 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticPaint: A Framework for the Interactive Segmentation of 3D Scenes
Oct 13, 2015
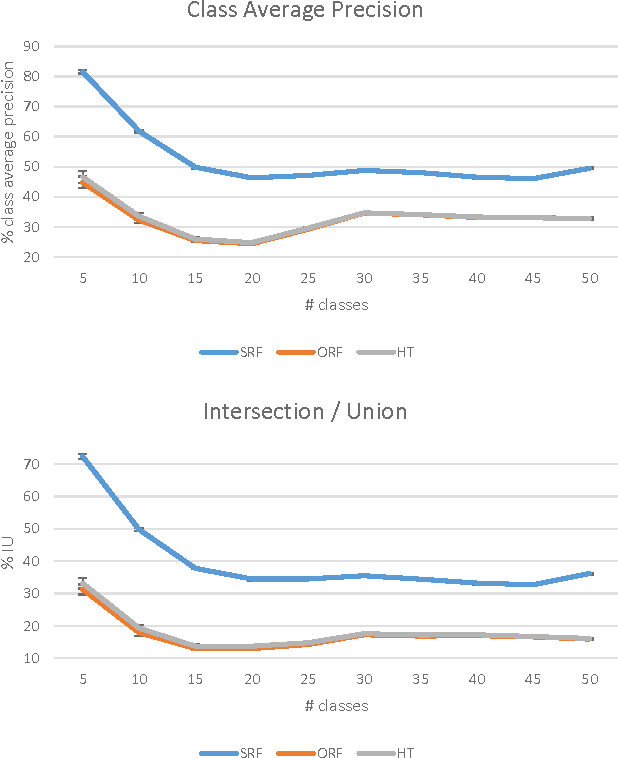

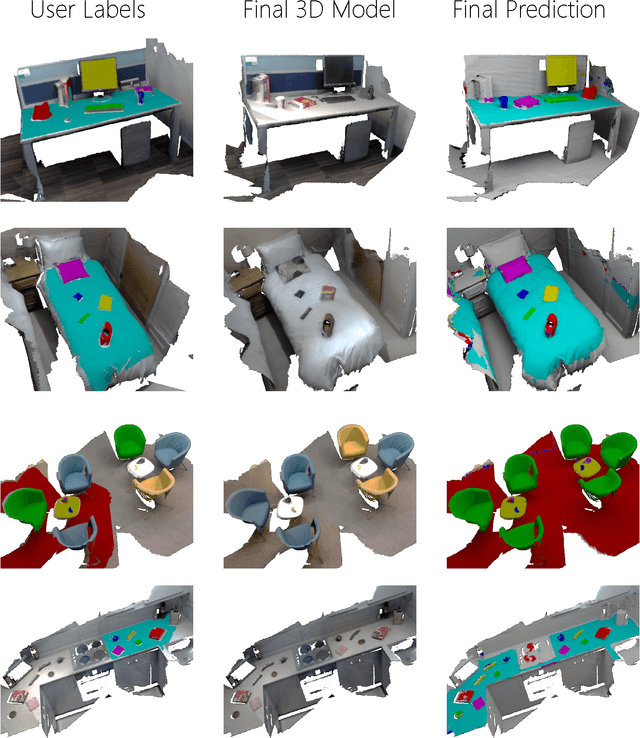
We present an open-source, real-time implementation of SemanticPaint, a system for geometric reconstruction, object-class segmentation and learning of 3D scenes. Using our system, a user can walk into a room wearing a depth camera and a virtual reality headset, and both densely reconstruct the 3D scene and interactively segment the environment into object classes such as 'chair', 'floor' and 'table'. The user interacts physically with the real-world scene, touching objects and using voice commands to assign them appropriate labels. These user-generated labels are leveraged by an online random forest-based machine learning algorithm, which is used to predict labels for previously unseen parts of the scene. The entire pipeline runs in real time, and the user stays 'in the loop' throughout the process, receiving immediate feedback about the progress of the labelling and interacting with the scene as necessary to refine the predicted segmentation.
A Framework for the Volumetric Integration of Depth Images
Oct 23, 2014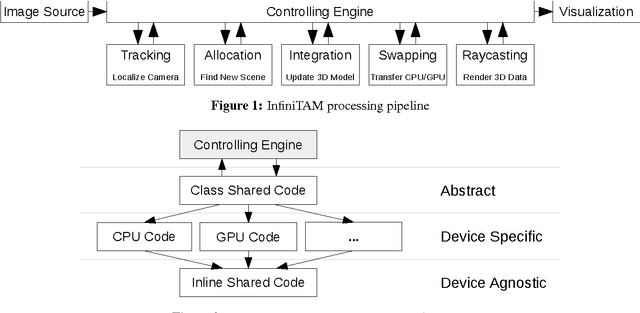
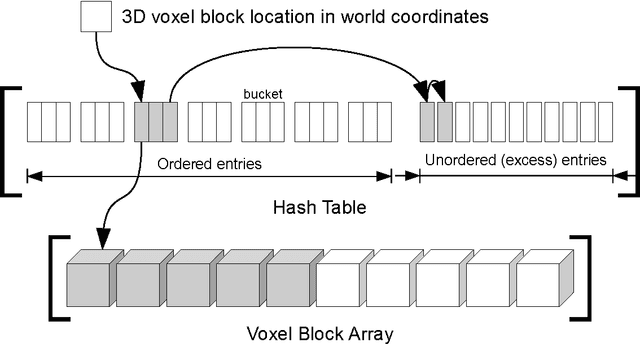
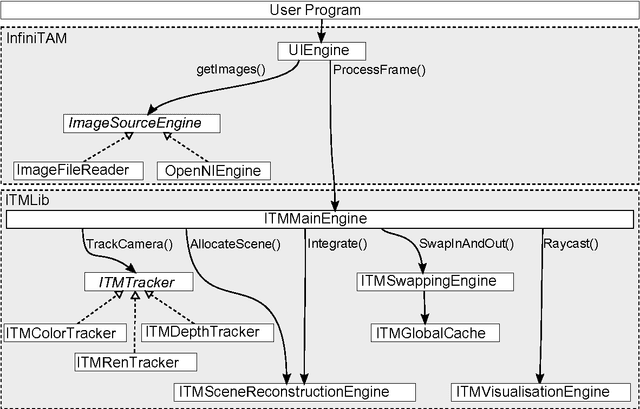
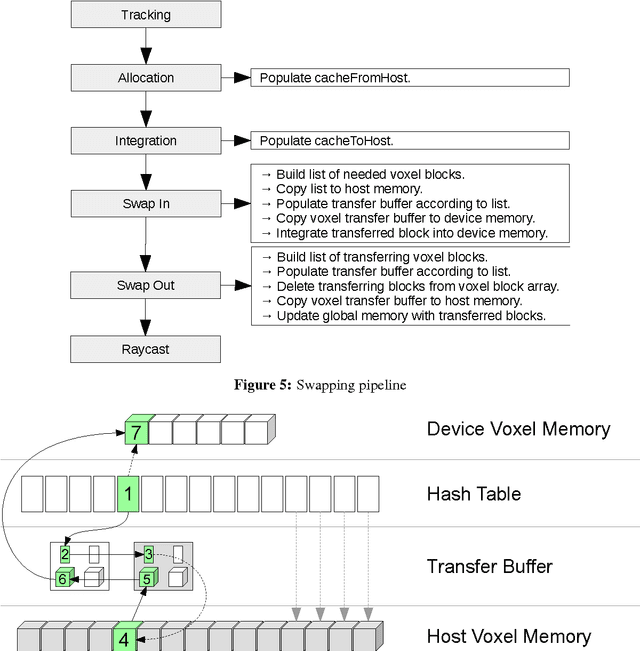
Volumetric models have become a popular representation for 3D scenes in recent years. One of the breakthroughs leading to their popularity was KinectFusion, where the focus is on 3D reconstruction using RGB-D sensors. However, monocular SLAM has since also been tackled with very similar approaches. Representing the reconstruction volumetrically as a truncated signed distance function leads to most of the simplicity and efficiency that can be achieved with GPU implementations of these systems. However, this representation is also memory-intensive and limits the applicability to small scale reconstructions. Several avenues have been explored for overcoming this limitation. With the aim of summarizing them and providing for a fast and flexible 3D reconstruction pipeline, we propose a new, unifying framework called InfiniTAM. The core idea is that individual steps like camera tracking, scene representation and integration of new data can easily be replaced and adapted to the needs of the user. Along with the framework we also provide a set of components for scalable reconstruction: two implementations of camera trackers, based on RGB data and on depth data, two representations of the 3D volumetric data, a dense volume and one based on hashes of subblocks, and an optional module for swapping subblocks in and out of the typically limited GPU memory.