 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Matching: An Application-oriented Benchmark
Aug 07, 2018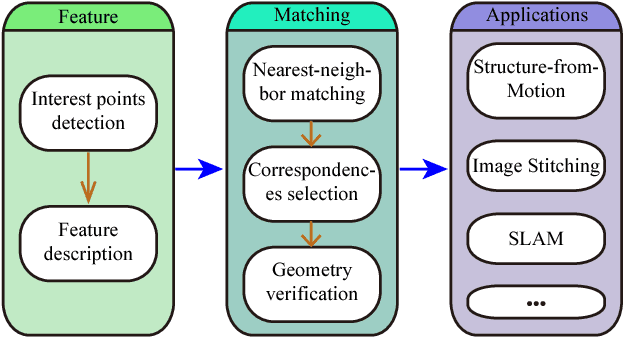
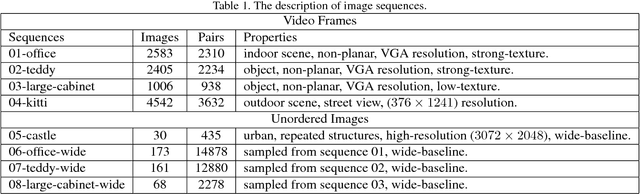

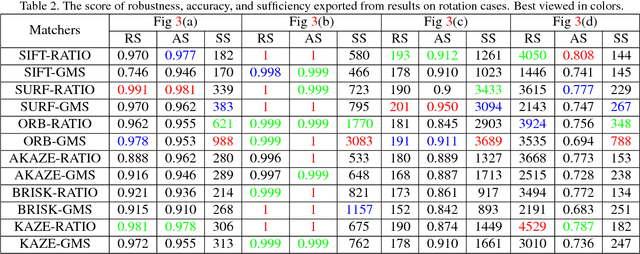
Image matching approaches have been widely used in computer vision applications in which the image-level matching performance of matchers is critical. However, it has not been well investigated by previous works which place more emphases on evaluating local features. To this end, we present a uniform benchmark with novel evaluation metrics and a large-scale dataset for evaluating the overall performance of image matching methods. The proposed metrics are application-oriented as they emphasize application requirements for matchers. The dataset contains two portions for benchmarking video frame matching and unordered image matching separately, where each portion consists of real-world image sequences and each sequence has a specific attribute. Subsequently, we carry out a comprehensive performance evaluation of different state-of-the-art methods and conduct in-depth analyses regarding various aspects such as application requirements, matching types, and data diversity. Moreover, we shed light on how to choose appropriate approaches for different applications based on empirical results and analyses. Conclusions in this benchmark can be used as general guidelines to design practical matching systems and also advocate potential future research directions in this field.
A Framework for the Volumetric Integration of Depth Images
Oct 23, 2014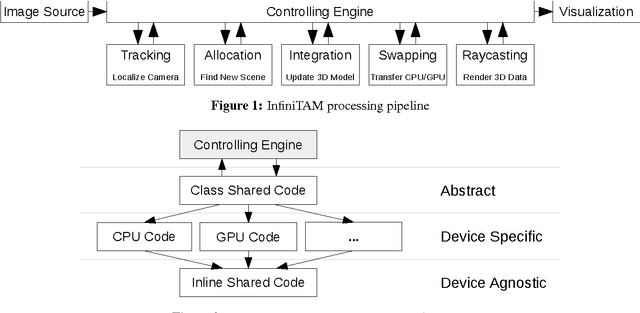
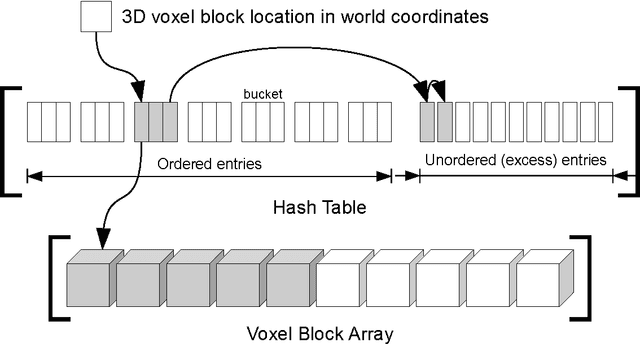
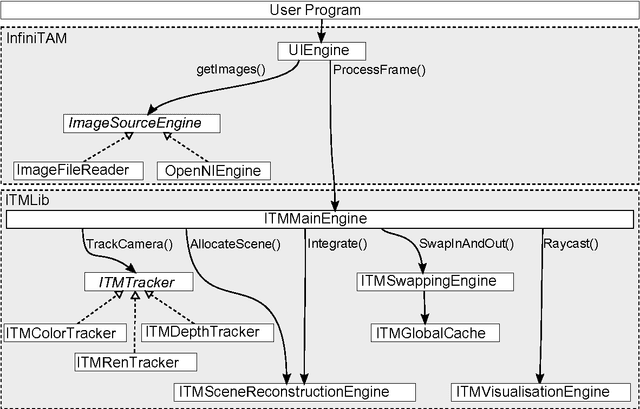
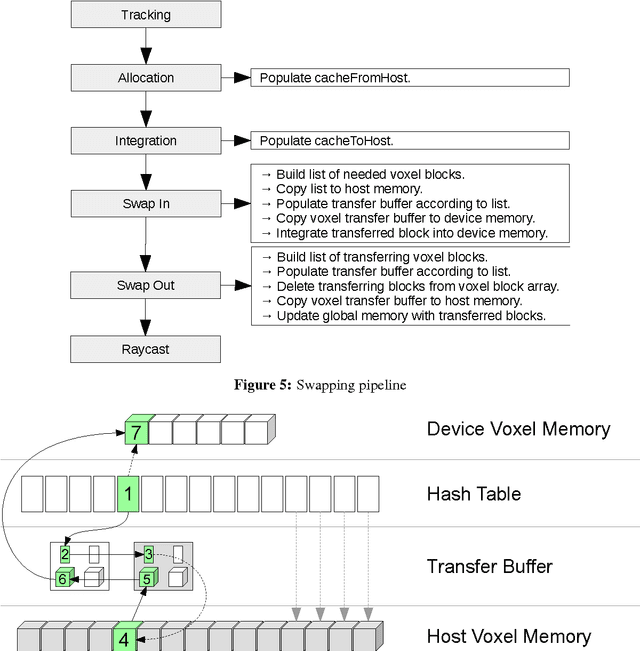
Volumetric models have become a popular representation for 3D scenes in recent years. One of the breakthroughs leading to their popularity was KinectFusion, where the focus is on 3D reconstruction using RGB-D sensors. However, monocular SLAM has since also been tackled with very similar approaches. Representing the reconstruction volumetrically as a truncated signed distance function leads to most of the simplicity and efficiency that can be achieved with GPU implementations of these systems. However, this representation is also memory-intensive and limits the applicability to small scale reconstructions. Several avenues have been explored for overcoming this limitation. With the aim of summarizing them and providing for a fast and flexible 3D reconstruction pipeline, we propose a new, unifying framework called InfiniTAM. The core idea is that individual steps like camera tracking, scene representation and integration of new data can easily be replaced and adapted to the needs of the user. Along with the framework we also provide a set of components for scalable reconstruction: two implementations of camera trackers, based on RGB data and on depth data, two representations of the 3D volumetric data, a dense volume and one based on hashes of subblocks, and an optional module for swapping subblocks in and out of the typically limited GPU memory.