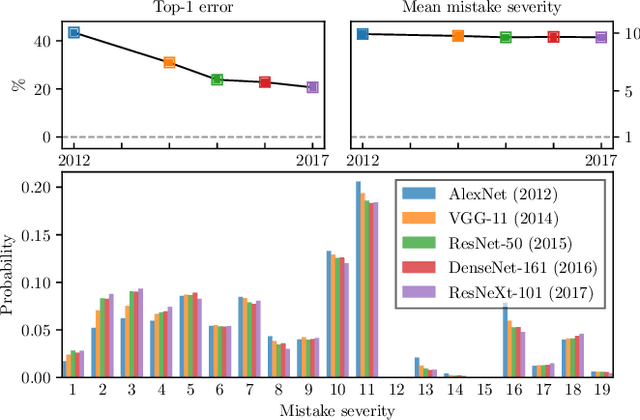
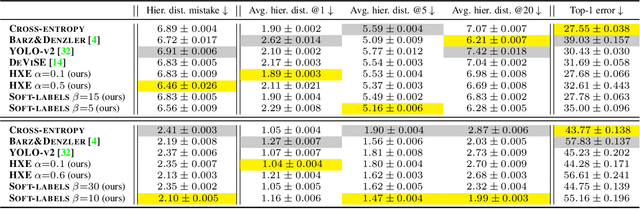
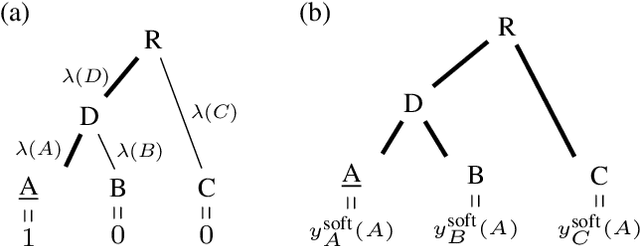
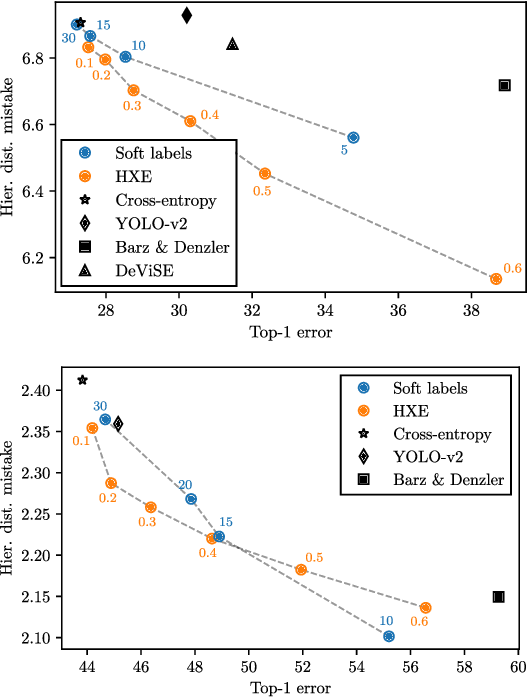
Deep neural networks have improved image classification dramatically over the past decade, but have done so by focusing on performance measures that treat all classes other than the ground truth as equally wrong. This has led to a situation in which mistakes are less likely to be made than before, but are equally likely to be absurd or catastrophic when they do occur. Past works have recognised and tried to address this issue of mistake severity, often by using graph distances in class hierarchies, but this has largely been neglected since the advent of the current deep learning era in computer vision. In this paper, we aim to renew interest in this problem by reviewing past approaches and proposing two simple modifications of the cross-entropy loss which outperform the prior art under several metrics on two large datasets with complex class hierarchies: tieredImageNet and iNaturalist19.