 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular 3D Object Detection with Bounding Box Denoising in 3D by Perceiver
Apr 03, 2023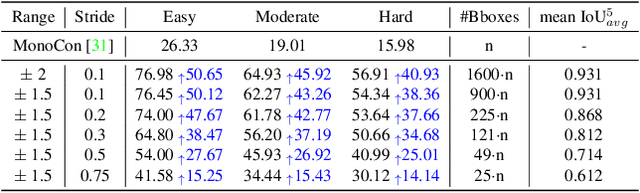
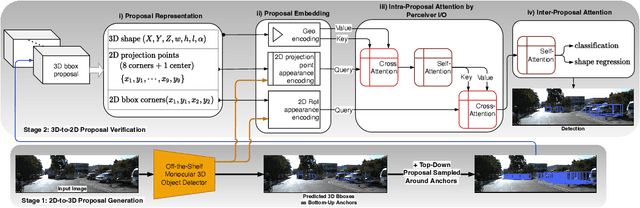

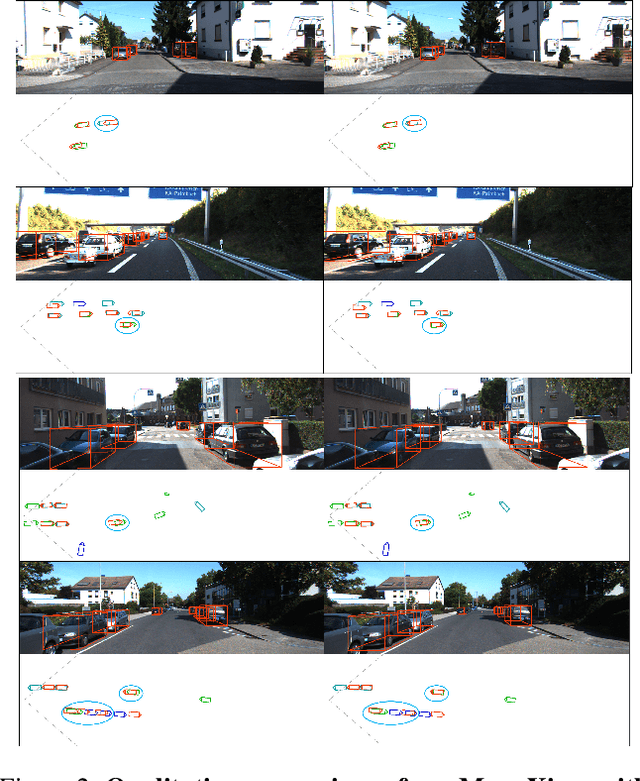
The main challenge of monocular 3D object detection is the accurate localization of 3D center. Motivated by a new and strong observation that this challenge can be remedied by a 3D-space local-grid search scheme in an ideal case, we propose a stage-wise approach, which combines the information flow from 2D-to-3D (3D bounding box proposal generation with a single 2D image) and 3D-to-2D (proposal verification by denoising with 3D-to-2D contexts) in a top-down manner. Specifically, we first obtain initial proposals from off-the-shelf backbone monocular 3D detectors. Then, we generate a 3D anchor space by local-grid sampling from the initial proposals. Finally, we perform 3D bounding box denoising at the 3D-to-2D proposal verification stage. To effectively learn discriminative features for denoising highly overlapped proposals, this paper presents a method of using the Perceiver I/O model to fuse the 3D-to-2D geometric information and the 2D appearance information. With the encoded latent representation of a proposal, the verification head is implemented with a self-attention module. Our method, named as MonoXiver, is generic and can be easily adapted to any backbone monocular 3D detectors. Experimental results on the well-established KITTI dataset and the challenging large-scale Waymo dataset show that MonoXiver consistently achieves improvement with limited computation overhead.
Towards Adversarially Robust and Domain Generalizable Stereo Matching by Rethinking DNN Feature Backbones
Jul 31, 2021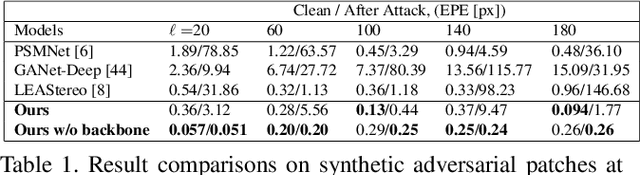
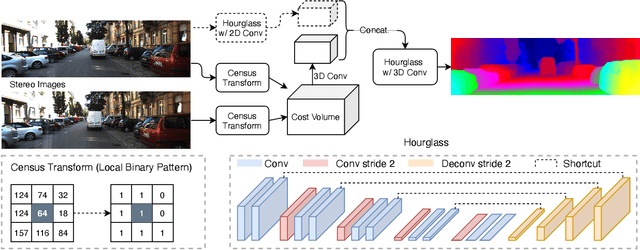
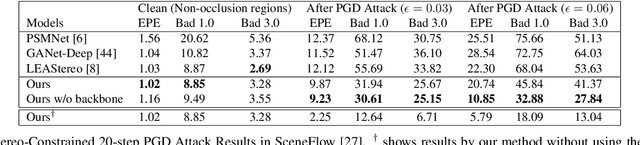
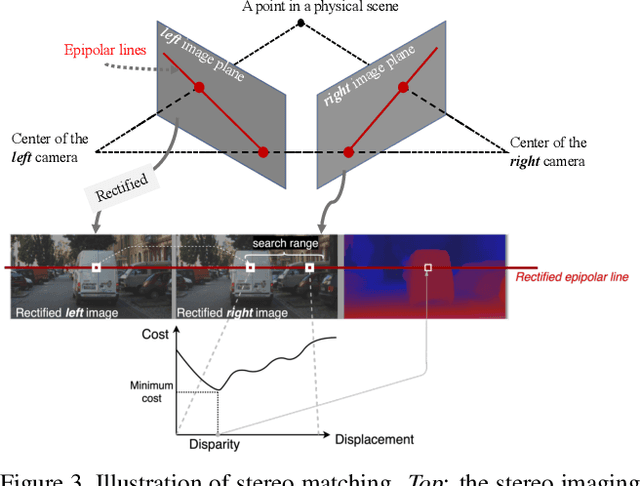
Stereo matching has recently witnessed remarkable progress using Deep Neural Networks (DNNs). But, how robust are they? Although it has been well-known that DNNs often suffer from adversarial vulnerability with a catastrophic drop in performance, the situation is even worse in stereo matching. This paper first shows that a type of weak white-box attacks can fail state-of-the-art methods. The attack is learned by a proposed stereo-constrained projected gradient descent (PGD) method in stereo matching. This observation raises serious concerns for the deployment of DNN-based stereo matching. Parallel to the adversarial vulnerability, DNN-based stereo matching is typically trained under the so-called simulation to reality pipeline, and thus domain generalizability is an important problem. This paper proposes to rethink the learnable DNN-based feature backbone towards adversarially-robust and domain generalizable stereo matching, either by completely removing it or by applying it only to the left reference image. It computes the matching cost volume using the classic multi-scale census transform (i.e., local binary pattern) of the raw input stereo images, followed by a stacked Hourglass head sub-network solving the matching problem. In experiments, the proposed method is tested in the SceneFlow dataset and the KITTI2015 benchmark. It significantly improves the adversarial robustness, while retaining accuracy performance comparable to state-of-the-art methods. It also shows better generalizability from simulation (SceneFlow) to real (KITTI) datasets when no fine-tuning is used.
A Neural Network for Detailed Human Depth Estimation from a Single Image
Oct 03, 2019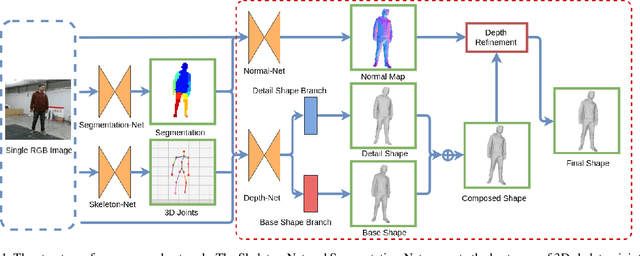
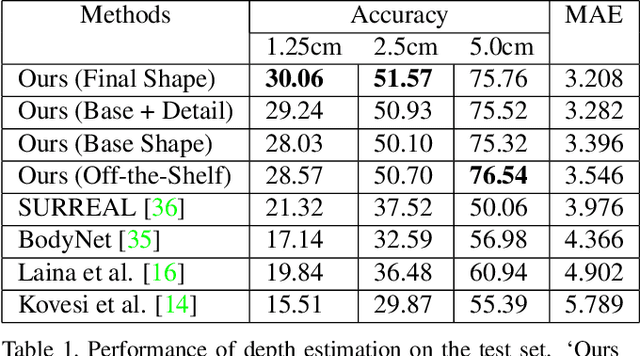
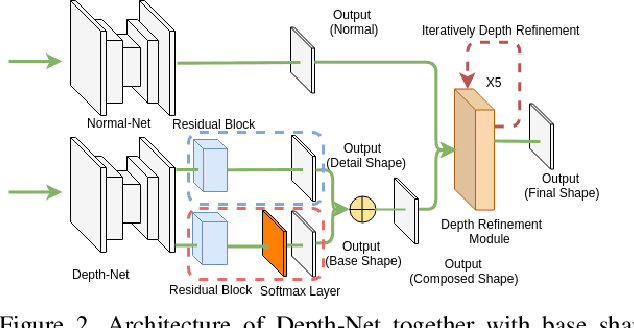
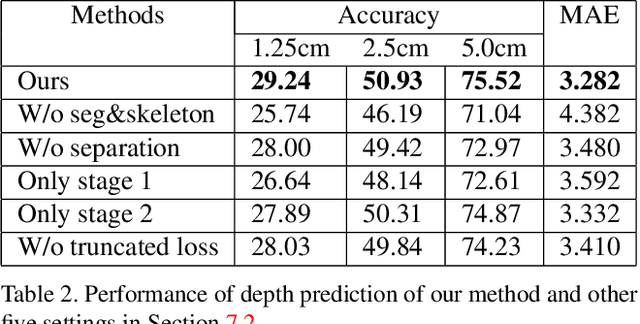
This paper presents a neural network to estimate a detailed depth map of the foreground human in a single RGB image. The result captures geometry details such as cloth wrinkles, which are important in visualization applications. To achieve this goal, we separate the depth map into a smooth base shape and a residual detail shape and design a network with two branches to regress them respectively. We design a training strategy to ensure both base and detail shapes can be faithfully learned by the corresponding network branches. Furthermore, we introduce a novel network layer to fuse a rough depth map and surface normals to further improve the final result. Quantitative comparison with fused `ground truth' captured by real depth cameras and qualitative examples on unconstrained Internet images demonstrate the strength of the proposed method.