 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin Catalog: A Large-Scale Photorealistic 3D Object Digital Twin Dataset
Apr 11, 2025



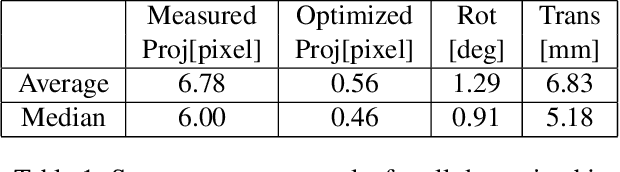
We introduce Digital Twin Catalog (DTC), a new large-scale photorealistic 3D object digital twin dataset. A digital twin of a 3D object is a highly detailed, virtually indistinguishable representation of a physical object, accurately capturing its shape, appearance, physical properties, and other attributes. Recent advances in neural-based 3D reconstruction and inverse rendering have significantly improved the quality of 3D object reconstruction. Despite these advancements, there remains a lack of a large-scale, digital twin quality real-world dataset and benchmark that can quantitatively assess and compare the performance of different reconstruction methods, as well as improve reconstruction quality through training or fine-tuning. Moreover, to democratize 3D digital twin creation, it is essential to integrate creation techniques with next-generation egocentric computing platforms, such as AR glasses. Currently, there is no dataset available to evaluate 3D object reconstruction using egocentric captured images. To address these gaps, the DTC dataset features 2,000 scanned digital twin-quality 3D objects, along with image sequences captured under different lighting conditions using DSLR cameras and egocentric AR glasses. This dataset establishes the first comprehensive real-world evaluation benchmark for 3D digital twin creation tasks, offering a robust foundation for comparing and improving existing reconstruction methods. The DTC dataset is already released at https://www.projectaria.com/datasets/dtc/ and we will also make the baseline evaluations open-source.
Aria Digital Twin: A New Benchmark Dataset for Egocentric 3D Machine Perception
Jun 13, 2023
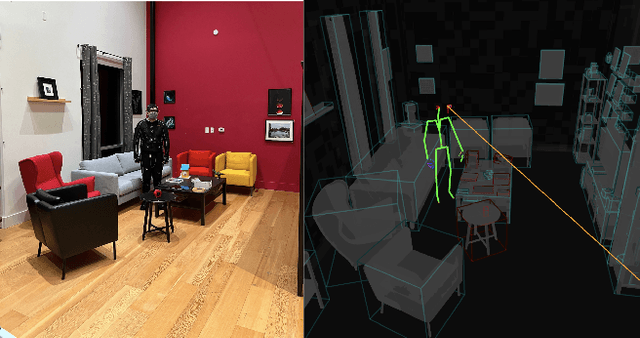
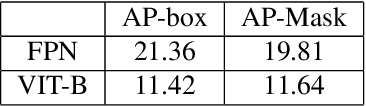
We introduce the Aria Digital Twin (ADT) - an egocentric dataset captured using Aria glasses with extensive object, environment, and human level ground truth. This ADT release contains 200 sequences of real-world activities conducted by Aria wearers in two real indoor scenes with 398 object instances (324 stationary and 74 dynamic). Each sequence consists of: a) raw data of two monochrome camera streams, one RGB camera stream, two IMU streams; b) complete sensor calibration; c) ground truth data including continuous 6-degree-of-freedom (6DoF) poses of the Aria devices, object 6DoF poses, 3D eye gaze vectors, 3D human poses, 2D image segmentations, image depth maps; and d) photo-realistic synthetic renderings. To the best of our knowledge, there is no existing egocentric dataset with a level of accuracy, photo-realism and comprehensiveness comparable to ADT. By contributing ADT to the research community, our mission is to set a new standard for evaluation in the egocentric machine perception domain, which includes very challenging research problems such as 3D object detection and tracking, scene reconstruction and understanding, sim-to-real learning, human pose prediction - while also inspiring new machine perception tasks for augmented reality (AR) applications. To kick start exploration of the ADT research use cases, we evaluated several existing state-of-the-art methods for object detection, segmentation and image translation tasks that demonstrate the usefulness of ADT as a benchmarking dataset.
SemanticPaint: A Framework for the Interactive Segmentation of 3D Scenes
Oct 13, 2015
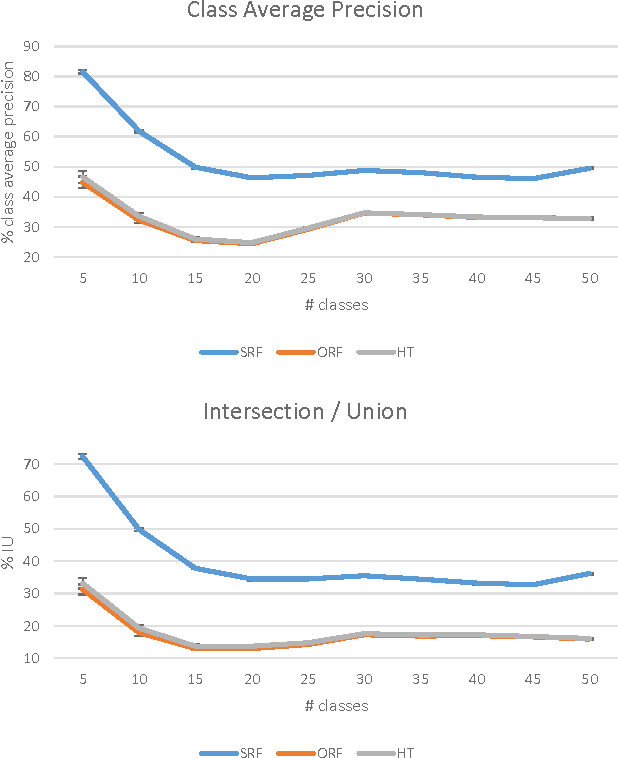

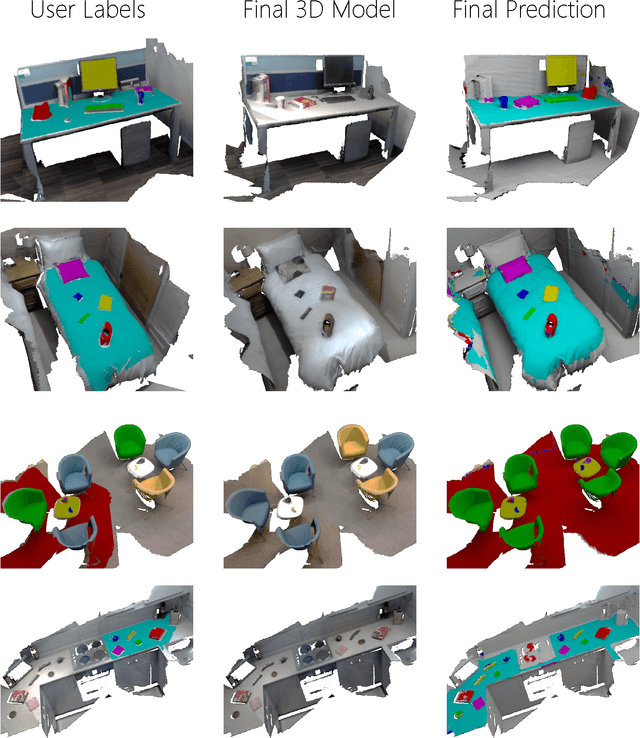
We present an open-source, real-time implementation of SemanticPaint, a system for geometric reconstruction, object-class segmentation and learning of 3D scenes. Using our system, a user can walk into a room wearing a depth camera and a virtual reality headset, and both densely reconstruct the 3D scene and interactively segment the environment into object classes such as 'chair', 'floor' and 'table'. The user interacts physically with the real-world scene, touching objects and using voice commands to assign them appropriate labels. These user-generated labels are leveraged by an online random forest-based machine learning algorithm, which is used to predict labels for previously unseen parts of the scene. The entire pipeline runs in real time, and the user stays 'in the loop' throughout the process, receiving immediate feedback about the progress of the labelling and interacting with the scene as necessary to refine the predicted segmentation.
gSLICr: SLIC superpixels at over 250Hz
Sep 14, 2015
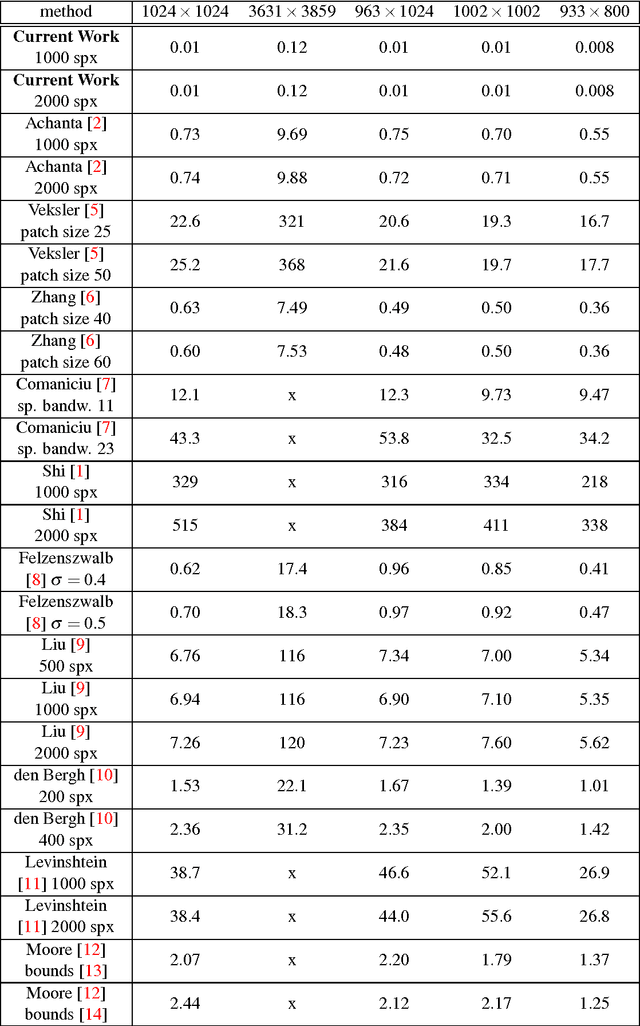
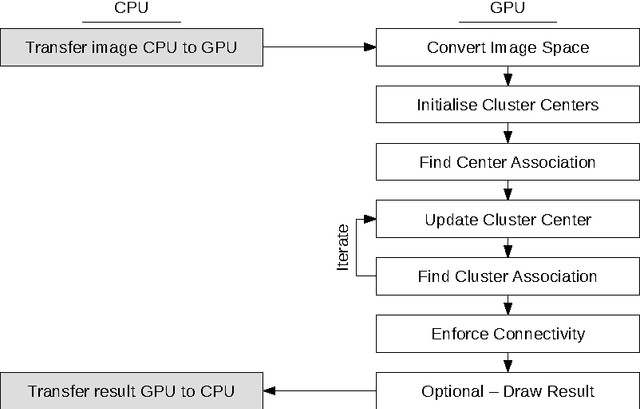
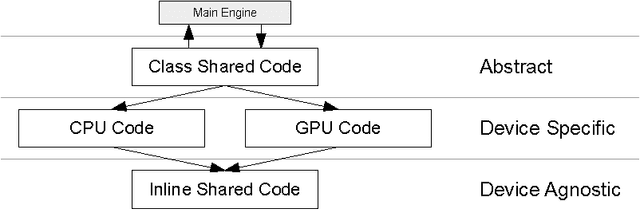
We introduce a parallel GPU implementation of the Simple Linear Iterative Clustering (SLIC) superpixel segmentation. Using a single graphic card, our implementation achieves speedups of up to $83\times$ from the standard sequential implementation. Our implementation is fully compatible with the standard sequential implementation and the software is now available online and is open source.
A Framework for the Volumetric Integration of Depth Images
Oct 23, 2014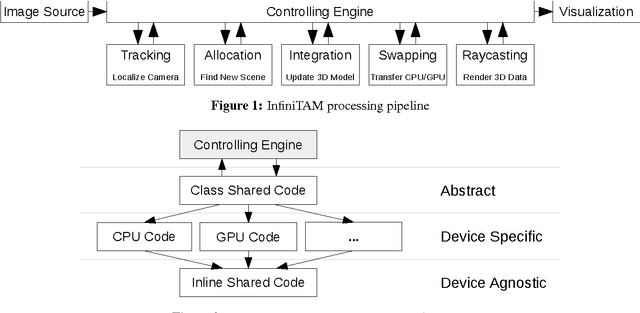
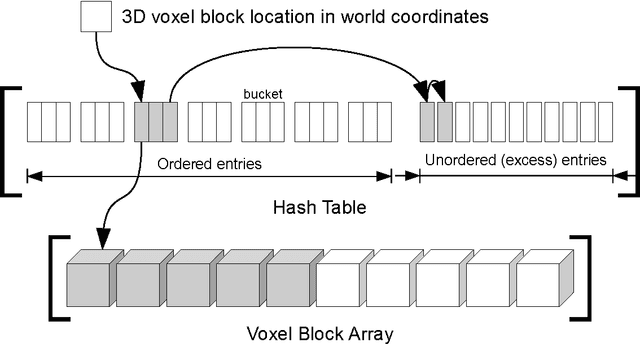
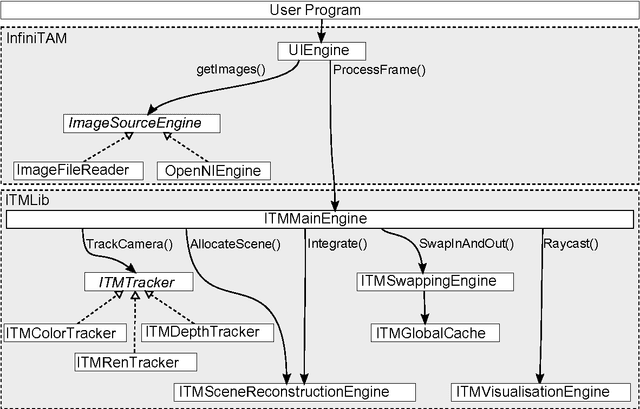
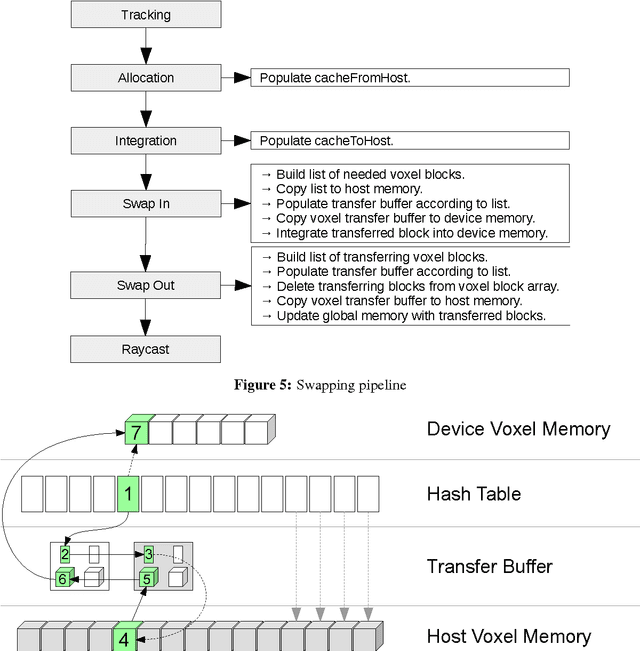
Volumetric models have become a popular representation for 3D scenes in recent years. One of the breakthroughs leading to their popularity was KinectFusion, where the focus is on 3D reconstruction using RGB-D sensors. However, monocular SLAM has since also been tackled with very similar approaches. Representing the reconstruction volumetrically as a truncated signed distance function leads to most of the simplicity and efficiency that can be achieved with GPU implementations of these systems. However, this representation is also memory-intensive and limits the applicability to small scale reconstructions. Several avenues have been explored for overcoming this limitation. With the aim of summarizing them and providing for a fast and flexible 3D reconstruction pipeline, we propose a new, unifying framework called InfiniTAM. The core idea is that individual steps like camera tracking, scene representation and integration of new data can easily be replaced and adapted to the needs of the user. Along with the framework we also provide a set of components for scalable reconstruction: two implementations of camera trackers, based on RGB data and on depth data, two representations of the 3D volumetric data, a dense volume and one based on hashes of subblocks, and an optional module for swapping subblocks in and out of the typically limited GPU memory.