 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Volumetric Reconstruction for Clothed Humans
Jul 25, 2023



We present a novel method for reconstructing clothed humans from a sparse set of, e.g., 1 to 6 RGB images. Despite impressive results from recent works employing deep implicit representation, we revisit the volumetric approach and demonstrate that better performance can be achieved with proper system design. The volumetric representation offers significant advantages in leveraging 3D spatial context through 3D convolutions, and the notorious quantization error is largely negligible with a reasonably large yet affordable volume resolution, e.g., 512. To handle memory and computation costs, we propose a sophisticated coarse-to-fine strategy with voxel culling and subspace sparse convolution. Our method starts with a discretized visual hull to compute a coarse shape and then focuses on a narrow band nearby the coarse shape for refinement. Once the shape is reconstructed, we adopt an image-based rendering approach, which computes the colors of surface points by blending input images with learned weights. Extensive experimental results show that our method significantly reduces the mean point-to-surface (P2S) precision of state-of-the-art methods by more than 50% to achieve approximately 2mm accuracy with a 512 volume resolution. Additionally, images rendered from our textured model achieve a higher peak signal-to-noise ratio (PSNR) compared to state-of-the-art methods.
NeuMap: Neural Coordinate Mapping by Auto-Transdecoder for Camera Localization
Nov 21, 2022



This paper presents an end-to-end neural mapping method for camera localization, encoding a whole scene into a grid of latent codes, with which a Transformer-based auto-decoder regresses 3D coordinates of query pixels. State-of-the-art camera localization methods require each scene to be stored as a 3D point cloud with per-point features, which takes several gigabytes of storage per scene. While compression is possible, the performance drops significantly at high compression rates. NeuMap achieves extremely high compression rates with minimal performance drop by using 1) learnable latent codes to store scene information and 2) a scene-agnostic Transformer-based auto-decoder to infer coordinates for a query pixel. The scene-agnostic network design also learns robust matching priors by training with large-scale data, and further allows us to just optimize the codes quickly for a new scene while fixing the network weights. Extensive evaluations with five benchmarks show that NeuMap outperforms all the other coordinate regression methods significantly and reaches similar performance as the feature matching methods while having a much smaller scene representation size. For example, NeuMap achieves 39.1% accuracy in Aachen night benchmark with only 6MB of data, while other compelling methods require 100MB or a few gigabytes and fail completely under high compression settings. The codes are available at https://github.com/Tangshitao/NeuMap.
A Neural Network for Detailed Human Depth Estimation from a Single Image
Oct 03, 2019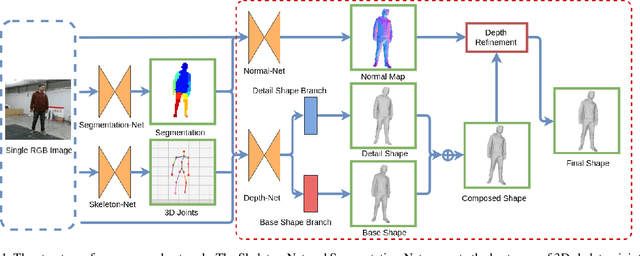
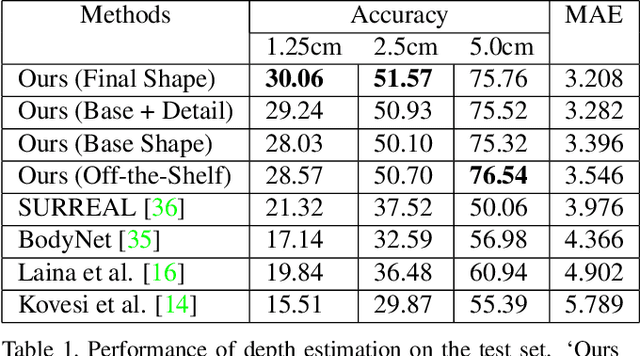
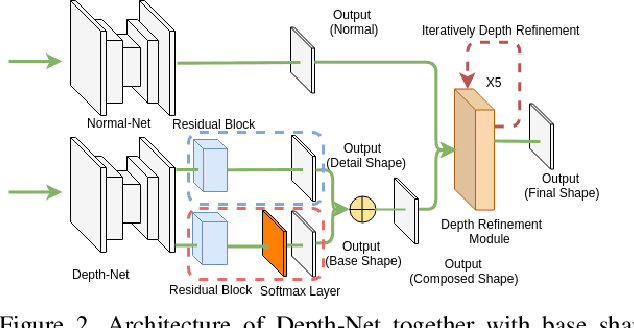
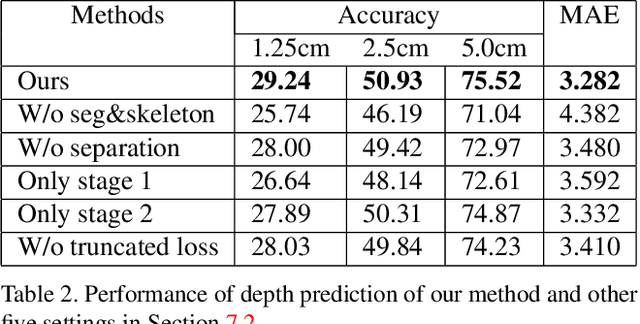
This paper presents a neural network to estimate a detailed depth map of the foreground human in a single RGB image. The result captures geometry details such as cloth wrinkles, which are important in visualization applications. To achieve this goal, we separate the depth map into a smooth base shape and a residual detail shape and design a network with two branches to regress them respectively. We design a training strategy to ensure both base and detail shapes can be faithfully learned by the corresponding network branches. Furthermore, we introduce a novel network layer to fuse a rough depth map and surface normals to further improve the final result. Quantitative comparison with fused `ground truth' captured by real depth cameras and qualitative examples on unconstrained Internet images demonstrate the strength of the proposed method.