 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Neural Memory Network for Low Latency Event Processing
May 29, 2023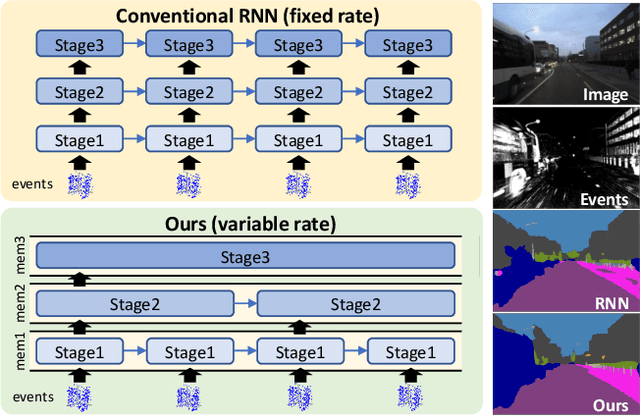



This paper proposes a low latency neural network architecture for event-based dense prediction tasks. Conventional architectures encode entire scene contents at a fixed rate regardless of their temporal characteristics. Instead, the proposed network encodes contents at a proper temporal scale depending on its movement speed. We achieve this by constructing temporal hierarchy using stacked latent memories that operate at different rates. Given low latency event steams, the multi-level memories gradually extract dynamic to static scene contents by propagating information from the fast to the slow memory modules. The architecture not only reduces the redundancy of conventional architectures but also exploits long-term dependencies. Furthermore, an attention-based event representation efficiently encodes sparse event streams into the memory cells. We conduct extensive evaluations on three event-based dense prediction tasks, where the proposed approach outperforms the existing methods on accuracy and latency, while demonstrating effective event and image fusion capabilities. The code is available at https://hamarh.github.io/hmnet/
Heterogeneous Grid Convolution for Adaptive, Efficient, and Controllable Computation
Apr 22, 2021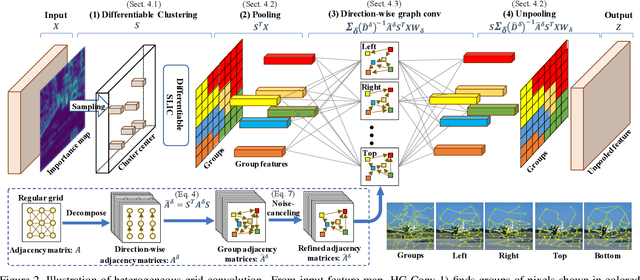
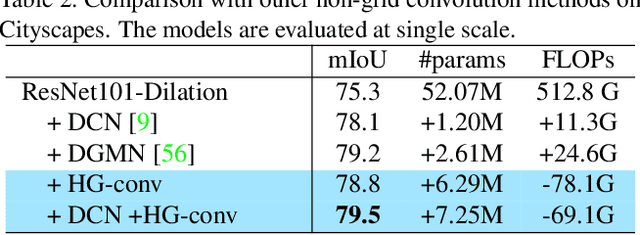

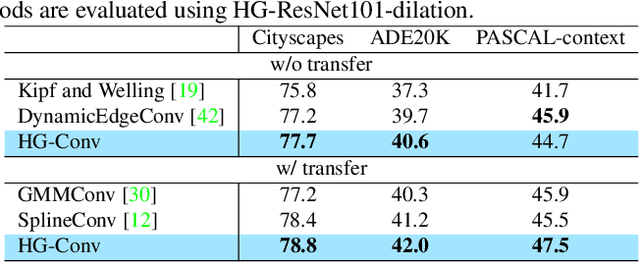
This paper proposes a novel heterogeneous grid convolution that builds a graph-based image representation by exploiting heterogeneity in the image content, enabling adaptive, efficient, and controllable computations in a convolutional architecture. More concretely, the approach builds a data-adaptive graph structure from a convolutional layer by a differentiable clustering method, pools features to the graph, performs a novel direction-aware graph convolution, and unpool features back to the convolutional layer. By using the developed module, the paper proposes heterogeneous grid convolutional networks, highly efficient yet strong extension of existing architectures. We have evaluated the proposed approach on four image understanding tasks, semantic segmentation, object localization, road extraction, and salient object detection. The proposed method is effective on three of the four tasks. Especially, the method outperforms a strong baseline with more than 90% reduction in floating-point operations for semantic segmentation, and achieves the state-of-the-art result for road extraction. We will share our code, model, and data.
Epipolar-Guided Deep Object Matching for Scene Change Detection
Jul 30, 2020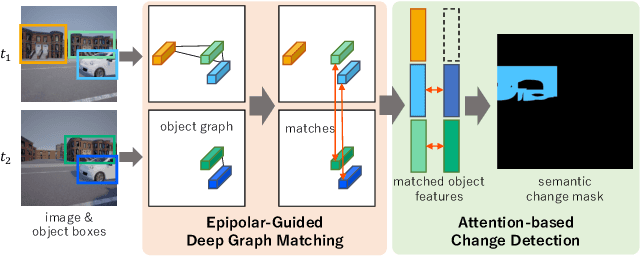
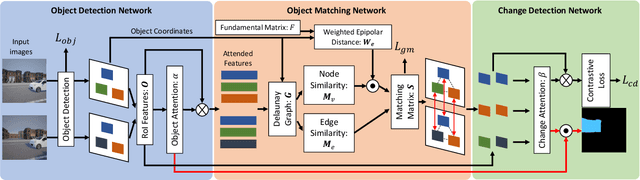
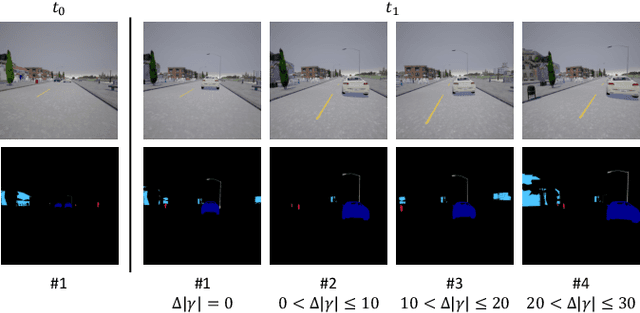

This paper describes a viewpoint-robust object-based change detection network (OBJ-CDNet). Mobile cameras such as drive recorders capture images from different viewpoints each time due to differences in camera trajectory and shutter timing. However, previous methods for pixel-wise change detection are vulnerable to the viewpoint differences because they assume aligned image pairs as inputs. To cope with the difficulty, we introduce a deep graph matching network that establishes object correspondence between an image pair. The introduction enables us to detect object-wise scene changes without precise image alignment. For more accurate object matching, we propose an epipolar-guided deep graph matching network (EGMNet), which incorporates the epipolar constraint into the deep graph matching layer used in OBJCDNet. To evaluate our network's robustness against viewpoint differences, we created synthetic and real datasets for scene change detection from an image pair. The experimental results verified the effectiveness of our network.
Rare Event Detection using Disentangled Representation Learning
Dec 04, 2018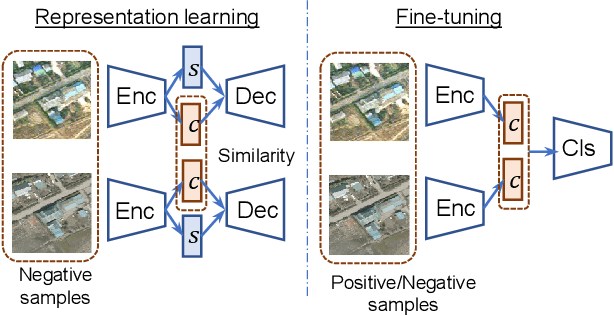
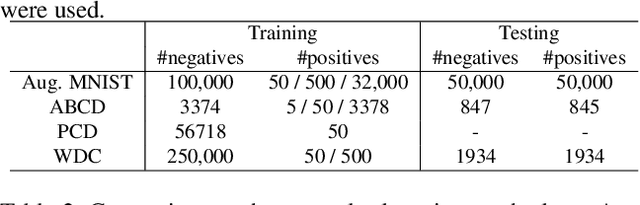
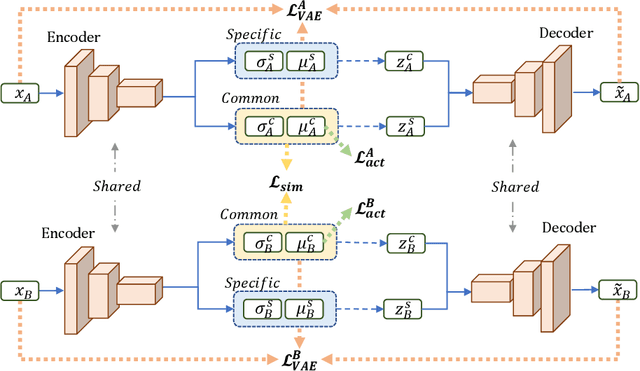
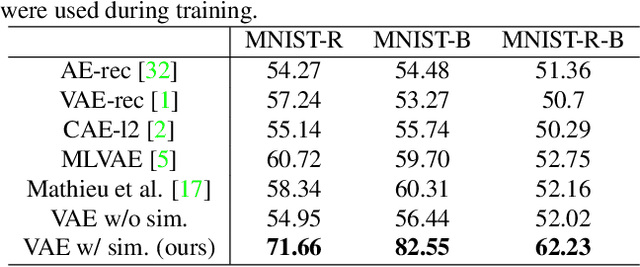
This paper presents a novel method for rare event detection from an image pair with class-imbalanced datasets. A straightforward approach for event detection tasks is to train a detection network from a large-scale dataset in an end-to-end manner. However, in many applications such as building change detection on satellite images, few positive samples are available for the training. Moreover, scene image pairs contain many trivial events, such as in illumination changes or background motions. These many trivial events and the class imbalance problem lead to false alarms for rare event detection. In order to overcome these difficulties, we propose a novel method to learn disentangled representations from only low-cost negative samples. The proposed method disentangles different aspects in a pair of observations: variant and invariant factors that represent trivial events and image contents, respectively. The effectiveness of the proposed approach is verified by the quantitative evaluations on four change detection datasets, and the qualitative analysis shows that the proposed method can acquire the representations that disentangle rare events from trivial ones.