 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular 3D Object Detection with Bounding Box Denoising in 3D by Perceiver
Paper and Code
Apr 03, 2023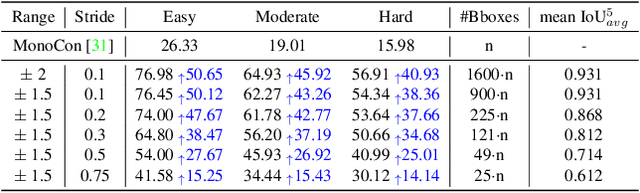
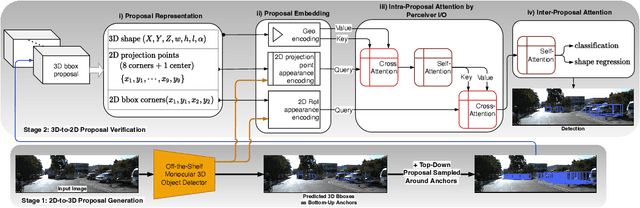

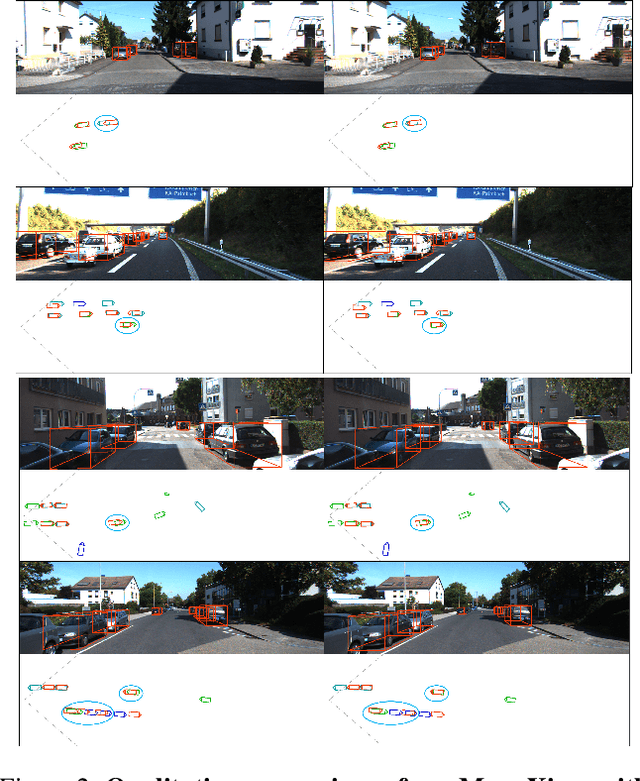
The main challenge of monocular 3D object detection is the accurate localization of 3D center. Motivated by a new and strong observation that this challenge can be remedied by a 3D-space local-grid search scheme in an ideal case, we propose a stage-wise approach, which combines the information flow from 2D-to-3D (3D bounding box proposal generation with a single 2D image) and 3D-to-2D (proposal verification by denoising with 3D-to-2D contexts) in a top-down manner. Specifically, we first obtain initial proposals from off-the-shelf backbone monocular 3D detectors. Then, we generate a 3D anchor space by local-grid sampling from the initial proposals. Finally, we perform 3D bounding box denoising at the 3D-to-2D proposal verification stage. To effectively learn discriminative features for denoising highly overlapped proposals, this paper presents a method of using the Perceiver I/O model to fuse the 3D-to-2D geometric information and the 2D appearance information. With the encoded latent representation of a proposal, the verification head is implemented with a self-attention module. Our method, named as MonoXiver, is generic and can be easily adapted to any backbone monocular 3D detectors. Experimental results on the well-established KITTI dataset and the challenging large-scale Waymo dataset show that MonoXiver consistently achieves improvement with limited computation overhead.